社交数据在征信领域的应用探索
在WOT”互联网+”时代大数据技术峰会上,来自腾讯数据挖掘高级工程师刘黎春做了以《社交数据在征信领域的应用探索》为主题的演讲,主要内容由社交征信背景、腾讯社交网络数据、个体用户画像研究、社团圈子研究、模型建设及应用这五部分构成,下面我们就逐一为大家介绍各部分的内容。
社交征信背景
刘黎春表示,征信并不是一个简单征信评分的模型,而是由数据公司、征信公司、征信使用方三部分组成。数据公司就是采集或做一些数据的初步挖掘,这类公司可能会有特殊的数据源,例如法院、公安等这些数据都是需要深入行业背景才能拿到。征信公司是有一个产权联系,另外它也会向第三方一些数据公司去购买一些数据回来,丰富它数据的维度,并且基于这些数据去做一些征信的事情,提供一些征信级的解决方案。征信使用方就是征信的解决方案最后给到谁来用。一般来说我们的理解就是银行和P2P的贷款机构。这三部分综合起来,就形成了一个整体的征信行业的产业链。
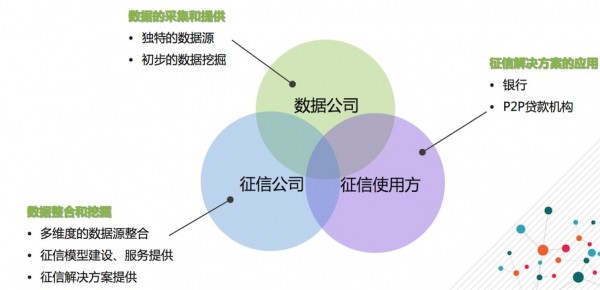
传统征信相关机构
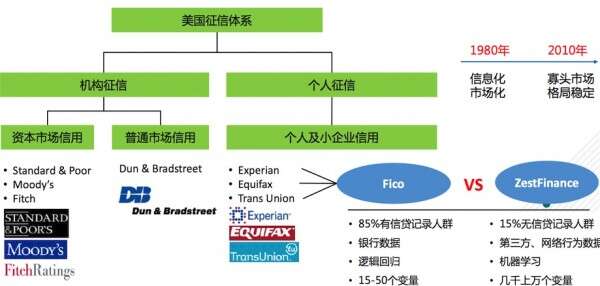
美国著名征信公司
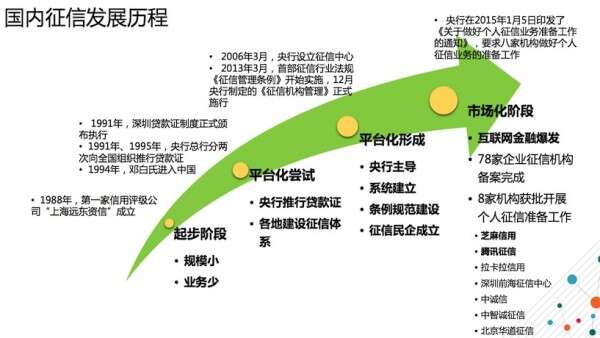
国内征信发展历程
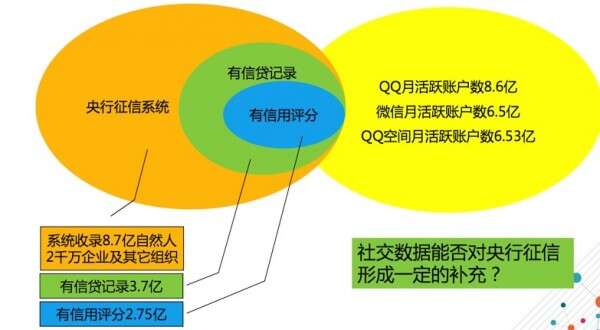
综合以上四图的数据来看,如果社交数据可以用到征信中的话,是不是可以对央行的征信系统做一个很好的补充呢?刘黎春表示,这是腾讯在做社交征信项目时最开始思考的问题。社交数据非常庞大,但并不一定都是有效数据,还要看具体应用的业务场景是不是和数据有相关性,这些数据是不是真的能够用到最后的模型或者算法中去。这样问题就接踵而来,社交数据与信用评级有关系吗? 交易数据天然具备金融属性,社交数据有吗? 社交数据非结构化程度高,怎么挖掘并有效使用?
