R语言基于模型的聚类方法处理
说明
与使用启发式方法而非依赖某个形式化模型的层次聚类和K均值聚类不同,基于模型的聚类算法假设存在多种数据模型,并使用EM算法来判断可能性最大的数据模型作为对数据处理进行聚簇处理的依据。
操作
使用customer数据库
mb = Mclust(customer)
fitting ...
|==============================================================================================================================| 100%
> plot(mb)
Model-based clustering plots:
1: BIC
2: classification
3: uncertainty
4: density
Selection:
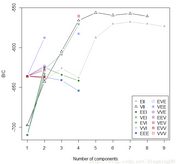
选择“1”得到不同成分的BIC值:
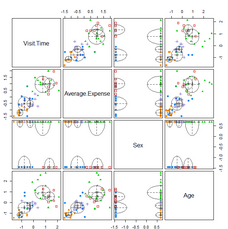
选择“2”显示不同特征值的分类结果:
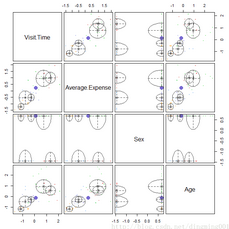
选择“3”,显示根据不同特征组合的分类不确定性:
选择4,得到不同的密度估计值
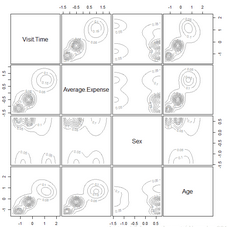
密度估计值
选择0,退出绘图菜单。
最后,使用summary函数获得似然性最大的模型以及聚簇的个数:
summary(mb)
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
----------------------------------------------------
Mclust VII (spherical, varying volume) model with 5 components:
log.likelihood n df BIC ICL
-218.6891 60 29 -556.1142 -557.2812
Clustering table:
1 2 3 4 5
11 8 17 14 10
原理
基于模型的聚类算法没有采用启发方法来构建簇,而是采用基于概率的方法,算法假设样例数据分布服从某个未知的概率分布,并试图从数据找出这个分布。有限混合模型是一类常见基于模型的方法,单个模型被分配一个线性权重再组合得到模型的结果,因而有限混合模型能够提供一个灵活的模型框架来解释数据分布概率。
假设数据y = (y1,y2,…,yn)包括n个独立多元观测值,G是模型成分的个数,有限混合模型似然公式:
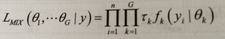
其中f(k)与O(k)是混合模型中第k个模型的密度与参数,T(K)是观测样本属于第K个模型的概率。
基于模型的聚类算法处理过程可以分成以下几个步骤:
1.算法确定好模型的数量以及概率分布类型
2.构建一个有限混合模型并计算每个模型类别的后验概率
3,最后将样本观测值分配到概率最大的类别中
本节展示了如何使用基于模型的聚类算法完成数据的划分。由BIC图我们可以知道模型的BIC值,通过这个值我们可以选择簇的个数,分类结果示意图和分类不确定性示意图分别展示了根据不同的维度组合得到的组合得到的簇结果和分类不确定性。密度图显示了密度估计值的等高线图。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330