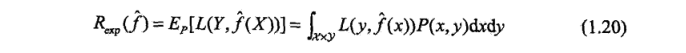
概括地说,泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为 ...
2020-07-03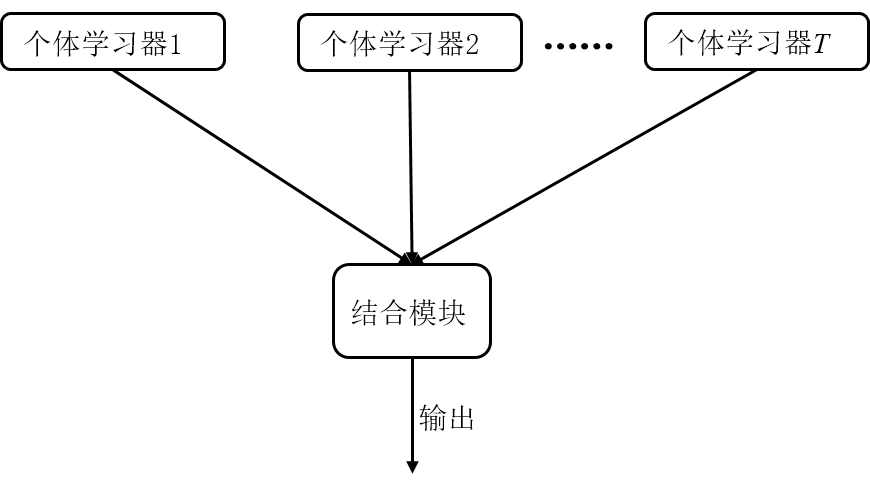
今天小编给大家带来的是现在非常火爆的机器学习方法——集成学习。集成学习,顾名思义,通过将多个单个学习器集成/组合在一起,使它们共同完成学习任务,有时也被称为“多分类器系统(multi-classifier system)”、 ...
2020-07-03
今天我们来盘点一下那些常见的机器学习中的损失函数有哪些。 用于计算损失的函数称为损失函数。模型每一次预测的好坏用损失函数来度量。机器通过损失函数进行学习,如果预测值与实际结果偏离较远,损失函数会得 ...
2020-07-03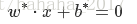
支持向量机是一种二类分类模型.它的基本模型是定义在特征空间上的间隔最大的线性分类器。其学习策略是间隔最大化,可形式化为求解凸二次规划问题,也等价于正则化的合叶损失函数的最小化问题。 支持向量机学习 ...
2020-07-03SVM和LR是机器学习中常用的算法,今天就让我们来看一下这两者有哪些相同点和不同点吧。 SVM和LR的相同点: 1.LR和SVM都是有监督的学习 2.LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在 ...
2020-07-03相信大家在机器学习中,一定常见到;SVC,NvSVC,LinearSVC,今天我们就来看看这三者的区别。 SVC(C-Support Vector Classification): 支持向量分类,基于libsvm实现的,数据拟合的时间复杂度是数据样本的二 ...
2020-07-03
支持向量机SVM(Support Vector Machine),是常见的一种判别方法。在机器学习领域,是有监督学习模型,通常用来进行模式识别、分类及回归分析,主要针对小样本数据进行学习、分类和预测,类似的根据样本进行学习的 ...
2020-07-03
在机器学习中,有成千上万甚至几十万的维度的数据需要处理,这种情况下机器学习的资源消耗是不可接受的,并且很大程度上影响着算法的复杂度,因此对数据降维是必要的。PCA(Principal Component Analysis)是一种常 ...
2020-07-03函数是组织好的,能够重复使用的,用来实现单一,或相关联功能的代码段。python提供了许多内建函数,这些函数提高了应用的模块性,和代码的重复利用率。下面是小编整理的python内建函数中的反射类,希望对各位学习 ...
2020-07-03echarts是一个纯JavaScript图表库,底层依赖于轻量级的Canvas类库ZRender(矢量图形库),基于BSD开原协议,是一款非常优秀的可视化前端框架。 优点: 1.免费商用 2.兼容当前绝大部分浏览器,包括:IE8/9/1 ...
2020-07-02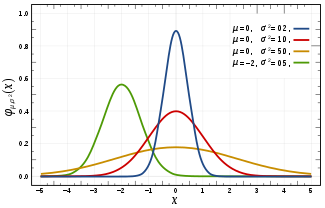
正态分布(Normal distribution)又称为高斯分布(Gaussian distribution),是统计学中一个重要且常见的连续概率分布。 特性: 1)集中性:曲线的最高峰位于正中央,且位置为均数所在的位置。 2)对称性:正态 ...
2020-07-02数据分析时,数据量大不可怕,可怕的是数据倾斜。当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。下面小编就给大家分享几种数据倾斜优化的方法,希 ...
2020-07-02文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。 文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法,主要用途 ...
2020-07-02
echarts是一个使用 JavaScript 实现的开源可视化库,因为其着良好的交互性,精巧的图表设计,受到众多开发者青睐。Python 是一门富有表达力的语言,在数据处理方面很在行。当Python数据分析遇上echarts数据可视化 ...
2020-07-02
seaborn是建立在Matplotlib基础之上的高级的API,是比Matplotlib更为高级的的一种python可视化库。专攻于统计可视化,有丰富的可视化库,包括一些复杂类型,如时间序列、联合分布图(jointplots)和小提琴图(violind ...
