相信很多做数据分析的小伙伴,都接到过一些高阶的数据分析需求,实现的过程需要用到一些数据获取,数据清洗转换,建模方法等,这里面不仅要用到python,还要用到数据分析的方法论,对于只用过excel的同学来说,这无疑是太难了,事到临头,再重头去学,无疑是个很漫长的过程,而我正好又懒癌复发了……。

不要急,下面就给大家介绍一款工具,可以通过自然语言的方式,把你的分析需求告诉它,它就能帮你实现代码的生成,数据分析方法的运用。它就是字节跳动最新发布的一款工具—Trae。
Trae是一款AI与传统IDE结合的工具,可以根据使用自然语言提出的需求,自动转化成代码后执行,实现需求-结果之间的零技术门槛的跨越。

下面我们先介绍一下它的安装部署
一、下载并安装Trae。
1、下载trae,官方网址为:www.trae.com.cn
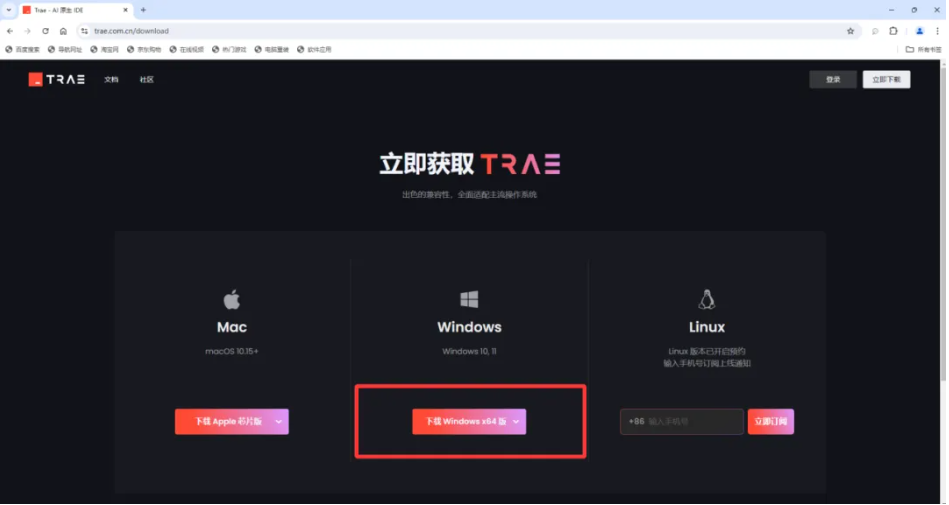
2、安装只需要下一步and下一步
