小编今天跟大家分享的这篇文章是关于python语音识别的,语音识别是人工智能研究的重要领域。希望这篇文章能对大家python学习和使用有所帮助。
文章来源: 饭饭的Python学习之路
作者: 一粒米饭
语音合成概述
总的来说,语音合成是通过机械的、电子的方法产生人造语音的技术。其中TTS,是Text-To-Speech缩写,即“从文本到语音”,是人机对话的一部分。它属于语音合成,是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的语音输出的技术。本文中提到的语音合成是指TTS。生活中用到的林志玲导航、郭德纲导航等就是基于TTS实现。
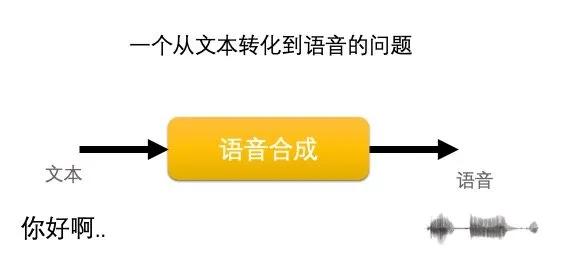
语音合成方法
这里简单论述下语音合成的传统方法以及近年来基于深度学习的合成方法,对这部分不感兴趣的同学可以直接跳过,不影响后面阅读。
传统方法
语音合成的传统方法可分为拼接和参数化两种。
-
拼接,拼接方法是指从语音数据库中选择需要的语音片段来合成完整的语音。这种方法需要大量的语音数据,灵活性较差,且不能合成新的语音片段。
-
参数化,参数化方法是指用一条记录下的人的声音以及一个含参函数,通过调节函数参数来改变语音。这种传统的方法工作量比较大。
基于深度学习的方法
今年来随着神经网络的不断发展,深度学习技术在语音合成方面也有着广泛的应用,大致包含以下几个方向:
-
WaveNet: 原始音频生成模型,WaveNET是基于PixelCNN的音频生成模型,它能够产生类似于人类发出的声音。论文地址
-
Tacotron:端到端的语音合成,Tacotron是一个seq2seq模型,该模型包括一个编码器、一个基于注意力的解码器以及一个后端处理网络。论文链接
-
Deep Voice 1: 实时神经文本语音转换,它是一个利用深度神经网络开发的文本到语音的系统。论文链接
-
Deep Voice 2: 多说话人神经文本语音转换,它与DeepVoice 1类似,但它在音频质量上却有显著的提高。该模型能够从每个说话人不到半个小时的语音数据中学习数百种独特的声音。论文链接
-
Deep Voice 3: 带有卷积序列学习的尺度文本语音转换,作者提出了一种全卷积字符到谱图的框架,可以实现完全并行计算。该框架是基于注意力的序列到序列模型。这个模型在LibriSpeech ASR数据集上进行训练。论文链接
-
Parallel WaveNet:
快速高保真语音合成,该模型来自谷歌,它引入了一种叫做概率密度蒸馏的方法,它从一个训练过的WaveNet中训练一个并行前馈网络。该方法是通过结合逆自回归流(IAFS)和波形网(WaveNet)的最佳特征构建的。这些特征代表了WaveNet的有效训练和IAF网络的有效采样。论文链接
-
利用小样本的神经网络语音克隆,该模型来自百度,它引入了一个神经语音克隆系统,它可以通过学习从少量音频样本合成一个人的声音。论文链接
-
VoiceLoop: 通过语音循环进行语音拟合与合成,该论文来自Facebook,它引入了一种神经文本到语音(TTS)技术,可以将文本从野外采集的声音转换为语音。论文链接
-
利用梅尔图谱预测上的条件WaveNet进行自然TTS合成,该论文来自谷歌和加州大学伯克利分校。他们引入了Tacotron
2,这是一种用于文本语音合成的神经网络架构。它由一个循环的的序列到序列特征预测网络组成,该网络将字符嵌入到梅尔标度图谱中。然后是一个修改后的WaveNet模型,这个模型充当声码器,利用频谱图来合成时域波。论文链接
