大数据会说话,简明机器学习问题
从数据中学习究竟是什么?科学家从数据中学习,企业、政府和慈善机构也一样。事实上,无论是私人、公共的,还是慈善部门的领域,几乎没有哪个领域不在部署数据驱动的模型,以发掘和利用数据中的关系。
我们置身于数据之中,亚马逊网站每天发生2.5万次销售/交付,10万个基因几乎同时测序,超过100亿张图片存储在网页上。而大约在几个月之内,英国的国家卫生局对6000万份健康记录进行了数字化处理。我们所有人每天都在使用数据,而且许多人在工作的付薪过程中都使用了数据。营销公司的分析师必须决定,他的受众/听众选择模型需要包含哪些因素。本地卫生部门的研究人员测量季节性流感的发病率。气象学家运行气候模型,计算降水的可能性、温度的变化以及云层覆盖的百分比。
公共部门和某些公司需要将海量信息转换为可操作的战略性公共/商业决策。从数据中学习提供了一系列实践性的技术和工具,来帮助开发稳健的归纳模型,用以从数据中提取可用的见解。归纳的简单含义是指观点源于经验数据,而非根据理论第一的原则来推导。
本文的首要目标是帮助你把大量数据转化为可用的知识。为此,我们将借助理论来重塑数据科学挑战的思考方式。但是,本文不是一本专门讨论引理、证明以及抽象理论细节的教科书。它为这样的读者而准备:他们希望获得一个重要的、成功的框架,用来建立有用的预测分析模型,从而为他们工作的组织以及他们服务的客户改善运营方式和提高盈利。同时务必了解,数据科学这项职业不适合那些缺乏好奇心或者技术能力的人,任何处理实证数据的职业也同样不适合。
在本文中,你会学到归纳推理与演绎推理的关键区别,确定学习问题的三大要素,以及发现使用归纳模型的一个明确框架。
1.1 归纳推理和演绎推理的基础
图1.1围绕着假设检验,展示了归纳法和演绎法之间的一个关键区别。两种方法都始于观察有趣的现象,但归纳方法更关心选择最佳的预测模型。而演绎方法更关心探索理论,主要是结合数据来检验某个理论的假设。根据经验数据的“有分量的证据”,来判断这个假设是接受还是拒绝。
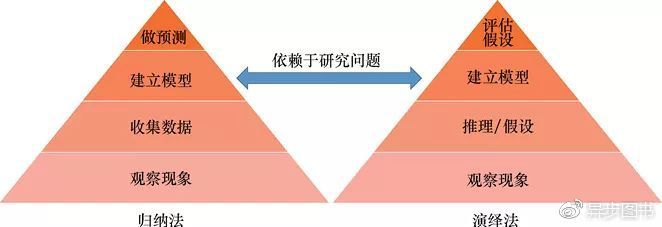
图1.1 归纳和演绎
1.1.1 你曾遇到过这些事情吗?
我想起在我听过的理论经济学课上,教授曾严厉警告:“不能信任数据。”也许,这种经历并不仅仅出现在我的课堂上。一位著名的计量经济学教授曾解释道1:“经济学中有一种普遍观点,如果当前的经验证据不可信,或经济现象无法预测,那么主要是因为经济太复杂,而且产生的数据太混乱,不适合建立统计模型。”或许,你也有过类似经历。
但是,当我离开课堂,步入了经验分析的真实世界,居然很快发现,只要给我足够的数据和适合的工具,使用数据驱动的归纳法会带给我意义重大的结论。
注意:在每个可以想到的领域——商业的、工业的以及政府的,成功的数据驱动的归纳模型都已经存在,或正在建立。数据决策的模型越来越多地用来制定决策,如可以识别你的语音的智能手机,又如实施外科手术的机器人2,再如核爆炸的检测。
1.1.2 释放归纳的力量
无论你是否在这些领域中工作,医疗诊断、手写体识别、市场、金融预测、生物信息学、经济学的领域,还是在其他任何要求经验分析的专业领域,你常常会面对这样的情况,潜在的首要原则尚未发现,或正在研究的系统过于复杂,无法通过充分详细的数学描述来提供有用的结果。我发现,数据驱动的归纳方法在以上所有情况中都有用,你也会认同这一点。
注意:在科学之外,演绎分析可能在经济学学科中占据了顶峰地位,其中大部分的焦点(甚至今天也一样)都围绕着检验和评估演绎理论的经济学有效性。事实上,经济学家对理论进行客观验证的渴望催生了新的统计学子学科—计量经济学。
1.1.3 推断的阴阳之道
尽管归纳和演绎的区别相当大,但它们实际上也可以互补使用。对于一个研究者来说,计划一个同时包含归纳元素和演绎元素的项目是非同寻常的。
如果你曾经或长或短地从事过经验建模领域的工作,那你很可能发现这种情况:你计划执行一个归纳或演绎的项目,但没想到随着时间的推移,你又发现了其他更适合的方法来阐明你的研究问题。需要牢记的是,归纳方法或演绎方法的使用,部分地依赖于你的数据分析目标。
注意:演绎推理优越性的相对下降,可以部分地由数据驱动模型的高度成功来解释。意大利学者马特奥·帕尔多(Matteo
Pardo)和乔治·斯贝沃格里尼(Giorgio
Sberveglieri)在十多年前正确地观察到6:“在当前,从遵循首要原则的经典建模到开发数据建模,发生了一种范式转换。”有趣的是,需要注意,现在数据建模者的短缺是世界性的问题7。
1.2 学习问题的三大要素
我们的讨论始于学习问题的基础。例如,有监督的分类问题,其中我们得到的数据是实值的属性—响应对(x,y)。三个元素组成了基本的学习问题。

