百度大数据应用与实践_数据分析师考试
百度基于海量的数据处理能力,利用机器学习和深度学习等手段建立模型,可以实现公众生活的预测业务。目前,在百度预测产品中已经推出了景点舒适度预测和城市旅游预测、高考预测、世界杯预测等服务。
以世界杯预测为例,在2014年巴西世界杯的四分之一决赛前,百度、谷歌、微软和高盛分别对4强结果进行了预测,结果显示:百度、微软结果预测完全正确,而谷歌则预测正确3支晋级球队;在小组赛阶段的预测,谷歌缺席,微软、高盛的准确率也低于百度。总体来看,无论是小组赛还是淘汰赛,百度的世界杯结果预测中均领先于其他公司。最终,百度又成功预测了德国队夺冠,如图5所示。

图5 百度世界杯预测
预测准确度来自百度对大数据的强大分析能力和超大规模机器学习模型。在对体育数据的研究过程中,百度的科学家发现类似保罗章鱼的赛事预测完全有可能借助大数据的分析能力完成。因此,百度收集了2010-2013年全世界范围内所有国家队及俱乐部的赛事数据,构建了赛事预测模型,并通过对多源异构数据的综合分析,综合考虑球队实力、近期状态、主场效应、博彩数据和大赛能力等5个维度的数据。最终实现了对2014年巴西世界杯的成功预测。
4.2.2 公共卫生领域——疾病预测
通过百度搜索数据与医疗数据、医保数据等关联,并结合图像识别和语音识别技术、可穿戴设备数据采集等,通过大数据分析与挖掘能力可以实现人群疾病分布关联分析等。通过对大量临床电子病历、临床经验和科研成果等医学信息数据进行学习和理解,绘制人类疾病图谱(人群分布),并建立疾病分析模型和治疗路径模型。这也将极大推动疾病研究、医药研发、药品监管、居民医疗服务和全民健康教育等事业发展。
百度与中国疾病预防控制中心(CDC)合作开发的疾病预测产品,基于对网民每日更新的互联网搜索的分析、建模,实时反馈流感、手足口、性病、艾滋病等传染病,糖尿病、高血压、肺癌、乳腺癌等流行病的爆发数据,并预测疾病流行趋势,是国家疾病控制机构传统监测体系的有力补充。结合大数据舆情分析、公共卫生危机事件预警产品,有效地融合非结构化大数据,建立了基于互联网的新兴公共卫生数据资源共享机制与服务价值链。
4.2.3 企业IT应用——硬盘故障预测
百度全球有几十个的数据中心或者内容分发网络(CDN)节点,拥有数十万台服务器和数万台交换机,200多万块硬盘。这些硬盘的年报错率为4%~7%,月均硬盘故障超过1万起,占全部硬件故障的80%以上。百度通过大数据分析与机器学习技术,对9亿条实例进行采集处理,选取15万个训练样本,监控240个特征的实时变化,构建预测模型,并通过机器学习的算法可以提前一天预测出硬盘故障并迁移数据,该系统可以节约带宽70%、节约计算资源85%、节省服务器运行消耗10%,每年节省1万多块硬盘。如图6所示,基于大数据实现硬盘故障预测的方法也可以用于实现行业硬件系统的运维和管理中。
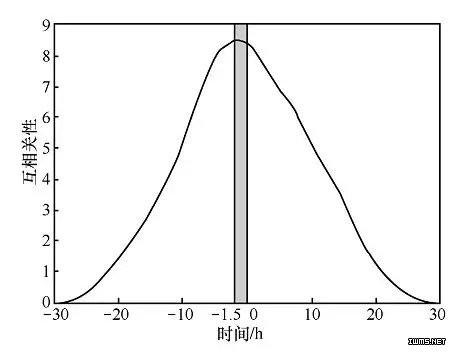
图6 基于大数据的硬盘故障预测
4.2.4 企业IT应用——智能化运维
近年来百度在服务器规模、数据规模、单集群规模等方面出现爆发式增长。百度服务器的规模近5年来增长了15倍以上,达到数十万台。数据规模已达到EB级别。在云计算和大数据时代,集群规模和数据量爆发式增长,如何管理好云计算平台、如何提供高质量的服务,是云计算的核心问题之一。
为了应对云计算和大数据应用带来的新的需求和挑战,百度同样利用大数据技术,把在线服务运维转向智能化管理模式,并走在了行业的前列。百度已经建立起了六大数据仓库之一的运维数据仓库,囊括了服务器、网络、系统、程序、变更等各个方面的实时及历史状态数据,每天更新数据量接近100TB。
基于对运维大数据的挖掘、对历史数据的学习和异常模式识别,实现对流量数据的预测。通过对包括访问速度、系统容量、带宽、成本等在内的10多个因子的实时自动分析,实现了在众多数据中心间的流量自动调度,决策时间也由人工判断的10几分钟大幅缩短到1min。这个系统的实际效果在故障中得到很好的检验,例如系统在没有人工介入的情况下智能地把流量调度到另外的数据中心,拒绝流量仅有几千个,避免类似故障可能造成数千万的流量损失。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330