 腾讯社交网络数据
腾讯社交网络数据
在谈腾讯社交网络数据构成之前,刘黎春先介绍了传统征信的分析维度。其一是用户的基础信息,如年龄、性别、职业、收入、婚姻状况,工作年限,工作状况等基本上和每家银行或者每个做征信的机构获得的数据都差不多。其二是信贷情况,看用户申请几张信用卡,最近一个月的征信报告被查询的次数,因为我们大家都知道征信报告被查询的次数可以直接代表最近有没有比较频繁地做贷款的申请或者信用卡申请。如果最近的次数特别多,那说明这个人最近非常缺钱,可能就会影响信用,直接影响授信额度。
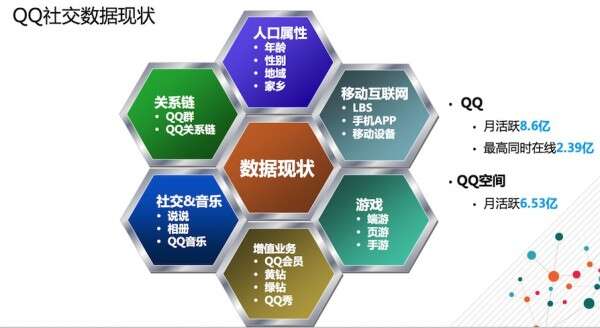 上图是腾讯的数据现状,包含了很多维度的数据,覆盖的用户数相对来说更加全面一些。
上图是腾讯的数据现状,包含了很多维度的数据,覆盖的用户数相对来说更加全面一些。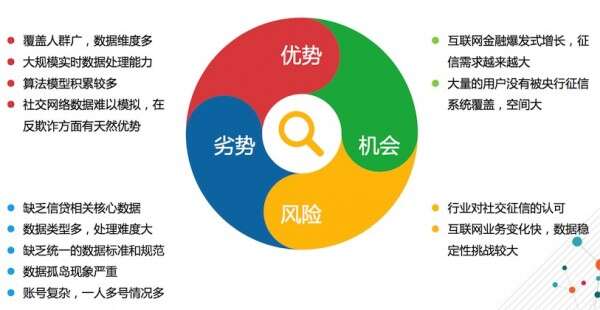
腾讯社交征信SWOT分析
上图为腾讯社交征信SWOT分析,优势、劣势、机会、风险一目了然。有了这样详细的分析,做个人征信是必然的事情,但做征信之前要清楚的知道征信对象是什么样子,所以开始着手做个体用户画像的研究。
个体用户画像研究
刘黎春表示,做个体用户画像研究遇到的挑战主要有如下三方面:其一,如何充分利用腾讯各种丰富的数据资源及之间的联系?其二,如何使用户画像适应各种不同的应用场景?其三,如何高效的处理海量的用户数据(超过10亿的QQ用户, 超过千亿级别的各类日志数据) ?面对这些挑战,刘黎春给出来相应的解决方案如下:
1.针对不同的底层数据类型设计特定的挖掘算法,挖掘用户的行为特征,形成底 层标签。综合考虑不同数据来源的,形成更上层的抽象用户标签
2.建立完善的用户画像标签体系结构,从不同维度、粒度对用户进行描述。