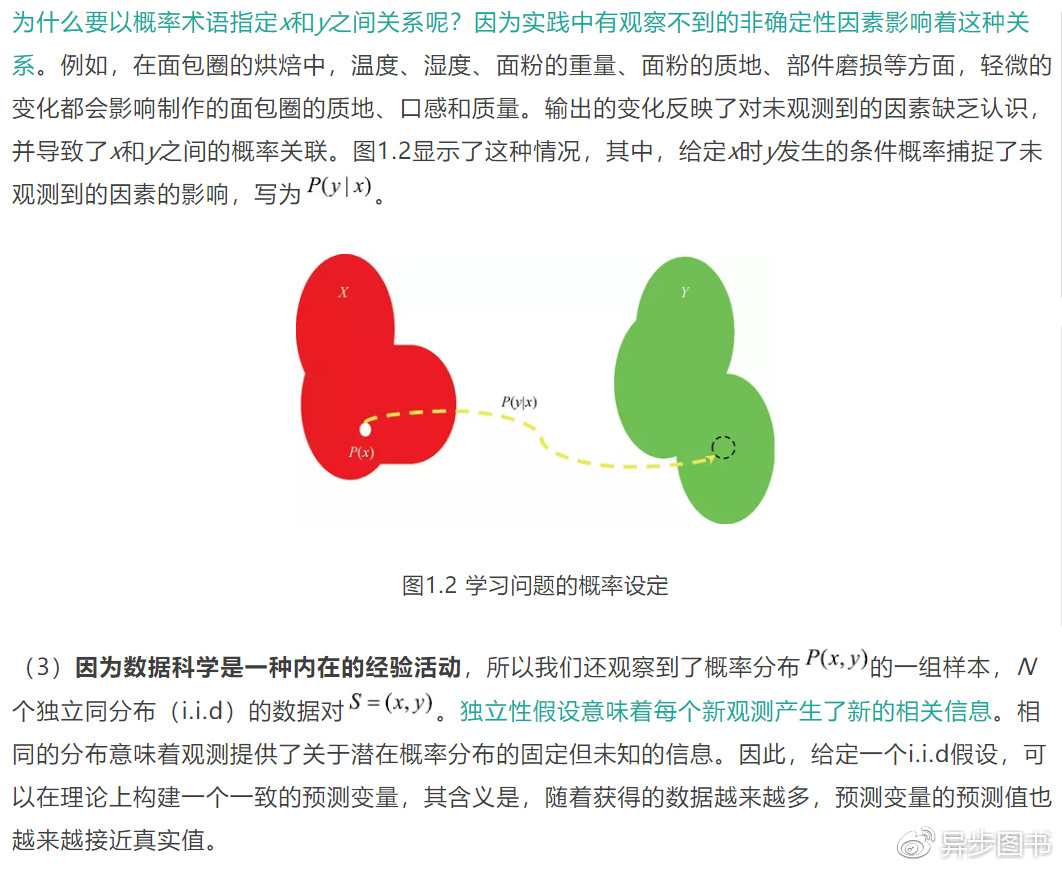
1.3 从数据中学习的目标

注意:
归纳偏置是数据科学实践中的一个关键要素,正如伦敦经济学院的Jonathan
Baxter的解释8:“在机器学习中,可能最重要的事情就是学习机器假设空间的预先偏置,它要足够小,以保证合理训练集的好的一般化(预测能力),也要足够大,这样它才能包含学习问题好的解决答案。”
1.3.1 阐明选择标准

1.3.2 学习任务的选择
现在,我们的学习框架已经准备就绪,可以把注意力转向我们作为数据科学家需要执行的真实任务。相当幸运,结果发现从数据中学习可以恰好分成3种基本类型的工作:
(1)类别决策边界的分类或估计。例如,流水线上按大小和颜色分类的鸡蛋。
(2)未知连续函数的回归或估计。例如,预测本地音乐节创造的票房平均价值。
(3)概率密度的估计。例如,估计爱尔兰沿海河流中白斑狗鱼的密度。
本文将自始至终主要讨论分类的问题,因为这是数据科学家面对的最频繁的任务。但是,我们得出的经验教训适用于所有3种类型的任务。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330