怎样辨别渠道作弊—数据分析篇
有的运营人员做渠道投放,每个渠道都投放了,点击量特别高,但激活量只有个位数。也有可能点击激活数量都很高,但是留存率很低。费用都花光了,但是效果没有出来。自己做数据分析,但是却得不到结论。
我们做数据分析的前提是需要拿到靠谱的数据。如果数据不准确,基于这个数据分析出来的结论是没有意义的。
获取准确的数据,首先需要我们选择靠谱的统计分析平台,平台的选择可以参考我的前一篇文章。即便在平台靠谱的情况下,也有可能出现一些不靠谱的情况。俗话说,有榜单的地方就有刷榜,有数据统计的平台就有数据作弊的作坊。

在移动互联网生态中存在很多不为人知的渠道刷量工作室,这些工作室以非常低廉的价格贡献质量同样低廉的用户数据。
早期的统计分析平台的 SDK 基于明文的jaso n 数据包,工作室可以很方便的用程序伪造这些数据包,模拟出新增、活跃、留存、时长等用户数据。随着统计分析平台的发展,很多分析平台推出了基于二进制协议的 SDK ,开发人员还可以自行调用加密开关。这些技术的提升使统计平台的安全性和数据准确性得到了提高。如果 APP 升级到安全协议版本的 SDK ,刷量工作室已经很难采用直接模拟数据包的形式来刷量了。
所谓道高一尺魔高一丈,平台有平台的方法,刷量工作室有刷量的方式。他们可能是采用分布式人肉刷量的方式来刷量(形式可以参考基于任务的积分墙);也有可能是采用更为智能的方式,通过编写程序脚本,修改真机参数,驱动真机运行(有兴趣的同学可以了解一下igrimace这个 iOS 的刷量工具)。这些行为已经跟真实的用户行为几乎没有差别了,很难从技术上分辨这些数据。
其实有经验的运营人员还是可以通过一些数据指标来分辨出真假用户的差异。
渠道效果评估
留存率
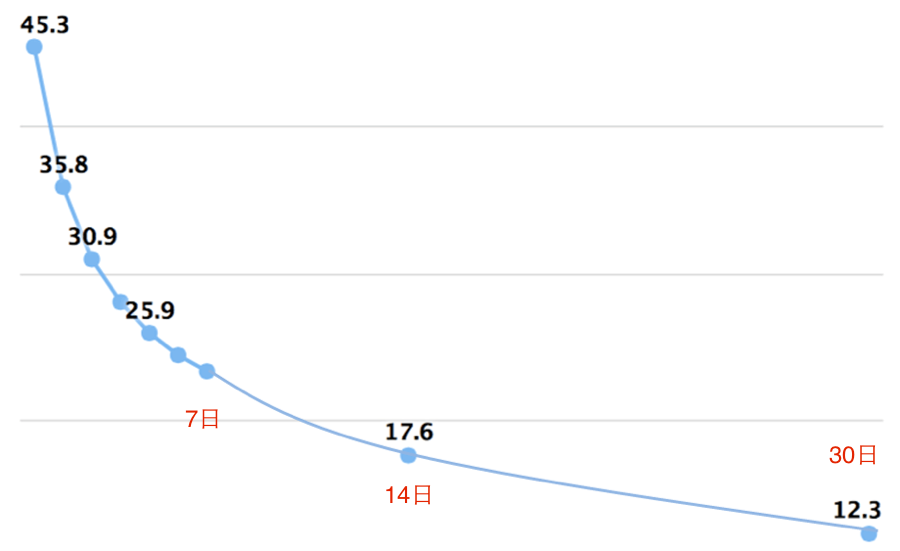
有时候渠道刷量会选择在次日、7日、30日这些重要时间点上导入用户数据。我们会发现 APP 在次日、7日、30日这些关键时间点上的数据明显高于其他时间点。其实真实的用户的留存曲线是一条平滑的指数衰减曲线,如果你发现你的留存曲线存在陡升陡降的异常波动,基本上就是渠道干预了数据。可想而知,这样的用户的质量是非常差的,也不具备商业价值。
留存曲线不仅可以帮助我们判断渠道的质量,还可以在运营推广和产品优化上给出很多参考性建议。留存率这么重要,那么,留存率是怎么计算的呢?
