从线性回归到无监督学习,数据科学家需要掌握的十大统
不管你对数据科学持什么态度,都不可能忽略分析、组织和梳理数据的重要性。Glassdoor 网站根据大量雇主和员工的反馈数据制作了「美国最好的
25
个职位」榜单,其中第一名就是数据科学家。尽管排名已经顶尖了,但数据科学家的工作内容一定不会就此止步。随着深度学习等技术越来越普遍、深度学习等热门领域越来越受到研究者和工程师以及雇佣他们的企业的关注,数据科学家继续走在创新和技术进步的前沿。
尽管具备强大的编程能力非常重要,但数据科学不全关于软件工程(实际上,只要熟悉 Python
就足以满足编程的需求)。数据科学家需要同时具备编程、统计学和批判思维能力。正如 Josh Wills
所说:「数据科学家比程序员擅长统计学,比统计学家擅长编程。」我自己认识很多软件工程师希望转型成为数据科学家,但是他们盲目地使用
TensorFlow 或 Apache Spark
等机器学习框架处理数据,而没有全面理解其背后的统计学理论知识。因此他们需要系统地研究统计机器学习,该学科脱胎于统计学和泛函分析,并结合了信息论、最优化理论和线性代数等多门学科。
为什么学习统计学习?理解不同技术背后的理念非常重要,它可以帮助你了解如何使用以及什么时候使用。同时,准确评估一种方法的性能也非常重要,因为它能告诉我们某种方法在特定问题上的表现。此外,统计学习也是一个很有意思的研究领域,在科学、工业和金融领域都有重要的应用。最后,统计学习是训练现代数据科学家的基础组成部分。统计学习方法的经典研究主题包括:
线性回归模型
感知机
k 近邻法
朴素贝叶斯法
决策树
Logistic 回归于最大熵模型
支持向量机
提升方法
EM 算法
隐马尔可夫模型
条件随机场
之后我将介绍 10 项统计技术,帮助数据科学家更加高效地处理大数据集的统计技术。在此之前,我想先厘清统计学习和机器学习的区别:
机器学习是偏向人工智能的分支。
统计学习方法是偏向统计学的分支。
机器学习更侧重大规模应用和预测准确率。
统计学系侧重模型及其可解释性,以及精度和不确定性。
二者之间的区别越来越模糊。
1. 线性回归
在统计学中,线性回归通过拟合因变量和自变量之间的最佳线性关系来预测目标变量。最佳拟合通过尽量缩小预测的线性表达式和实际观察结果间的距离总和来实现。没有其他位置比该形状生成的错误更少,从这个角度来看,该形状的拟合是「最佳」。线性回归的两个主要类型是简单线性回归和多元线性回归。
简单线性回归使用一个自变量通过拟合最佳线性关系来预测因变量的变化情况。多元线性回归使用多个自变量通过拟合最佳线性关系来预测因变量的变化趋势。
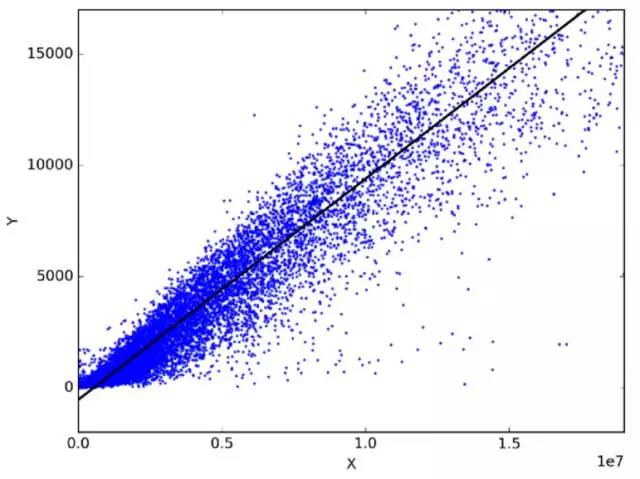
任意选择两个日常使用且相关的物体。比如,我有过去三年月支出、月收入和每月旅行次数的数据。现在我需要回答以下问题:
我下一年月支出是多少?
哪个因素(月收入或每月旅行次数)在决定月支出方面更重要?
月收入和每月旅行次数与月支出之间是什么关系?
2. 分类
分类是一种数据挖掘技术,为数据分配类别以帮助进行更准确的预测和分析。分类是一种高效分析大型数据集的方法,两种主要的分类技术是:logistic 回归和判别分析(Discriminant Analysis)。
logistic 回归是适合在因变量为二元类别的回归分析。和所有回归分析一样,logistic 回归是一种预测性分析。logistic
回归用于描述数据,并解释二元因变量和一或多个描述事物特征的自变量之间的关系。logistic 回归可以检测的问题类型如下:
体重每超出标准体重一磅或每天每抽一包烟对得肺癌概率(是或否)的影响。
卡路里摄入、脂肪摄入和年龄对心脏病是否有影响(是或否)?