二、配置Python环境
1、当系统中未安装python解释器时
1)请先安装python解释器及开发工具后,再安装配置trae,因为单独安装python解释器和开发工具,过程比较繁琐,建议安装anaconda进行傻瓜式安装,具体可参考如下链接
anaconda安装过程:https://blog.csdn.net/yoggieCDA/article/details/147205853
2)跳过注册过程
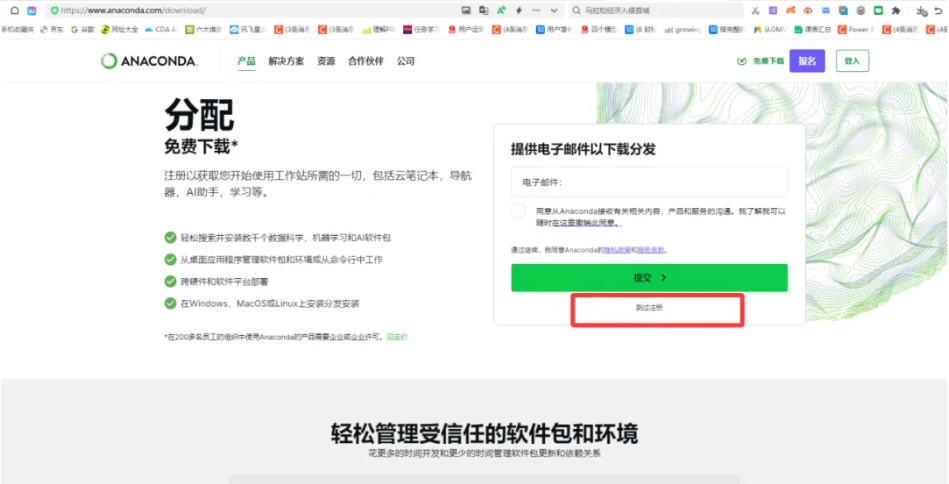
3)下载anaconda安装包
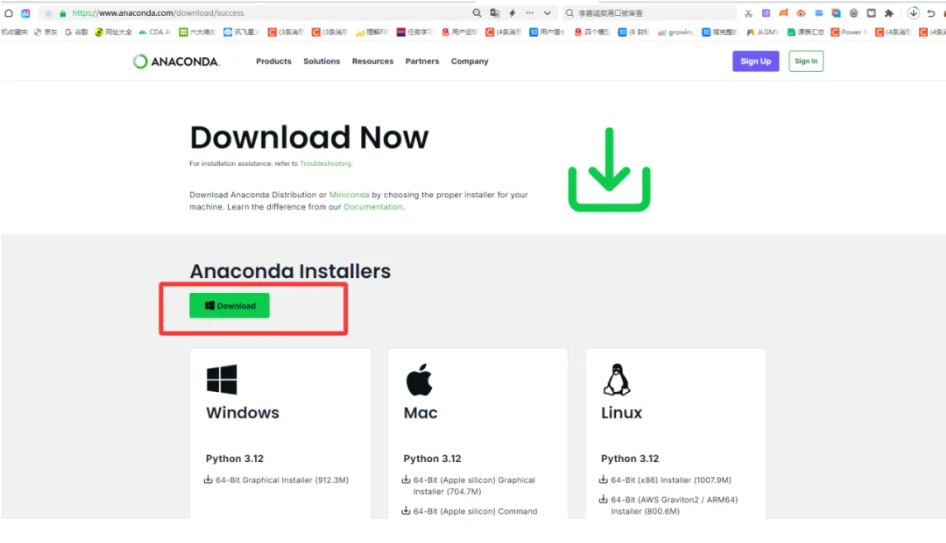
4)参考如下链接,进行anaconda安装:
https://blog.csdn.net/yoggieCDA/article/details/147205853
2、当系统中已经安装python解释器时
1)在Builder模式下,输入提示词:配置python环境。

