大数据与哲学的一毛钱关系_数据分析师考试
大数据也可用来形容人们创造的大量结构化和非结构化数据。
1. 大数据实质
大数据的实质是什么?虽然目前国内外都还没有统一的定义或认识,但从狭义的字面来理解的话,它应该与小数据相对应,大数据意指数据 量特别巨大,超出了我们常规的处理能力,必须引入新的科学工具和技术手段才能够进行处理的数据集合。(所谓的小数据指的是数据规模比较小,用我们的传统工 具和方法足以进行处理的数据集合)。比如牛顿时代的各门自然科学,其数据量都不大,第谷观测了20年的天文数据,开普勒很快用手工就处理完毕,并从中发现 了开普勒定律。后来,随着科学的发展,数据量有了比较大的增加,为了处理这些当时看来的“大数据”,统计学家创造了抽样方法,由此解决了数据处理难题。现 在的大数据却是所谓的海量数据,各种数据的差别又特别巨大,用抽样方法也难于处理,只能用现在的数据挖掘和云计算、云存储等新技术才能解决。从广义来说, 大数据指的是一种新的数据世界观,它将世界上的一切事物都看作是由数据构成的,一切皆可“量化”,都可以用编码数据来表示。这就是舍恩伯格所说的:“大数 据是人们获得新认知、创造新价值的源泉;大数据还是改变市场、组织机构,以及政府与公民关系的方法。”
2. 大数据的特点
大数据的特点被人总结为4个“V”:第一,Volume(大量),即数据数量巨大。从TB级别,跃升到PB级别。第 二,Variety(多样),即数据类型繁多。除了标准化的结构化编码数据之外,还包括网络日志、视频、图片、地理位置信息等等非结构化或无结构数据。第 三,Value(价值),即商业价值高,但价值密度低。在数据的海洋中不断寻找,才能掏出一些有价值的东西,可谓“沙里淘金”。第 四,Velocity(高速),即处理速度快,实时在线。各种数据基本上实时、在线,并能够进行快速的处理、传送和存储,以便全面反映对象的当下状况。
3. 大数据的哲学基础:同构关系——大数据的数理哲学基础
大数据可认为是人类的认识和实践,也就是一个数据搜索、处理、挖掘和创造的过程。大数据方法揭示的因果关系是常规性的,数据反映的 是具有同构关系的两个序列关系信息,一个对象的运动轨迹,通过另一个序列的载体编码来表述。认识者获得的不是对象本身的绝对映像,而是离开了对象,从对象 中抽象出来的、关于对象运动轨迹的数据。从这一角度看,同构关系是大数据的数理哲学基础。反映宇宙中形形色色事物的多样化属性和规律的大数据,这些结构性 和非结构性的数据,都统一表现为数字形式,以0和1按逻辑 关系编码,而且具有可逆性。这表明,统一的宇宙中的一切事物之间都存在着具有时空一致性的同构关系。这种关系意味着任何事物的属性和规律,只要通过适当的 编码,都可以通过统一的数字信号表达出来;换句话说,一种事物的属性和规律,可以通过数据的媒介,表现在另一种事物运动序列中。(见图一)
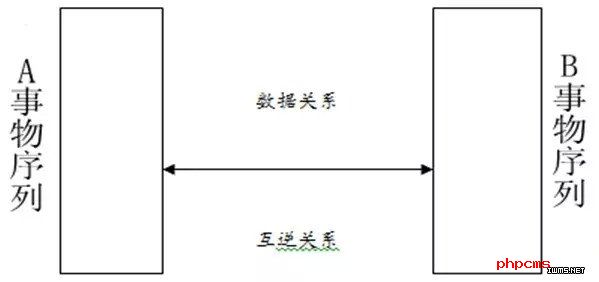
图一
对象的结构数据与人的感觉映像的结构数据是一致的,更严格地说,是同构的。
4. 大数据研究方法的变革
4.1 大数据与传统模型有很大区别