某一天的新增用户,在 n 天后回访的比例,就是这天的 n 日留存率。举个例子,如果我们在2月1日获取了1000个新增用户,这批用户在2月2日有400个用户回访,2月8日有200个用户回访,那么2月1日新用户的次日留存率是40%,7日留存率是20%。
留存率是业内判断用户质量的通用指标。移动互联网行业内,如果一个 APP 的次日留存率达到40%,7日留存率达到20%,30日留存率达到10%,这个 APP 的留存率就高于了业内标准了。一般来说,工具类应用的留存率高于游戏类应用的留存率,高频应用的留存率高于低频应用的留存率。除了应用类型,留存率还跟 APP 的用户体验、推广方式等因素相关。
用户终端
每个渠道都有自己覆盖的用户群,他们的用户终端会有区别。比如说小米应用商店的用户可能TOP10的机型都是小米手机,而移动MM的用户可能绝大部分是移动运营商的用户。排除这些有特殊渠道的应用商店,大部分渠道的用户终端跟整个移动互联网终端分布是类似的。我们可以通过查看移动互联网数据报告或者数据指数产品来了解这些数据,把这些数据作为be n chmark,来对比分析 APP 的数据。
我们可以重点关注设备终端、操作系统、联网方式、运营商、地理位置这些手机设备的属性。我在下面列举了一些tips,欢迎交流与拍砖。
方法一:关注低价设备的排名

你可以重点分析渠道的新增用户或者启动用户的设备排名。如果你发现某款低价设备排名异常靠前,这种情况值得我们重点关注。这些数据可以在统计平台的终端属性分布中找到。
尤其是 iOS 平台没有模拟器,所有的用户数据需要通过真机触发。很多刷量的工作室会选择购买二手的iPhone 5c来做刷量真机。有个做渠道推广的朋友踩过这样的坑,发现某个渠道有75%的设备是iPhone 5c,比top5的 iOS 设备占比还多。继而又发现这个渠道的留存率等指标都差强人意,最终查出这个渠道使用了大量的iPhone 5c来刷量。
方法二:关注新版本操作系统的占比
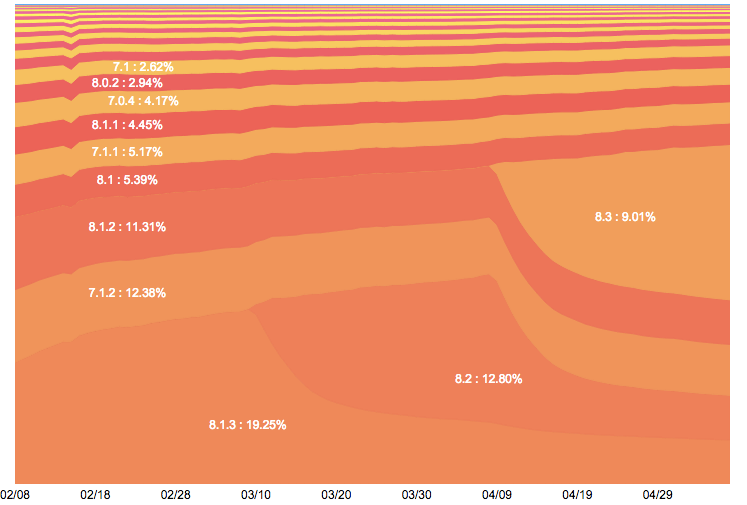
经过本人多年工作经验发现,很多渠道刷量工作室在操作系统版本的适配上会有延时。所以建议渠道人员在查看渠道用户的操作系统时,可以和全体手机网民的操作系统的分布做比较。如果你发现某个渠道下面,不存在新版本的操作系统(比如 iOS 8.x),有一种可能性就是这个渠道合作的工作室的技术还没有适配最新的操作系统。
方法三:关注wifi网络的使用情况
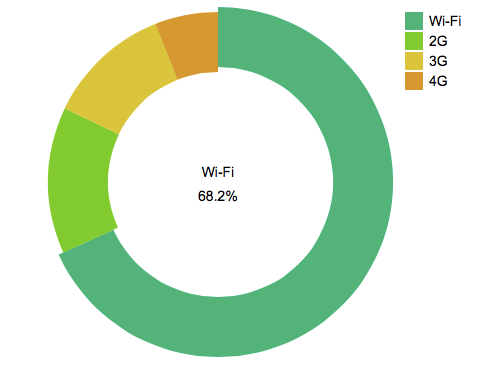
有的朋友问我,用户在wifi下面使用的比例达到了90%,这个比例到底正常不正常。
要回答这个问题,首先我们需要对现在的大形势有些了解。现在是一个高速网络的环境,无论是新增用户还是活跃用户,wifi的使用占比都比较大。
从用户行为上来说,如果你留心身边的朋友,会发现大家在下载 APP 的时候倾向于使用wifi(流量贵啊),相比之下,启动 APP 时,会对当前网络的敏感性差一些。也就是说,新增用户的wifi使用比例会大于启动用户的wifi使用比例。
另外,wifi的使用比例还跟应用类型相关。如果你是一个在线视频类型的应用,可能wifi的比例会在90%以上。
如果你是一个小流量的 APP ,同时能够在新增用户和活跃用户的wifi数据对比上看出蛛丝马迹,可能真的是渠道在捣鬼了。
方法四:定向投放也很重要
有个行业内做了很久的朋友传授给我一个经验,说福建地区的作弊比较多,我们在制定投放策略的时候可以重点考虑屏蔽作弊多的地区。这个黑名单也可以根据 APP 实际的分地域投放效果来定制。