2)选择一个文件夹,以用来存放项目文件
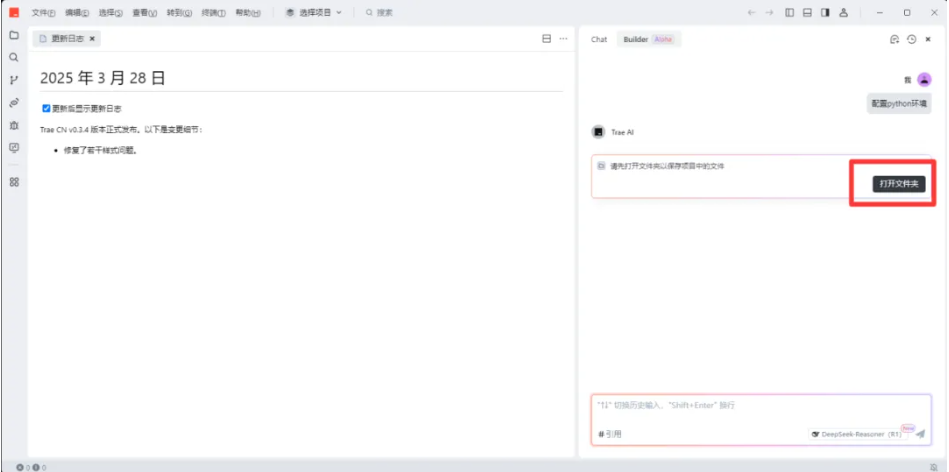
3)配置虚拟环境
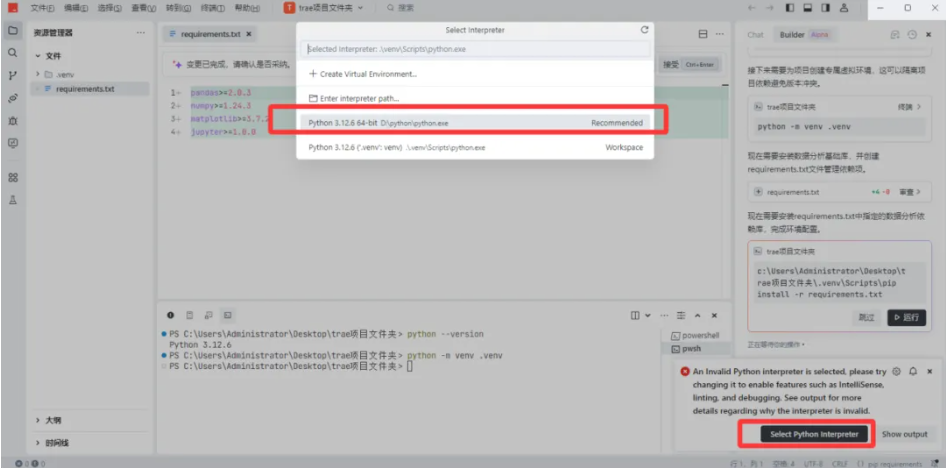
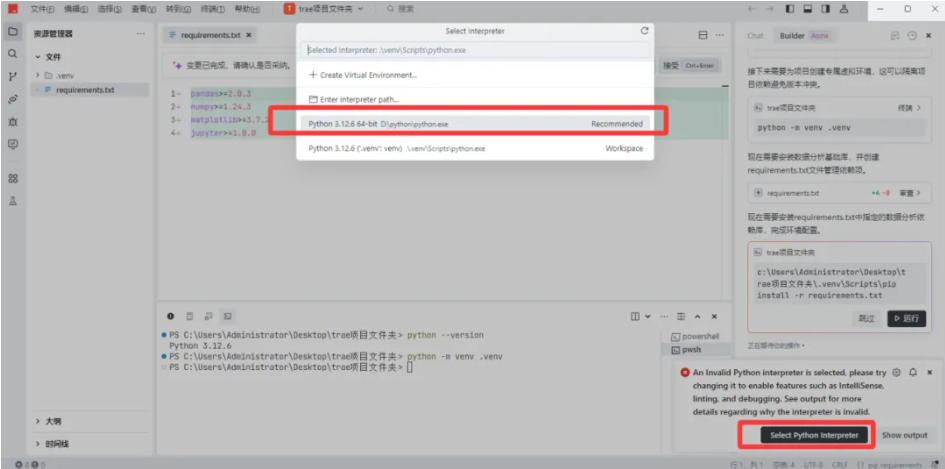
4)如出现以下提示,请按标识进行操作,选择安装好的python解释器
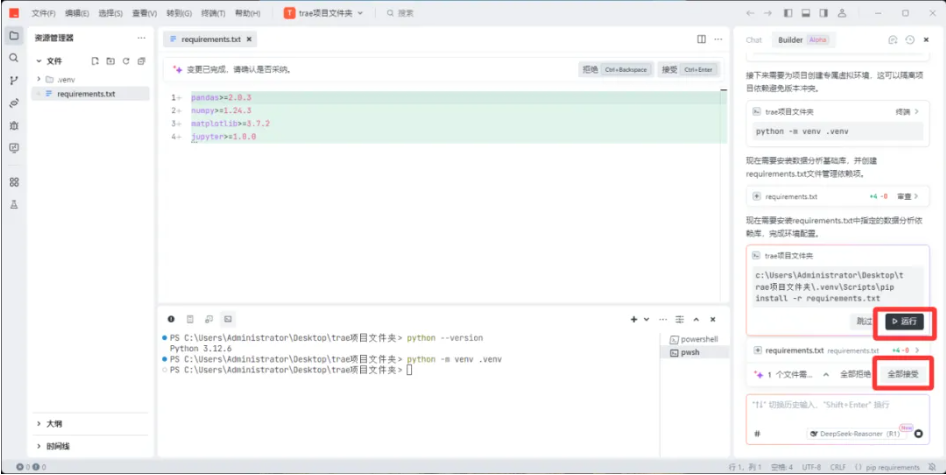
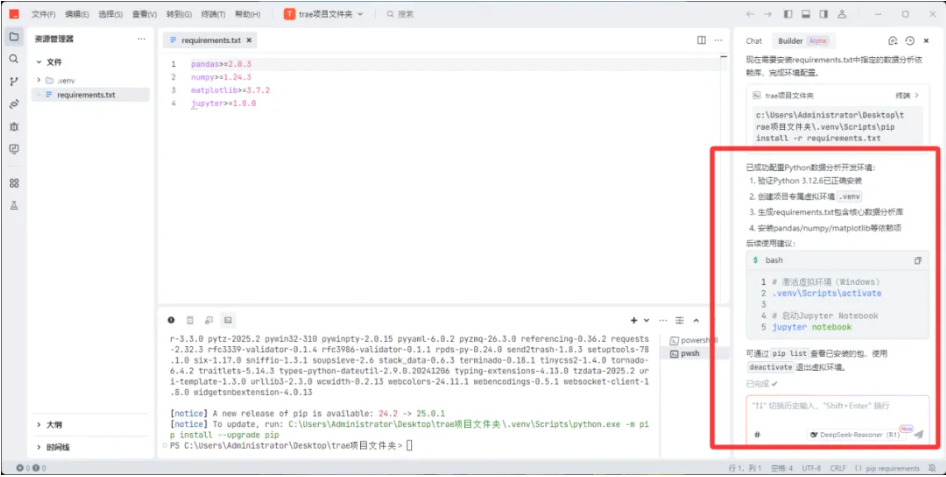
5)在提示词输入框中,输入:“激活虚拟环境”并回车执行
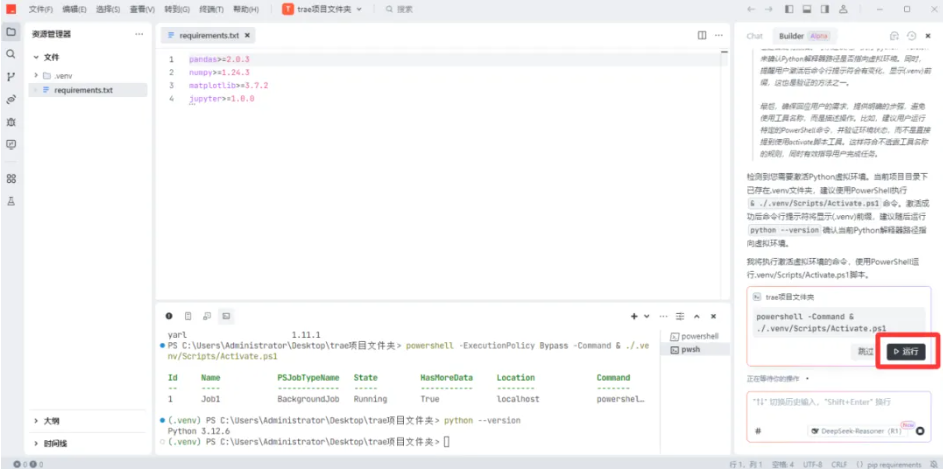

6)安装python开发工具及数据分析相关的包
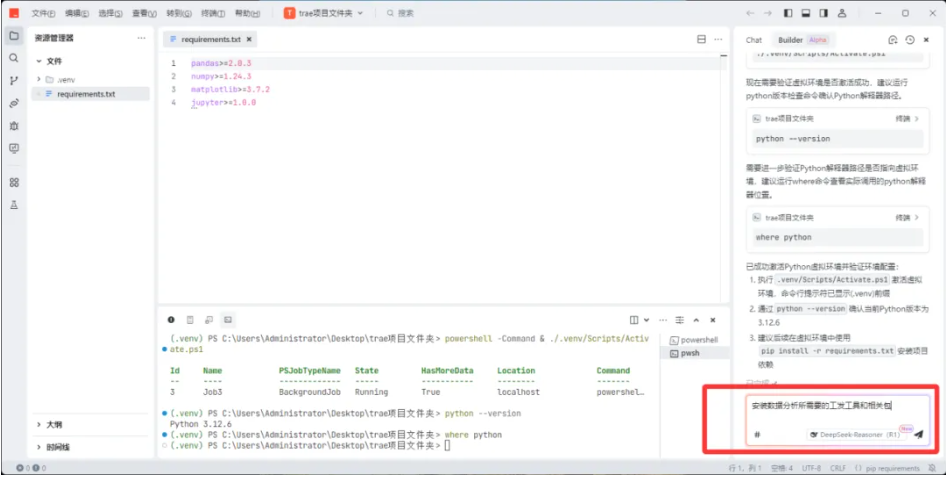
7)环境配置成功