在物质形式的模型中,模型来源属于天然存在物的便是天然模型,模型来源属于人工制造物的便是人工模型。在思维形式的模型中,根据模 型不同的特点分为:理想模型、数学模型、理论模型以及半经验半理论模型。理想模型强调的是模型的抽象性,数学模型强调的是模型的数学基础,理论模型强调的 是模型的理论基础,而半经验半理论模型强调的是模型的来源,既包含理论成分,又包含经验成分。就它们的区别而言,首先,大数据模型并不具有物质形式,因此 并非物质形式的科学模型;其次,大数据模型是根据海量数据以及算法得出,无理论介入,因此也非理论模型;再次,大数据模型从海量的数据出发,通过复杂的计 算,最终得出复杂的模型,都是具体的数据运算,并无抽象过程;最后,大数据模型虽涉及算法,但大数据模型与数学模型的得出过程不同,数学模型是通过寻找研 究问题与数学结构的对应关系而确定,大数据模型则是通过寻找海量数据与算法的对应关系而确定。显然,大数据的模型方法与这里列出的已有科学模型方法均不相 同,是一种新型的模型方法,更多地体现为一种经验模型。
4.2 大数据模型与统计建模比较,也有本质的不同
数据挖掘作为一个多学科交叉的领域,涉及到数据库、统计学、机器学习等领域;从模型方法的角度来看,其中最为相近的是统计学。尽管数据挖掘涉及一定的统计基础,但数据挖掘与统计建模还是有本质的区别。
首先,科学研究中的地位不同。统计建模经常是经验研究和理论研究的配角和检验者,而在大数据的科学研究中,数据模型就是主角,模型承担了科学理论的角色。
其次,数据类型不同。统计建模的数据通常是精心设计的实验数据,具有较高的质量;而大数据中则是海量数据,往往类型杂多,质量较低。
再次,确立模型的过程不同。统计建模的模型是根据研究问题而确定的,目标变量预先已经确定好;大数据中的模型则是通过海量数据确定的,且部分情况下目标变量并不明确。
最后,建模驱动不同。统计建模是验证驱动,强调的是先有设计再通过数据验证设计模型的合理性;而大数据模型是数据驱动,强调的是建模过程以及模型的可更新性。
由此可见,尽管大数据与统计建模均是从数据中获取模型,但两者具有很大的区别,大数据带来的是一种新的模型方法,大数据中的模型是数据驱动的经验模型。
5. 大数据与哲学联系——数据挖掘的过程就是认识论的过程
近现代科学最重要的特征是寻求事物的因果性。无论是唯理论还是经验论,事实上都在寻找事物之间的因果关系,区别只在寻求因果关系的 方式不同。大数据最重要的特征是重视现象间的相关关系,并试图通过变量之间的依随变化找寻它们的相关性,从而不再一开始就把关注点放在内在的因果性上,这 是对因果性的真正超越。科学知识从何而来?传统哲学认为要么来源于经验观察,要么来源于所谓的正确理论,大数据则通过数据挖掘“让数据发声”,提出了全新 的“科学始于数据”这一知识生产新模式。由此,数据成了科学认识的基础,而云计算等数据挖掘手段将传统的经验归纳法发展为“大数据归纳法”,为科学发现提 供了认知新途径。大数据通过海量数据来发现事物之间的相关关系,通过数据挖掘从海量数据中寻找蕴藏其中的数据规律,并利用数据之间的相关关系来解释过去、 预测未来,从而用新的数据规律补充传统的因果规律。大数据给传统的科学认识论提出了新问题,也带来了新挑战。一方面,大数据用相关性补充了传统认识论对因 果性的偏执,用数据挖掘补充了科学知识的生产手段,用数据规律补充了单一的因果规律,实现了唯理论和经验论的数据化统一,形成了全新的大数据认识论;另一 方面,由相关性构成的数据关系能否上升为必然规律,又该如何去检验,仍需要研究者作出进一步思考。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330