
深度神经网络神经元个数确定指南:从原理到实战的科学路径 在深度神经网络(DNN)的设计中,“神经元个数” 是决定模型性能的关键超参数之一 —— 过少的神经元会导致模型 “欠拟合”(无法学习到数据的复杂规律), ...
2025-09-25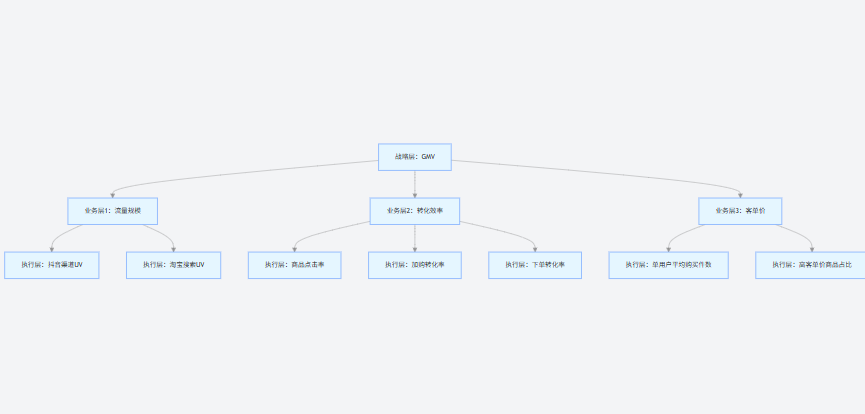
在企业数字化进程中,不少团队陷入 “指标困境”:仪表盘上堆砌着上百个指标,DAU、转化率、营收等数据实时跳动,却无法回答 “业务增长的核心瓶颈是什么”“该优先优化哪个环节”。问题的根源并非缺乏指标,而是没 ...
2025-09-25
MySQL 服务器内存碎片:成因、检测与内存持续增长的解决策略 在 MySQL 运维中,“内存持续增长” 是常见且隐蔽的性能隐患 —— 部分服务器初始内存占用仅 2GB,运行数月后却飙升至 8GB 以上,且无明显大查询或高并发 ...
2025-09-24
人工智能重塑工程质量检测:核心应用、技术路径与实践案例 工程质量检测是保障建筑、市政、交通、水利等基础设施安全的 “最后一道防线”。传统检测模式依赖人工肉眼观察、手持设备采样、破坏性试验,存在效率低(如 ...
2025-09-24
CDA 数据分析师:驾驭通用与场景指标,解锁数据驱动的精准路径 在数据驱动业务的实践中,指标是连接数据与决策的核心载体。但并非所有指标都能直接适配业务需求 —— 有些指标是跨行业、跨场景的 “通用语言”,有些 ...
2025-09-24
在数据驱动的业务迭代中,AB 实验系统(负责验证业务优化效果)与业务系统(负责承载用户交互与核心流程)并非独立存在 —— 前者需要依赖业务系统提供 “实验场景与用户数据”,后者需要通过前者验证 “优化方案的 ...
2025-09-23
CDA 业务数据分析:6 步闭环,让数据驱动业务落地 在企业数字化转型中,CDA(Certified Data Analyst)数据分析师的核心价值,并非单纯 “分析数据”,而是通过标准化的业务数据分析流程,将模糊的业务问题转化为明 ...
2025-09-23
CDA 数据分析师:以指标为钥,解锁数据驱动价值 在数字化转型的浪潮中,“用数据说话” 已成为企业决策的共识。但数据本身是零散的数字集合,若缺乏统一的衡量标准,便无法转化为指导业务的有效信息。而指标,正是将 ...
2025-09-23
当 “算法” 成为数据科学、人工智能、业务决策领域的高频词时,一种隐形的认知误区正悄然蔓延 —— 有人将分析结果不佳归咎于 “算法不够先进”,将业务突破难归因于 “没掌握复杂模型”,将认知局限解读为 “不会 ...
2025-09-22
在数据分析、金融计算、工程评估等领域,“平均数” 是描述数据集中趋势最常用的工具之一。但多数人提及 “平均数” 时,默认指向的是算术平均数(Arithmetic Mean,简称 Mean) ,却忽略了另一类关键指标 ——几何 ...
2025-09-22
CDA 数据分析师:参数估计助力数据决策的核心力量 在数字化浪潮席卷各行各业的当下,数据已成为驱动业务增长、优化运营效率的核心资产。而 CDA(Certified Data Analyst)数据分析师,作为挖掘数据价值、转化数据为 ...
2025-09-22
训练与验证损失骤升:机器学习训练中的异常诊断与解决方案 在机器学习模型训练过程中,“损失曲线” 是反映模型学习状态的核心指标 —— 理想情况下,训练损失与验证损失会随迭代轮次(Epoch)稳步下降,最终趋于平 ...
2025-09-19
解析 DataHub 与 Kafka:数据生态中两类核心工具的差异与协同 在数字化转型加速的今天,企业对数据的需求已从 “存储” 转向 “高效流转” 与 “有序管理”。然而,数据生态中的工具种类繁多,功能交叉易造成混淆 — ...
2025-09-19
CDA 数据分析师:让统计基本概念成为业务决策的底层逻辑 统计基本概念是商业数据分析的 “基础语言”—— 从描述数据分布的 “均值、中位数”,到推断总体特征的 “抽样、置信区间”,再到验证业务假设的 “假设检验 ...