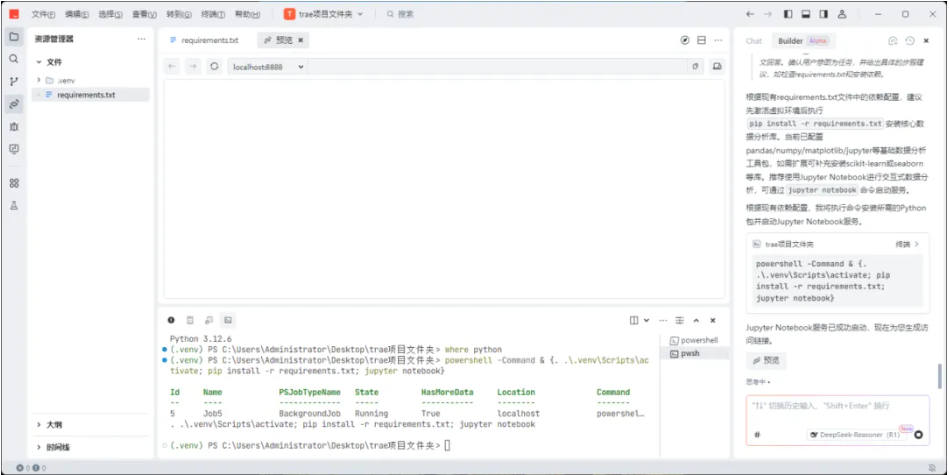
完成配置成功以后,让我们小试牛刀吧,
下面我们将用两个案例来带领大家快速上手这款工具。
三、 用Trae实现EXCEL数据整合
数据分析工作中,常常会遇到多表合并为一张表的情况,如历年的销售数据,各月份的销售数据等,以往多张表的合并,要在python中实现,需要大家编写代码,有一定的编程基础。
现有如下几张数据表,记录了不同年份,不同区域市场的销售金额及利润情况,现需要多张表合并为一张表。
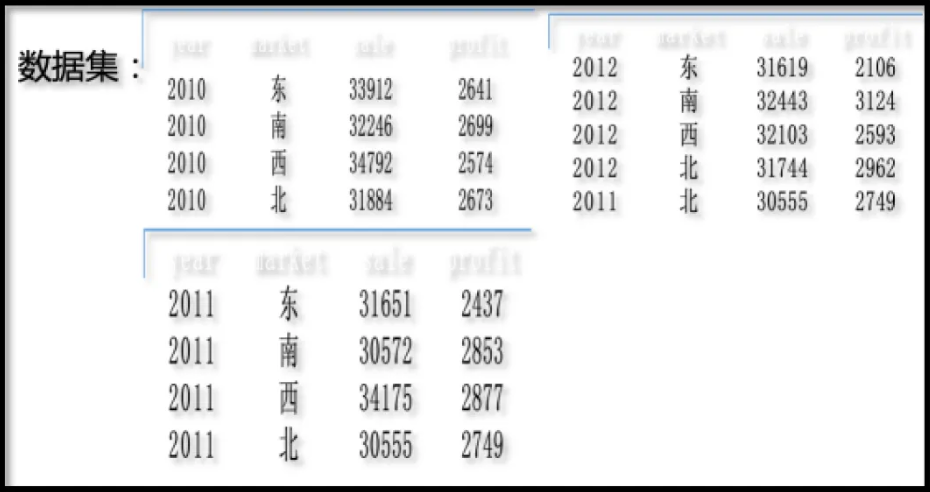
提示词:
角色:我是一名数据分析师,经常使用python做数据整合、清理和可视化问题。
背景描述:本文件夹目录下有两个子文件夹,分别是“原始数据”子文件夹和“整合数据”子文件夹。
任务:
- 1、需要把“原始数据”子文件夹中的全部数据纵向链接,然后保存到“整合数据”子文件夹中;