另外,我们在投放时也可以根据需要重点选择部分地区投放。比如北上广这些高消费的地区,比如三四线城市这些相对蓝海的区域。查看数据时就需要验证用户是否和我们的投放策略相符合了。
用户行为
方法一:比较用户行为数据
如果一个 APP 做的时间比较久,访问页面、使用时长、访问间隔、使用频率等这些行为数据会趋向稳定的。不同 APP 的行为数据是有差异的。可能刷量工作室可以模拟出看似真实的用户行为,但是很难跟你的 APP 的日常数据做的完全一致。
一个渠道用户的使用时长、使用频率过高过低都值得怀疑。我们在平时做渠道数据分析时,可以将这些数据跟整个 APP 作比较,或者将安卓市场、应用宝这些大型应用商店的数据作为基准数据,进行比较。
方法二:了解新增用户、活跃用户小时时间点数据曲线
很多刷量工作室通过批量导入设备数据或者定时启动的方式来伪造数据。这种情况下,新增和启动的曲线会出现陡增和陡降。真实用户的新增和启动是一条平滑的曲线。一般来说,用户的新增和启动会在下午6点之后达到高峰。而且新增相比启动的趋势会更加明显。
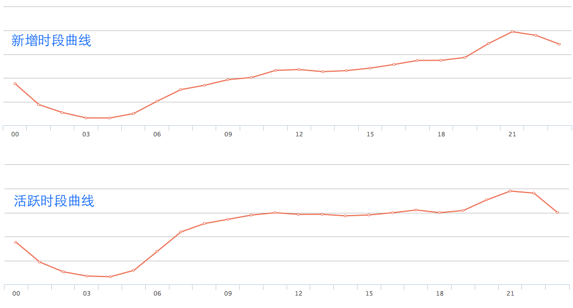
我们可以将不同渠道的分时数据进行对比,找到异常。需要注意的是,这种行为数据的对比需要遵循单一变量原则。也就是说,除了是不同的渠道,实验中的其他因素必须完全相同。如果我们选取渠道A在周三的活跃数和渠道B在周六的活跃数做对比,这两个数据肯定是有差异的,不具备可比性。
方法三:查看用户访问的页面名称明细
有些工作室会将 App key打到其它高频的 APP 中。这样,我们可能会发现渠道用户的数据非常漂亮,但是仔细观察可以发现,页面名中有大量的页面不是自己定义的。通过对比页面名称,可以定位到这种形式的渠道作弊。
如果是A n droid APP ,这个名称是activity或者fragme n t;如果是 iOS APP ,这个名称是自定义的view。这段记不住也没关系。记得找开发人员要一下具体页面的名称列表,对比一下统计后台用户访问的页面明细,就能看出差异了。
转化率分析
转化率数据的分析不仅可以帮助我们应对渠道作弊,还可以帮助我们判断不同渠道的用户质量,提高投放效率。
每一个 APP 都有自己的目标行为。比如电商类应用的目标行为就是用户购买商品的情况。游戏类的应用需要考察应用内付费。社交类应用会关注用户产生内容的情况。运营人员需要定义和设计应用的目标行为。
如果一个用户是真实的流量,他会经历点击、下载、激活、注册、直到触发目标行为的过程。我们可以将这些步骤做成漏斗模型,观察每一步的转化率。漏斗的步骤越靠后,作弊的难度越大,所获取用户对系统的价值越高,同时我们付出的用户成本也越高。运营人员需要对目标行为进行监控,在渠道推广时,考察目标行为的转化率,提高渠道作弊的边际成本。
反作弊模块
除了使用现成的统计分析工具,还可以申请让研发人员开发自己的反作弊模块。反作弊模块在原理上类似于杀毒软件,我们可以定义一些行为模式,加到反作弊模块的黑名单库中。如果一个新增设备满足定义的行为模式,就会被判定为一个作弊设备。每个运营人员都可以根据自己的 APP 来定义。我列举了一些常用的行为模式:
(1)设备号异常:频繁重置idfa
(2)ip异常:频繁更换地理位置
(3)行为异常:大量购买特价商品等
(4)数据包不完整:只有启动信息,不具备页面、事件等其他用户行为信息
写在最后:
作为一个运营人员,需要做好长期与渠道合(dou)作(zheng)的心理准备。用好数据是万里长征的第一步。希望每个运营人员能够通过数据的使用,挑选出合适的渠道,提高渠道投放的收益。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330