2025-09-19
CDA 数据分析师:表结构数据 “获取 - 加工 - 使用” 全流程的赋能者 表结构数据(如数据库表、Excel 表、CSV 文件)是企业数字化运营的 “核心载体”,其价值实现依赖 “获取(源头)- 加工(提纯)- 使用(落地) ...
2025-09-19
SQL Server 中 CONVERT 函数的日期转换:从基础用法到实战优化 在 SQL Server 的数据处理中,日期格式转换是高频需求 —— 无论是报表展示(如 “2024 年 09 月”“09/18/2024”)、数据查询(如筛选 “2024 年 Q3 ...
2025-09-18
MySQL 大表拆分与关联查询效率:打破 “拆分必慢” 的认知误区 在 MySQL 数据库管理中,“大表” 始终是性能优化绕不开的话题。当单表数据量达到千万级甚至亿级时,查询耗时、写入阻塞、索引维护困难等问题会逐渐凸 ...
2025-09-18
DSGE 模型中的 Et:理性预期算子的内涵、作用与应用解析 动态随机一般均衡(Dynamic Stochastic General Equilibrium, DSGE)模型作为现代宏观经济学的核心分析工具,其显著特征之一是 “理性预期” 假设 —— 而Et ...
2025-09-17
Python 提取 TIF 中地名的完整指南 一、先明确:TIF 中的地名有哪两种存在形式? 在开始提取前,需先判断 TIF 文件的类型 —— 这直接决定了后续的技术方案。两种核心形式的差异如下: 地名存在形式 适用 TIF 类 ...
2025-09-17
CDA 数据分析师:解锁表结构数据特征价值的专业核心 表结构数据(以 “行 - 列” 规范存储的结构化数据,如数据库表、Excel 表、CSV 文件)是企业业务数据的 “基石形态”—— 从零售门店的 “销售明细表” 到金融机 ...
2025-09-17【核心关键词】运营、企业、核心、客户、新技术、数字化运营、数据分析、传统企业、人工录入、生产系统、技术人员、数据安全、 ...
2026-07-02在产品开发、项目立项、业务拓展、运营优化的工作中,市场调查、竞品分析、需求调研是三大核心基础工作。很多从业者容易将三者混 ...
2026-07-02 很多企业团队并非缺乏指标,而是陷入“指标失控”:仪表盘上堆满实时跳动的数据,却无法回答“当前瓶颈在哪、下一步该做什么 ...
2026-07-02在MySQL数据库运维与开发工作中,当单表数据量达到千万级、亿级后,会出现查询卡顿、索引失效、写入性能下降等问题。为优化性能 ...
2026-07-01在信息化建设、系统开发、数据分析、需求梳理的工作场景中,业务模型与逻辑模型是两个最基础、也最容易混淆的核心概念。很多项目 ...
2026-07-01 很多数据分析师能熟练计算各种指标,但当被问到“这些指标之间是什么关系”“为什么要选这个指标而不是那个”“指标体系的整 ...
2026-07-01【核心关键词】报表、数据源、客户、营销、业绩、销售、时效性、函数、可视化、运营、数据分析、数据报表、业务部门、数据运营 ...
2026-06-30在数据分析、商业预测、经济统计、运维监控等领域中,绝大多数业务数据都具备时间连续性特征,例如月度销售额、日度客流量、季度 ...
2026-06-30 很多数据分析师每天盯着GMV、DAU、转化率,但当被问到“哪些指标在所有行业都适用”“哪些指标只对电商有意义”“二者如何搭 ...
2026-06-30在 SQL Server 安装、服务启动、数据库文件操作等场景中,经常会遇到 “实例已在使用” 类报错,不同触发场景的原因与处理方式差 ...
2026-06-29在Excel数据统计、财务核算、销售复盘、库存盘点等办公场景中,经常需要在数据透视表中实现一列数据乘以另一列数据的计算需求, ...
2026-06-29在数据分析中,指标是连接业务与数据的核心语言。它并非一个简单的数字,而是一个将模糊的业务需求(如“提升用户粘性”)转化为 ...
2026-06-29【核心关键词】大数据、零售商、消费者、供应链、运营、企业、产品、客户、数据模型、大数据平台、数据开发、系统运维、业务逻 ...
2026-06-26在物流配送、供应链履约、终端供货等业务场景中,送货率是衡量企业履约能力、服务质量、供应链稳定性的核心业务指标,直接关联客 ...
2026-06-26 很多数据分析师精通描述性统计,能熟练计算均值、中位数、标准差,但当被问到“用500个样本如何推断10万用户的真实满意度” ...
2026-06-26在数字化管理与数据化运营体系中,指标是连接原始数据与业务决策的核心载体。零散的原始数据只是无意义的数值堆砌,无法直接反映 ...
2026-06-25在Excel数据汇总、财务统计、业务复盘等日常办公场景中,经常需要完成逐行相乘、整体汇总求和的计算需求,最典型的场景就是:单 ...
2026-06-25 很多数据分析师沉迷于复杂的机器学习算法,却忽略了数据分析最基础也最核心的能力——描述性统计。事实上,80%的商业分析问 ...
2026-06-25【核心关键词】主数据、资产、供应商、现金流、企业、精细化、集团、数字化、中国、数据质量、数据管理、经营管理、地产行业、 ...
2026-06-24在数据分析、假设检验、AB测试、学术研究等统计场景中,显著水平(α)与P值(P-value)是判断统计结果是否具有统计学意义的两个 ...
2026-06-24