- 2、数据清洗,如果记录的内容完全一样,需要进行去重操作
- 3、最终整合好的数据保存在“整合数据”子文件夹的“sale_all_xxx.csv”中,其中的“xxx”代表当前系统日期和时间,精确到秒。
注意事项:
- 1、“原始数据”子文件夹中的数据有可能有中文,在读取文件数据的时候注意编码问题。
- 2、如果文件“sale_all.csv”已经存在,请先删除。
- 4、把“这个脚本实现了以下功能”放到代码头部的注释中。
执行结果:
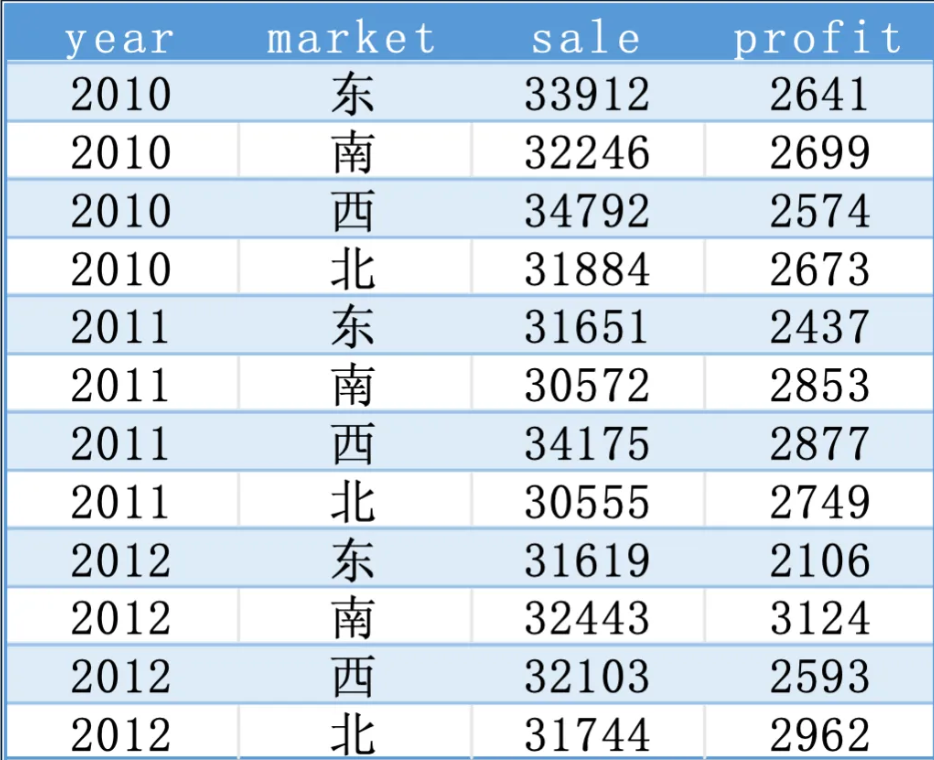
从这个案例我们可以看出数据分析的很多环节,都可以用AI来提高效率,节省你宝贵的时间和精力。大家不妨先思考这样一个问题:平时你做数据分析流程步骤是怎样的?在我看来,数据分析基本有这样5个环节:

数据分析是从明确问题和理解数据开始的,接着对数据清洗,比如说处理缺失值、调整数据格式等等,然后使用合适的数据分析方法,对数据展开分析,最后将数据结果进行可视化,直观的展示数据分析的结论这就是一套完整的数据分析工作流程,那么,现在AI来了以后,数据分析的这5个环节发生变化了吗?