Python的语音合成
用Python来进行语音合成的方法有很多,这里通过比较几个典型的开源库和国内语音平台供同学们参考。由于谷歌的服务无法直接使用,故不在比较列表中,另外windows上特有的语音合成方法也不在范围内。
-
开源库, pyttsx3pyttsx3
是一个开源的离线语音合成库,只要用pip安装后即可使用,安装命令如下:
$ pip install pyttsx3
优点:免费,使用简单
缺点:合成语音效果一般
2.科大讯飞科大讯飞提供丰富的发音类别来合成有特殊的语音,通过api接口进行语音合成,并且可以对多音字、静音停顿、数字、英文读法等提供了控制标记。
优点:语音合成效果较好,可以灵活控制多音字、静音、英文等读法。缺点:免费使用接口有500次的限制,在实际使用经常不够用。
3.腾讯
腾讯有多个平台在提供语音合成接口,包括腾讯AI实验室、腾讯优图、腾讯云。其中腾讯AI开放平台合成效果一般;腾讯优图目前免费试用,且不限制请求次数,但不保证QPS;腾讯云语音合成效果也不错,合成免费额度为每月100万字符,相当于一本《西游记》的字数。每月1日重置免费额度,一般情况下也够用了。

优点:选择多,其中腾讯优图和腾讯云语音合成效果较好
缺点:无法控制多音字读法、数字读法、英文读法和停顿
4.阿里云阿里云语音合成接口当前改成了websocket请求方式,按次数进行收费。
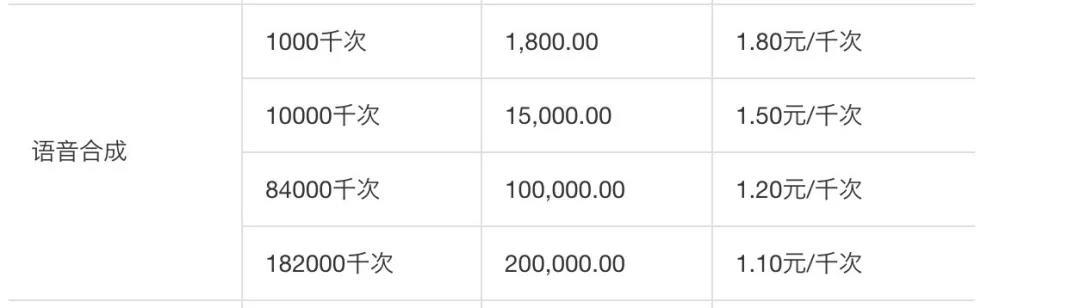
优点:语音合成效果较好,语音模型丰富。
缺点:正式产品使用的话还是要花钱。
5.百度
支持在线语音合成和离线语音合成。离线语音合成在个人认证后只能在两台终端上使用,在线语音合成有QPS和有效期限制,详情如下:
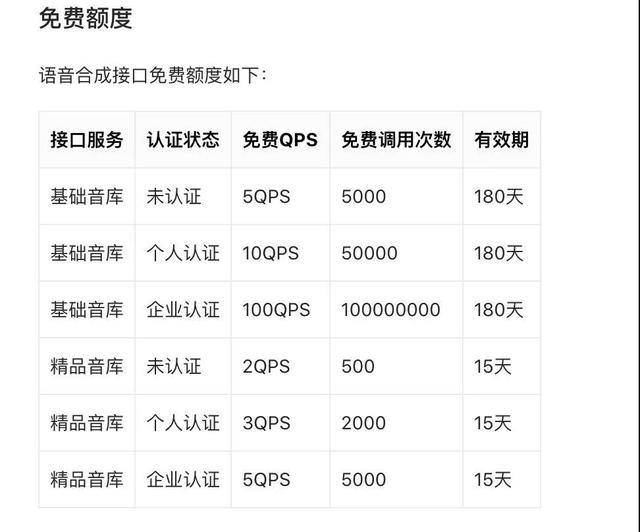
优点:合成语音效果还行,使用较为简单,开发测试的话免费额度够用了。
缺点:正式产品使用的话还是要花钱。
实例开发
这里以腾讯云的语音合成为例实现一个简单的语音合成脚本。
-
登录,登录腾讯云官网,若还未注册的话先注册一个账号。
-
实名认证,若未进行过实名认证,在腾讯云账号中心进行实名认证。
-
开通语音合成服务,进入语音合成控制台开通语音合成功能。
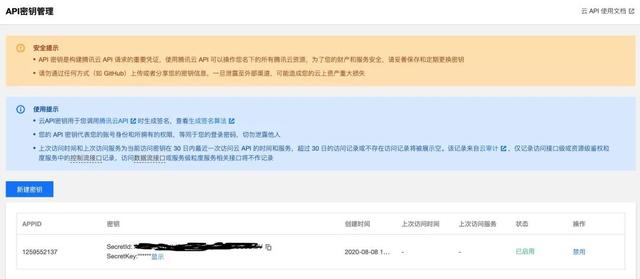
4.进入密钥管理界面,单击新建密钥,生成 SecretId 与 SecretKey,用于 API 调用时生成签名。
5.用Python调用接口进行语音合成,其中APP_ID、SECRET_ID、SECRET_KEY在上一步中获得,代码如下:
# coding=UTF-8
import requests
import wave
import json
import
import time
import collections
import urllib
import
import hmac
import hashlib
import uuid
import os
TCLOUD_APP_ID = XXXX
TCLOUD_SECRET_ID = "XXXX"
TCLOUD_SECRET_KEY = "XXXX"
OUTPUT_PATH = "./audio"
def generate_sign(request_data):
url = "tts.cloud.tencent.com/stream"
sign_str = "POST" + url + "?"