3.搭建用户画像挖掘系统,基于大规模存储和机器学习计算平台,定期对全 量用户数据进行计算和挖掘,并提供用户标签的使用和查询服务。
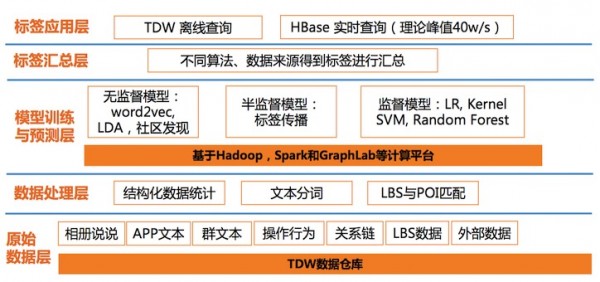
用户画像系统架构
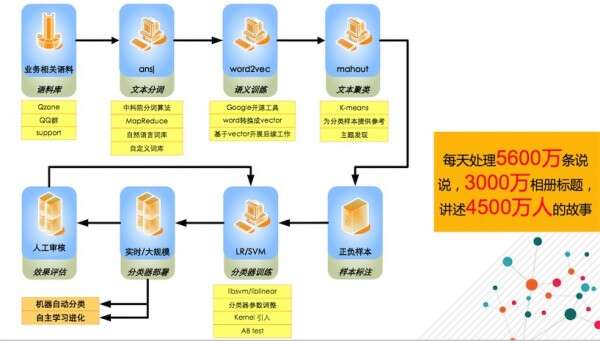
用户画像文本挖掘系统
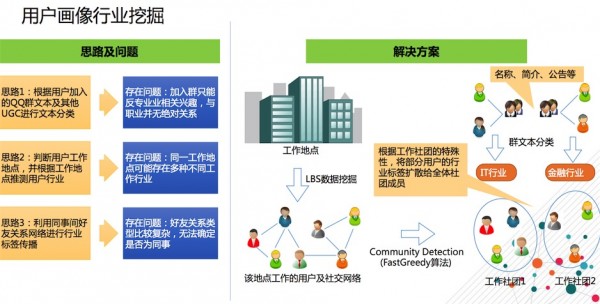
用户画像行业挖掘
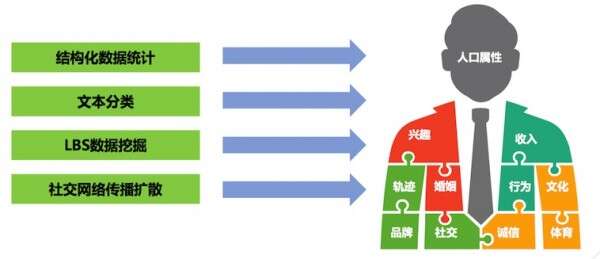
用户画像挖掘结果
个人用户画像研究的结果就是把结构化数据,文本分类,LBS数据,社交网络传播扩散这些挖掘之后形成一个比较完整的画像,比如说人口的一些基础属性如年龄、家乡、兴趣等。同时也会对用户婚姻状况来做一个判断。有了这些数据之后,就可以基于这些用户数据去做很多社交征信工作。
社团圈子研究
这里说到的社团圈子其实就是QQ圈子,刘黎春表示,在2012年有一个社交网络的成果非常有影响力,那就是把挖掘出来的结果作用到整个前端的QQ用户。具体案例就是如用户的某个同事,你们并不是直接的好友关系,但腾讯会知道这期间的潜在关系,或自动分到同事分组并同时加上备注。这个结果在当时引起了很大争议有人觉得对于他们找到一些潜在好友提供便利,但有些人觉得触碰了他们的隐私。
QQ圈子除了它自己本身之外,也会把它作用到很多场其他景里去,比如说用它来挖掘学历的信息,基于QQ圈子好友的备注,如说很多人把这个用户备注成一个本科同学,那系统可能会判断我的学历是本科学历。这样的数据腾讯是拿一些真实的数据做过验证,数据覆盖率大概能覆盖74%,准确到90%以上。
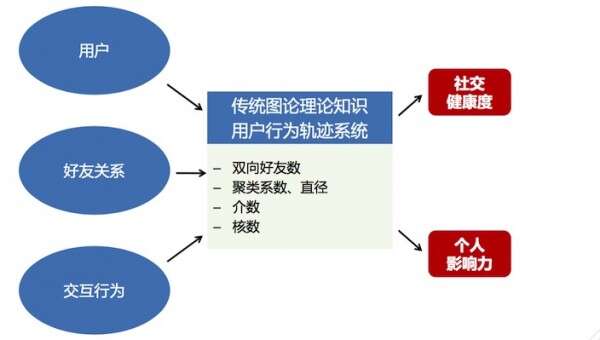