并没有,可能分析的手法变了,比如过去清洗数据,要熟练的掌握Excel各种函数,现在可以通过提示词让AI来辅助完成。但是,数据分析的这5个环节一个也没少,所以大家不要只热衷于追逐新冒出来的各种AI工具,关键是要透彻掌握数据分析的底层逻辑。CDA数据分析师一级里讲解了数据分析方法、基本的流程、业务数据分析等。
四、用Trae实现业绩数据预测
再举个例子,某行信用卡中心需根据资金使用情况,进行资金使用量的预测,以提前准备适当的现金,以往的资金预测需要使用python进行,会用到建模等方法,现有了AI,请尝试使用AI辅助相应技术的实现。
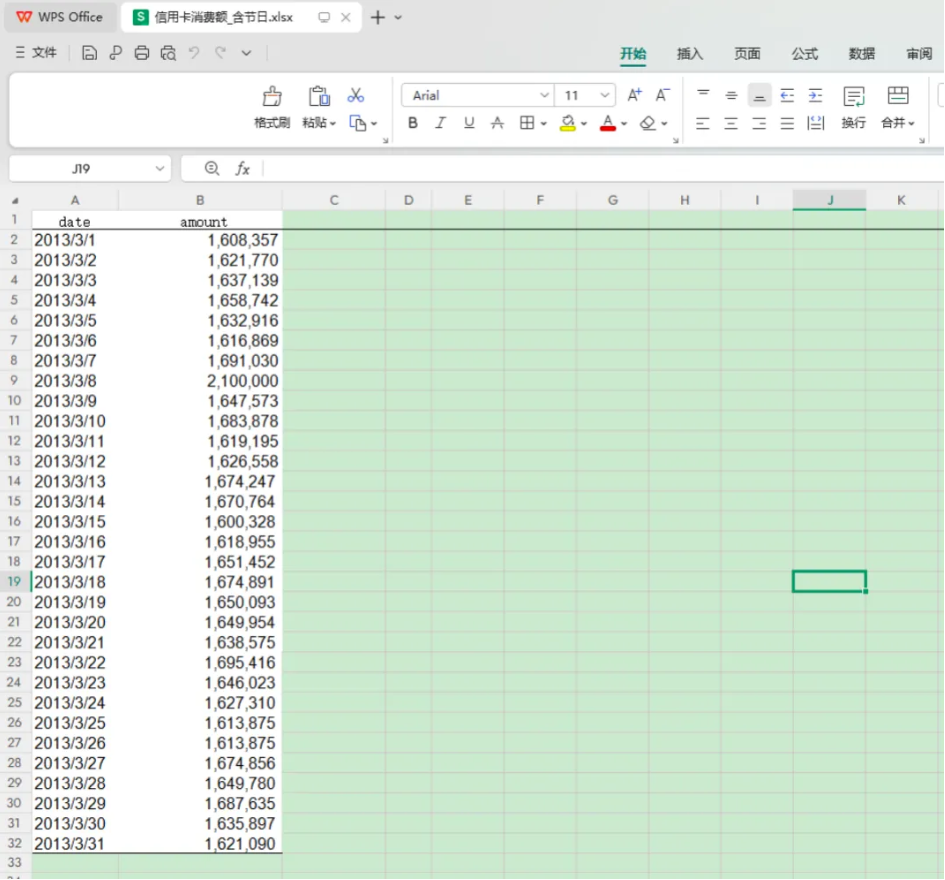
提示词:
我是一名数据分析师,经常使用python做数据整合、清理、可视化、时间序列分析、数据挖掘的问题。