2020-07-02相信只要接触过python的人,对于matplotlib都很熟悉。matplotlib是一种python可视化库。 matplotlib 是一个用于创建二维图和图形的底层库,是python可视化库中规中矩的一种库,像大多数编程语言的标准库一 ...
2020-07-02Python是一款功能强大的数据分析工具,其中Python可视化功能更是受到许多数据分析师的青睐,下面小编就给大家分享一些Python可视化库,希望对各位数据分析师小伙伴有所帮助。 1.Matplotlib Matplotlib是一个 ...
2020-07-02“CDA数据分析师认证”是一套专业化,科学化,国际化,系统化的人才考核标准,分为CDA LEVELⅠ ,LEVEL Ⅱ,LEVEL Ⅲ,CDA Level II:建模分析师,专指金融、电信、零售、互联网、电商、医学等行业专门从事数据分 ...
2020-07-01在许学习贝叶斯方法的时候最常见到的就是先验概率,后验概率。下面小编简单介绍一下先验概率,希望对各位小伙伴有所帮助。 一、先验概率定义 先验概率是指根据以往经验和分析得到的概率 二、先验概率条件 ...
2020-07-01
今天小编给大家分享一下最小二乘法的一些内容。 一、最小二乘法概念 最小二乘法Least Square Method,做为分类回归算法的基础,有着悠久的历史(由马里·勒让德于1806年提出)。主要是通过最小化误差的平方以 ...
2020-07-01在使用Excel透视表进行数据汇总分析时,我们常遇到“需通过两个字段相乘得到关键指标”的场景——比如“单价×数量=金额”“销量 ...
2025-11-14在测试环境搭建、数据验证等场景中,经常需要将UAT(用户验收测试)环境的表数据同步到SIT(系统集成测试)环境,且两者表结构完 ...
2025-11-14在数据驱动的企业中,常有这样的困境:分析师提交的“万字数据报告”被束之高阁,而一张简洁的“复购率趋势图+核心策略标注”却 ...
2025-11-14在实证研究中,层次回归分析是探究“不同变量组对因变量的增量解释力”的核心方法——通过分步骤引入自变量(如先引入人口统计学 ...
2025-11-13在实时数据分析、实时业务监控等场景中,“数据新鲜度”直接决定业务价值——当电商平台需要实时统计秒杀订单量、金融系统需要实 ...
2025-11-13在数据量爆炸式增长的今天,企业对数据分析的需求已从“有没有”升级为“好不好”——不少团队陷入“数据堆砌却无洞察”“分析结 ...
2025-11-13在主成分分析(PCA)、因子分析等降维方法中,“成分得分系数矩阵” 与 “载荷矩阵” 是两个高频出现但极易混淆的核心矩阵 —— ...
2025-11-12大数据早已不是单纯的技术概念,而是渗透各行业的核心生产力。但同样是拥抱大数据,零售企业的推荐系统、制造企业的设备维护、金 ...
2025-11-12在数据驱动的时代,“数据分析” 已成为企业决策的核心支撑,但很多人对其认知仍停留在 “用 Excel 做报表”“写 SQL 查数据” ...
2025-11-12金融统计不是单纯的 “数据计算”,而是贯穿金融业务全流程的 “风险量化工具”—— 从信贷审批中的客户风险评估,到投资组合的 ...
2025-11-11这个问题很有实战价值,mtcars 数据集是多元线性回归的经典案例,通过它能清晰展现 “多变量影响分析” 的核心逻辑。核心结论是 ...
2025-11-11在数据驱动成为企业核心竞争力的今天,“不知道要什么数据”“分析结果用不上” 是企业的普遍困境 —— 业务部门说 “要提升销量 ...
2025-11-11在大模型(如 Transformer、CNN、多层感知机)的结构设计中,“每层神经元个数” 是决定模型性能与效率的关键参数 —— 个数过少 ...
2025-11-10形成购买决策的四个核心推动力的是:内在需求驱动、产品价值感知、社会环境影响、场景便捷性—— 它们从 “为什么买”“值得买吗 ...
2025-11-10在数字经济时代,“数字化转型” 已从企业的 “可选动作” 变为 “生存必需”。然而,多数企业的转型仍停留在 “上线系统、收集 ...
2025-11-10在数据分析与建模中,“显性特征”(如用户年龄、订单金额、商品类别)是直接可获取的基础数据,但真正驱动业务突破的往往是 “ ...
2025-11-07在大模型(LLM)商业化落地过程中,“结果稳定性” 是比 “单次输出质量” 更关键的指标 —— 对客服对话而言,相同问题需给出一 ...
2025-11-07在数据驱动与合规监管双重压力下,企业数据安全已从 “技术防护” 升级为 “战略刚需”—— 既要应对《个人信息保护法》《数据安 ...
2025-11-07在机器学习领域,“分类模型” 是解决 “类别预测” 问题的核心工具 —— 从 “垃圾邮件识别(是 / 否)” 到 “疾病诊断(良性 ...
2025-11-06在数据分析中,面对 “性别与购物偏好”“年龄段与消费频次”“职业与 APP 使用习惯” 这类成对的分类变量,我们常常需要回答: ...
2025-11-06