社交网络拓扑的应用
社交网络拓扑的应用无外乎有两种,其一是是判断拓扑的类型,其二是研究这些类型在这个关系链里的影响力。比较有标志性的拓扑类型有三角形和心型两种结构。
模型建设及应用
那么要如何把个体用户画像和社团圈子的研究,用到模型中去呢?刘黎春表示,首先要做的事情就是先建立一个社交模型,但在建模之前要做一些基本假设,如两个QQ号码是属于同一个人的话有一些比较明显的特征,第一个他会经常在同一个设备里面登陆,或者在同样的IP里面登陆,或者它有其他特征的表现等等。最后把这些特征用来建立模型,去判断说某几个QQ号码背后对应的到底是不是同样一个人,这个的准确率大概是85%,覆盖率是75%左右。
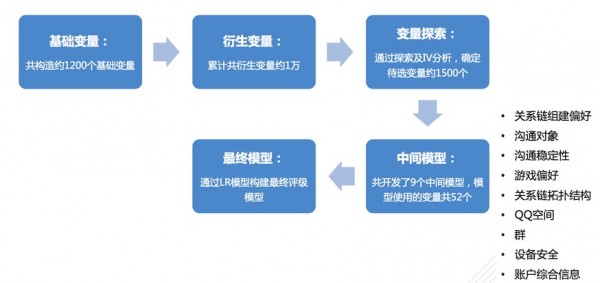
变量衍生与模型结果
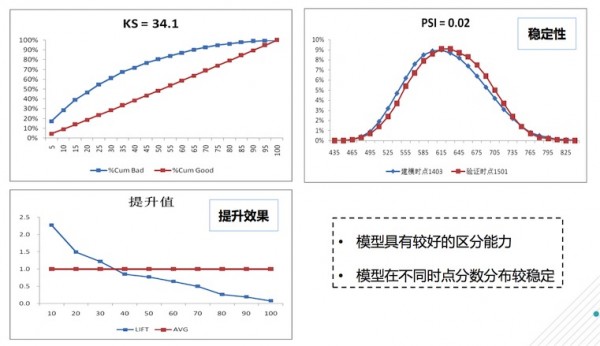
模型整体效果
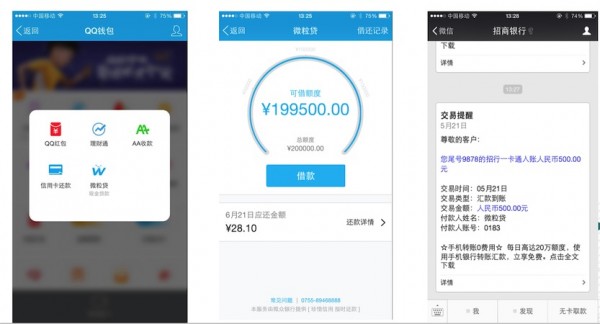
微粒贷应用
最后刘黎春介绍征信模型运用到微粒贷中的具体应用流程,上图为产品截图。打开QQ如果能够看到微粒贷入口,说明是在腾讯筛选出的白名单里面。只要你点击了申请开通,它会马上给你算一个额度出来,如果你要借款,这个也是非常快,只要你绑定了你的银行卡,应该在两分钟之内会把你的借款打到你的账上。其实这个相对于去传统银行借款的话,它这个效率是有一个质的飞跃。但其前台产品表现得越简单,它背后的技术可能是越复杂的技术。征信模型作为微粒贷背后技术就是为了筛选具有良好信用的用户,为这些用户提供贷款服务。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330