大数据:本轮牛市12只十倍股具有这些特征
投资大师彼得.林奇曾提出"Ten-Bagger"概念,即十年十倍股。本轮牛市,有哪些个股成为了"十倍股"?他们具有什么共同的特征?十倍股如何挖掘?
统计数据显示,自2014年7月1日以来,A股共有12只股票股价涨幅达10倍以上,对于这些投资者眼中的"宝藏",他们都具备哪些特征呢?
板块分布:创业板成十倍股集中营
12只十倍股中,暴风科技以2623.7%的最大区间涨幅摘得桂冠,是唯一一只涨幅超过20倍的股票。另外,中科曙光(1926.6%)、中文在线(1775.0%)、龙生股份(1578.1%)、兰石重装(1555.7%)、京天利(1527.6%)紧随其后。
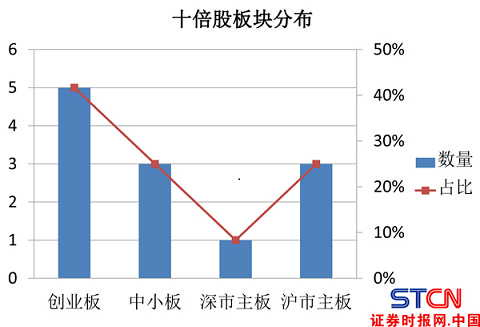
而从十倍股所属上市板块看,创业板有5 只,占比42%;中小板3 只,占比25%;深市主板1 只,占比8%;沪市主板3 只;占比25%;创业板中出现十倍股的概率明显高于其他板块。
值得注意的,12只十倍股中,有5只属于次新股,分别是暴风科技、中科曙光、中文在线、兰石重装和京天利,上市时间均在2014年10月之后,也就是说,这5只个股用了不到8个月时间,股价便翻了10倍之多。
市值:低市值是十倍股的沃土
剔除上述5只次新股来看,牛股上涨伊始,初始市值规模均较小。7只十倍股中,有5家公司期初市值规模小于30亿元;2 家公司期初市值规模在30~40 亿元之间。其中,初始市值最小的是如意集团(16.61亿),最大为同花顺(38.28亿)。
行业:计算机业、传媒业出现十倍股概率最高
行业分布方面,以产生十倍股的绝对数量来看,计算机行业出现了最多的十倍股,达4只;此外,传媒、机械设备各有2只十倍股。
而从十倍股产生的概率来看,计算机、传媒行业十倍股出现的概率最高(十倍股个数/所在行业个股数),分别为2.94%和2.99%。
如何寻找下一只十倍股?
投资大师彼得.林奇说:"事实上很多十倍股都来自于大家非常熟悉的公司。"十年十倍股不是远在天边,而是近在身边。那么那些个股最有潜力成为十倍股呢?
以下小编尝试归纳彼得.林奇的投资哲学:
一、彼得.林奇认为盈利增长为主导股价走势的重要因素,但他同时对一些增长过快的公司存在戒心,担心这种增长速度将无以为继,或该行业会吸引大量竞争对手;
二、透过观察市盈率与增长比率,可发现一些被低估或高估了的股票;而他相信该数值低于1的公司相对吸引;
三、拥有充足现金流的企业,对于其发展及抵御经济周期的能力相对较高;
四、一些市值较高的企业,往往难以给予投资者太多的投资回报,相反,规模较小的公司的股价爆炸力有时却相当惊人;
五、通过经营利润率的历史数据,可寻找一些盈利稳定的公司,特别是经济不景时仍有不俗收入的企业;
六、找到优秀的企业只是成功的一半,另一半还须找出合适的投资时机。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330