从传统数据库到大数据引发的范式升级
大数据的出现,必将颠覆传统的数据管理方式。在数据来源、数据处理方式和数据思维等方面都会对其带来革命性的变化。对于数据库研究人员和从业人员而言,必须清楚的是,从数据库(DB)到大数据(BD),看似只是一个简单的技术演进,但细细考究不难发现两者有着本质上的差别。
如果要用简单的方式来比较传统的数据库和大数据的区别的话,我们认为"池塘捕鱼" 和"大海捕鱼:是个很好的类比。"池塘捕鱼"代表着传统数据库时代的数据管理方式,而 "大海捕鱼"则对应着大数据时代的数据管理方式,"鱼"是待处理的数据。"捕鱼"环境条件的变化导致了"捕鱼"方式的根本性差异。这些差异主要体现在如下几个方面:
1、数据规模:"池塘"和"大海"最容易发现的区别就是规模。"池塘"规模相对较小, 即便是先前认为比较大的“池塘”,譬如 VLDB(Very Large Database),和"大海"XLDB(Extremely Large Database)相比仍旧偏小。"池塘"的处理对象通常以 MB 为基本单位,而"大海"则 常常以GB,甚至是 TB、PB 为基本处理单位。
2、数据类型:过去的"池塘"中,数据的种类单一,往往仅仅有一种或少数几种,这 些数据又以结构化数据为主。而在"大海"中,数据的种类繁多,数以千计,而这些数据又 包含着结构化、半结构化以及非结构化的数据,并且半结构化和非结构化数据所占份额越来 越大。
3、模式(Schema)和数据的关系:传统的数据库都是先有模式,然后才会产生数据。这 就好比是先选好合适的"池塘",然后才会向其中投放适合在该"池塘"环境生长的"鱼"。 而大数据时代很多情况下难以预先确定模式,模式只有在数据出现之后才能确定,且模式随 着数据量的增长处于不断的演变之中。这就好比先有少量的鱼类,随着时间推移,鱼的种类 和数量都在不断的增长。鱼的变化会使大海的成分和环境处于不断的变化之中。
4、处理对象:在"池塘"中捕鱼,"鱼"仅仅是其捕捞对象。而在"大海"中,"鱼" 除了是捕捞对象之外,还可以通过某些"鱼"的存在来判断其他种类的"鱼"是否存在。也 就是说传统数据库中数据仅作为处理对象。而在大数据时代,要将数据作为一种资源来辅助 解决其他诸多领域的问题。
5、处理工具:捕捞"池塘"中的"鱼",一种渔网或少数几种基本就可以应对,也就是 所谓的 One Size Fits All。但是在"大海"中,不可能存在一种渔网能够捕获所有的鱼类,也 就是说 No Size Fits All。
从"池塘"到"大海",不仅仅是规模的变大。传统的数据库代表着数据工程(Data Engineering)的处理方式,大数据时代的数据已不仅仅只是工程处理的对象,需要采取新的 数据思维来应对。图灵奖获得者、著名数据库专家 Jim Gray 博士观察并总结人类自古以来, 在科学研究上,先后历经了实验、理论和计算三种范式。当数据量不断增长和累积到今天, 传统的三种范式在科学研究,特别是一些新的研究领域已经无法很好的发挥作用,需要有一 种全新的第四种范式来指导新形势下的科学研究。基于这种考虑,Jim Gray 出了一种新的 数据探索型研究方式,被他自己称之为科学研究的"第四种范式"(The Fourth Paradigm)。表四种范式的比较:
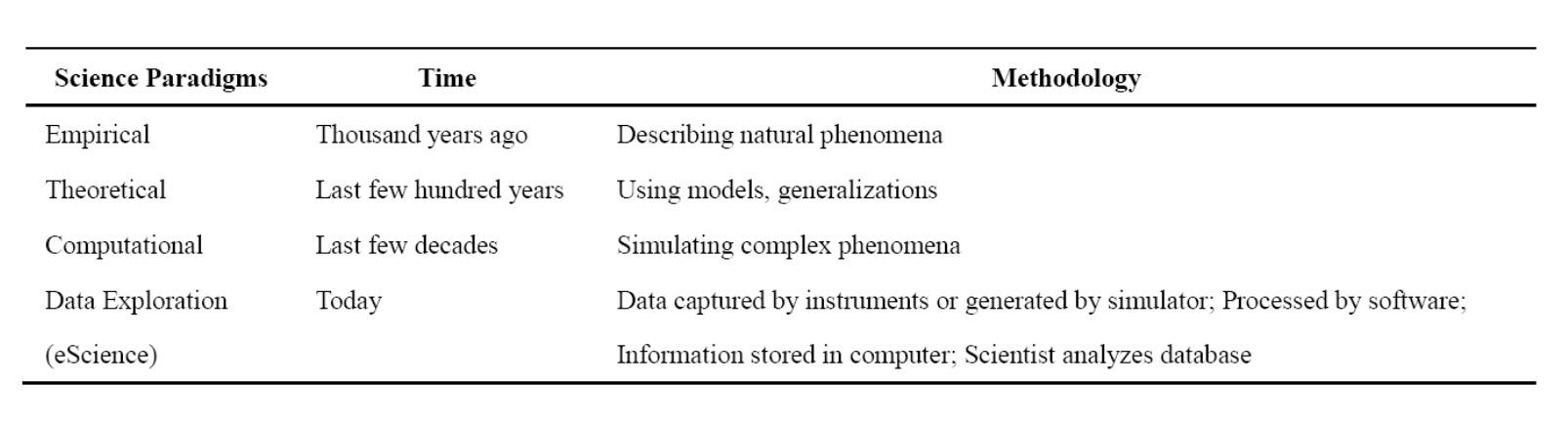
四种范式的比较如上图所示。第四种范式的实质就是从以计算为中心,转变到以数据 处理为中心,也就是我们所说的数据思维。这种方式需要我们从根本上转变思维。正如前面提到的"捕鱼",在大数据时代,数据不再仅仅是"捕捞"的对象,而应当转变成一种基础 资源,用数据这种资源来协同解决其他诸多领域的问题。计算社会科学(Computational Social Science)基于特定社会需求,在特定的社会理论指导下,收集、整理和分析数据足迹(data print),以便进行社会解释、监控、预测与规划的过程和活动。计算社会科学是一种典型的需要采用第四种范式来做指导的科学研究领域。Duncan J. Watts 在《自然》杂志上的文章《A twenty-first century science》也指出借助于社交网络和计算机分析技术,21 世纪的社会科学 有可能实现定量化的研究,从而成为一门真正的自然科学。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330