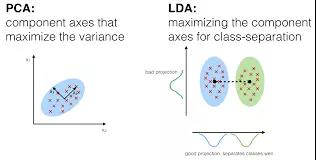
在判别分析中,两个或多个集合和簇等可作为先验类别,然后根据度量的特征把一个或多个新的观察结果分类成已知的类别。判别分析对每个对应类中的预测器分布
X 分别进行建模,然后使用贝叶斯定理将其转换成根据 X 的值评估对应类别的概率。此类模型可以是线性判别分析(Linear
Discriminant Analysis),也可以是二次判别分析(Quadratic Discriminant Analysis)。
线性判别分析(LDA):为每个观察结果计算「判别值」来对它所处的响应变量类进行分类。这些分值可以通过找到自变量的线性连接来获得。它假设每个类别的观察结果都从多变量高斯分布中获取,预测器变量的协方差在响应变量 Y 的所有 k 级别中都很普遍。
二次判别分析(QDA):提供另外一种方法。和 LDA 类似,QDA 假设 Y 每个类别的观察结果都从高斯分布中获取。但是,与 LDA 不同的是,QDA 假设每个类别具备自己的协方差矩阵。也就是说,预测器变量在 Y 的所有 k 级别中不是普遍的。
3. 重采样方法
重采样方法(Resampling)包括从原始数据样本中提取重复样本。这是一种统计推断的非参数方法。即,重采样不使用通用分布来逼近地计算概率 p 的值。
重采样基于实际数据生成一个独特的采样分布。它使用经验性方法,而不是分析方法,来生成该采样分布。重采样基于数据所有可能结果的无偏样本获取无偏估计。为了理解重采样的概念,你应该先了解自助法(Bootstrapping)和交叉验证(Cross-Validation):
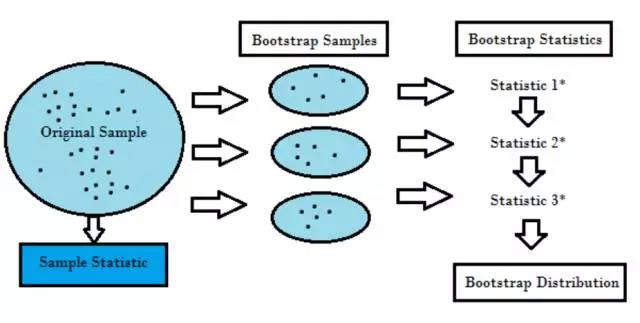
自助法(Bootstrapping)适用于多种情况,如验证预测性模型的性能、集成方法、偏差估计和模型方差。它通过在原始数据中执行有放回取样而进行数据采样,使用「未被选中」的数据点作为测试样例。我们可以多次执行该操作,然后计算平均值作为模型性能的估计。
交叉验证用于验证模型性能,通过将训练数据分成 k 部分来执行。我们将 k-1 部分作为训练集,「留出」的部分作为测试集。将该步骤重复 k 次,最后取 k 次分值的平均值作为性能估计。
通常对于线性模型而言,普通最小二乘法是拟合数据时主要的标准。下面 3 个方法可以提供更好的预测准确率和模型可解释性。
4. 子集选择
该方法将挑选 p 个预测因子的一个子集,并且我们相信该子集和所需要解决的问题十分相关,然后我们就能使用该子集特征和最小二乘法拟合模型。
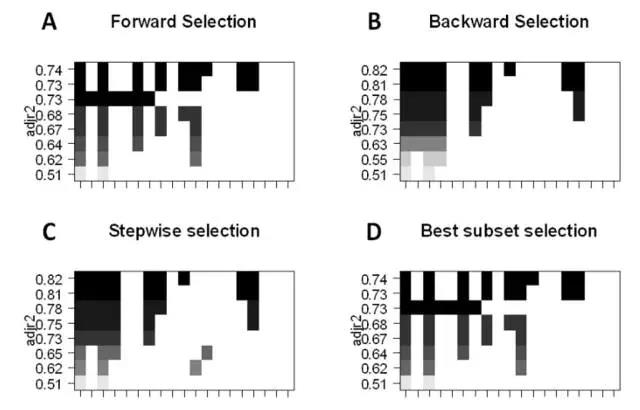
最佳子集的选择:我们可以为 p 个预测因子的每个组合拟合单独的 OLS 回归,然后再考察各模型拟合的情况。该算法分为两个阶段:(1)拟合包含
k 个预测因子的所有模型,其中 k
为模型的最大长度;(2)使用交叉验证预测损失选择单个模型。使用验证或测试误差十分重要,且不能简单地使用训练误差评估模型的拟合情况,这因为 RSS
和 R^2 随变量的增加而单调递增。最好的方法就是通过测试集中最高的 R^2 和最低的 RSS 来交叉验证地选择模型。
前向逐步地选择会考虑 p
个预测因子的一个较小子集。它从不含预测因子的模型开始,逐步地添加预测因子到模型中,直到所有预测因子都包含在模型。添加预测因子的顺序是根据不同变量对模型拟合性能提升的程度来确定的,我们会添加变量直到再没有预测因子能在交叉验证误差中提升模型。
后向逐步选择先从模型中所有 p 预测器开始,然后迭代地移除用处最小的预测器,每次移除一个。
混合法遵循前向逐步方法,但是在添加每个新变量之后,该方法可能还会移除对模型拟合无用的变量。
5. Shrinkage
这种方法涉及到使用所有 p
个预测因子进行建模,然而,估计预测因子重要性的系数将根据最小二乘误差向零收缩。这种收缩也称之为正则化,它旨在减少方差以防止模型的过拟合。由于我们使用不同的收缩方法,有一些变量的估计将归零。因此这种方法也能执行变量的选择,将变量收缩为零最常见的技术就是
Ridge 回归和 Lasso 回归。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330