sort_dict = sorted(request_data.keys())
for key in sort_dict:
sign_str = sign_str + key + "=" + urllib.parse.unquote(str(request_data[key])) + '&'
sign_str = sign_str[:-1]
sign_bytes = sign_str.encode('utf-8')
key_bytes = TCLOUD_SECRET_KEY.encode('utf-8')
authorization = .b64encode(hmac.new(key_bytes, sign_bytes, hashlib.sha1).digest())
return authorization.decode('utf-8')
def text2wav(content):
request_data = {
"Action": "TextToStreamAudio",
"AppId": TCLOUD_APP_ID,
#返回音频格式:Python SDK只支持pcm格式
#pcm:返回二进制 pcm 音频,使用简单,但数据量大。
"Codec": "pcm",
"Expired": int(time.time()) + 3600,
#模型类型,1:默认模型
"ModelType": 1,
#主语言类型:
#1:中文(默认)
#2:英文
"PrimaryLanguage": 1,
#项目 ID,用户自定义,默认为0。
"ProjectId": 0,
#音频采样率:
#16000:16k(默认)
#8000:8k
"SampleRate": 16000,
"SecretId": TCLOUD_SECRET_ID,
"SessionId": str(uuid.uuid1()),
#语速,范围:[-2,2],分别对应不同语速:
#-2代表0.6倍
#-1代表0.8倍
#0代表1.0倍(默认)
#1代表1.2倍
#2代表1.5倍
#输入除以上整数之外的其他参数不生效,按默认值处理。
"Speed": 0,
"Text": content,
"Timestamp": int(time.time()),
#音色:
#0:亲和女声(默认)
#1:亲和男声
#2:成熟男声
#3:活力男声
#4:温暖女声
#5:情感女声
#6:情感男声
"VoiceType": 5,
#音量大小,范围:[0,10],分别对应11个等级的音量,默认值为0,代表正常音量。没有静音选项。
"Volume": 5,
}
signature = generate_sign(request_data)
# print(f"signature: {signature}")
header = {
"Content-Type": "application/json",
"Authorization": signature
}
url = "https://tts.cloud.tencent.com/stream"
# print(request_data)
r = requests.post(url, headers=header, data=json.dumps(request_data), stream = True)
# print(r)
i = 1
t = int(time.time() * 1000)
output_file = os.path.join(OUTPUT_PATH, f"{t}.wav")
print(f"generate audio file: {output_file}")
wavfile = wave.open(output_file, 'wb')
wavfile.setparams((1, 2, 16000, 0, 'NONE', 'NONE'))
for chunk in r.iter_content(1000):
if (i == 1) & (str(chunk).find("Error") != -1) :
print(chunk)
return ""
i = i + 1
wavfile.writeframes(chunk)
wavfile.close()
return output_file
if __name__ == "__main__":
print(text2wav("你好"))
也可参考官方提供的SDK
参考资料:
https://zhuanlan.zhihu.com/p/82278135
https://pypi.org/project/pyttsx3/
https://www.xfyun.cn/services/online_tts
https://cloud.tencent.com/product/tts/getting-started











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330