背景描述:本文件夹目录下有一个“信用卡消费额_含节日.xlsx”文件。
任务:
- 读入数据,判断那个变量是时期变量,那个变量是业务数据,并对数据按照时间进行可视化展现;
- 数据清洗,数据中有可能有噪音或缺失值;如果是缺失值则使用移动平均的填补方法;如果是噪音,则把该数据点先删去,再使用移动平均的填补方法;
- 判断该数据有没有季节效应,如果有,可以使用SARIMA或LSTM算法建模,只需要使用一个算法建模即可;
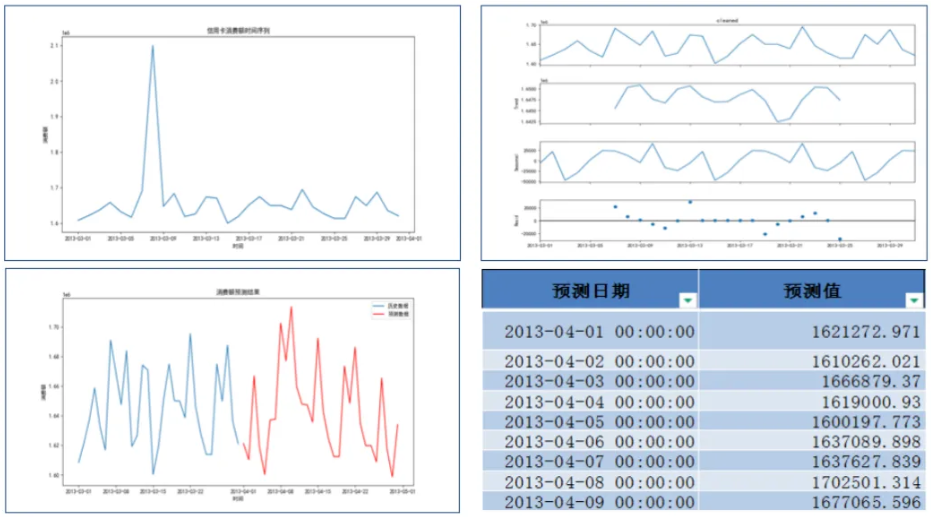
- 使用模型做未来一个月的数据预测,保存在“pred.xlsx”中,并做图展示。
执行结果
推荐学习书籍
《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~

免费加入阅读:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330