如何将Hadoop与其数据仓库设备更好的融合
从Teradata第四季度财报电话会议上,你已经看到这家公司与其他数据仓库公司的竞争远不如Hadoop那么大。
Teradata首席执行官Mike Koehler以及首席财务官Steve Scheppmann在公司财报电话会议上不断谈论Hadoop。是Hadoop抢走了Teradata的生意吗?收入受到了怎样的影响?Teradata是否可以与Hadoop并存?
Teradata第四季度比预期稍好,前景较为保守。Teradata的统一架构融入Hadoop开源平台用于分析大数据,但是一些ETL(提取、转换以及加载)负载正在远离Teradata。
根据Teradata的报告,第四季度收益1.12亿美元(或者每股68美分),收入7.69亿美元,同比增长4%。第四季度Teradata的非GAAP收益为每股88美分。华尔街之前预期该季度Teradata的收益为每股85美分。因此收入与预期持平,收益好于预期。在经过艰难的第三季度之后,Teradata在该季度的结果可以算是一个胜利。
就前景看,Teradata表示2014年收入增幅预计在3%到7%之间,非GAAP收益在每股2.85美元到每股3美元之间。这一结果低于华尔街预期的每股3.04美元。
尚不明确的是,Teradata的业务是否受到Hadoop的影响,以及影响程度有多大。Teradata将Hadoop结合到自己的架构中,并将其与自己的Aster平台相融合。
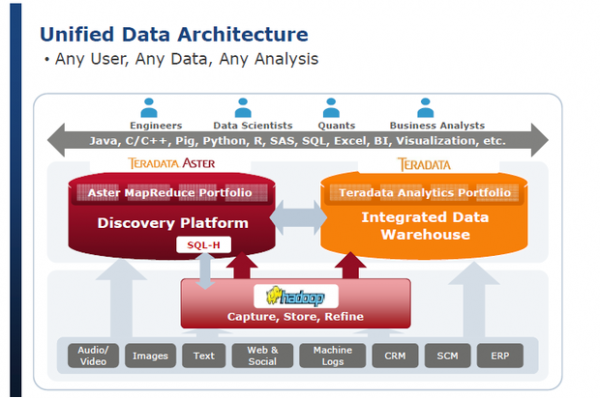
Teradata的计划是将Hadoop与自己的数据仓库设备融合。这一计划是有道理的,因为大多数大型客户在可预见的未来内都会采取一种混合的方法。但是像一家从许可和支持转向围绕云和订购的软件公司,这样的过渡必须拿捏好。
Koehler表示:我们在美洲的前50大客户中有接近1/3已经在生产中采用Hadoop,其他2/3正处于各种评估的阶段。那些在生产中部署Hadoop的客户在Teradata数据仓库上的支出模式与没有采用Hadoop的客户是类似的。我们正在与这些客户紧密合作,其中有半数的客户已经采用了我们的Unified Data Architecture统一数据架构。实施了我们UDA的客户总数翻了三番,我们有多个理念正在验证中。除此之外,我们的2013 Aster和Hadoop相关收入已经接近于2012年的四倍。我们将拥抱Hadoop并将它作为UDA的关键组成部分,因为我们相信,大数据和Hadoop对我们的客户和我们自己来说都是一个福音。
在随后的评论中,Koehler补充说,在大多数情况下,客户们已经在生产中部署了Hadoop,正如我们在最近的财报电话会议上所说。他们的做法是围绕着ETL和将部分ETL工作负载从Teradata EDW上迁移出来,我们认同这个这一点,这也是我们在最近的财报电话会议上说过的。因此,客户这样做所带来可量化的影响相对较小。现在,如果你以未来的眼光看Hadoop的影响,我倾向于我们在上次会议所说的。也就是,基本上我们对大型客户做了全面的分析,我们看到他们平均20%到40%的工作负载已经完成——用于ETL。这些工作负载中20%到40%正在使用ETL,我们认为20%适合于使用Hadoop。因此展望未来,我们将看到越来越多的工作负载因为与ETL相关而被迁移,我们认为这是最大的影响。
也许对于Teradata来说,更大的风险是他们最大的客户的资本开支并没有增加。这个事实意味着越来越多的客户会考虑Hadoop,因为随着开源项目的不断发展,未来Hadoop将能够处理更高的工作负载。如果企业认定了他们可以在没有大数据仓库和集成设备的情况下掌控大数据和分析,那么Teradata面临的问题可就不止是Hadoop了。一些分析师认为,企业已经开始重新考虑他们的数据仓库战略了。
Cowen分析师Peter Goldmacher指出:Teradata说,2013年最大的难题是Teradata无法让他们的前50大客户花钱。这个趋势主要是因为开支放缓所导致,我们的分析认为,这种公司会是最积极采用Hadoop的群体。我们认为,Teradata的全年业绩显示了那些购买Teradata产品的客户对于Teradata利润较低的中端、低端以及更低成本的产品更感兴趣。我们还看到Cloudera更新了他们推向市场的战略,Cloudera是一家出现在Teradata关注视野中的Hadoop初创公司,他们将自己的产品定位为Teradata的替代解决方案,成本只是Teradata的很小一部分。随着时间的推移,随着Hadoop的功能性和可用性显著改善,我们看到来自Cloudera以及其他Hadoop分销商的威胁加大,很快在未来今年的某个时间点,Teradata将不再具备任何技术竞争优势。我们看到一些早期迹象,企业正在重新考虑他们的整体数据管理架构,在这个新模式中给传统厂商留下的空间非常小。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330