小编今天跟大家分享的文章是关于python基于主成分分析的客户信贷评级实战的,大家在学习python过程中要注意理论学习与实际案例操作相结合,这样才能更好地掌握。好了,跟小编一起来看具体内容吧!
文章来源: 早起Python
作者:萝卜
本文是Python商业数据挖掘实战的第5篇
前言
大样本的数据集固然提供了丰富的信息,但也在一定程度上增加了问题的复杂性。如果我们分别对每个指标进行分析,往往得到的结论是孤立的,并不能完全利用数据蕴含的信息。但是盲目的去减少我们分析的指标,又会损失很多有用的信息。所以我们需要找到一种合适的方法,一方面可以减少分析指标,另一方面尽量减少原指标信息的损失。
变量压缩的方法非常多,但百法不离其中,其实最根本的都是「主成分分析」(Primary Component Analysis,下简称PCA)。能够理解 PCA 的基本原理并将代码用于实际的业务案例是本文的目标,本文将详细介绍如何利用Python实现基于主成分分析的5c信用评级,主要分为两个部分:
引入
在正式开始原理趣析前,我们先从两个生活场景入手,借以更好的理解需要进行变量压缩的原因。
场景1:
上司希望从事数据分析岗位的你仅用两个短句就概括出以下数据集所反映出的经济现象

用几个长句都不一定能够很好的描述数据集的价值,更何况高度凝练的两个短句,短短九个指标就已经十分让人头疼了,如果表格再宽一些呢,比如有二三十个变量?
场景2
大学生讲究德智体美劳全面发展,学校打算从某学院挑选一两名学生外派进修数据分析,需要综合全面的考量学生素质。部分候选学生的个人情况如下:
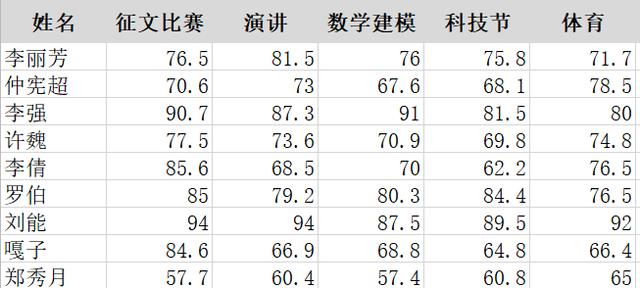
首先还是与场景1类似的问题,这些指标只是冰山一角,还没算上学生们其他领域的成绩,如果说在场景1中还可以以牺牲全面性来删除一些我们觉得关系不大的变量,比如我们猜测老板只会关注GDP与人均GDP这两个指标,那么场景2的背景便已经清晰地说明了需要综合地考虑变量,不能有生硬的去掉“体育”之类的操作。
信息压缩
如果把信息压缩这四个字拆成信息和压缩这两部分来看的话,便会呈现如下值得探究的问题:
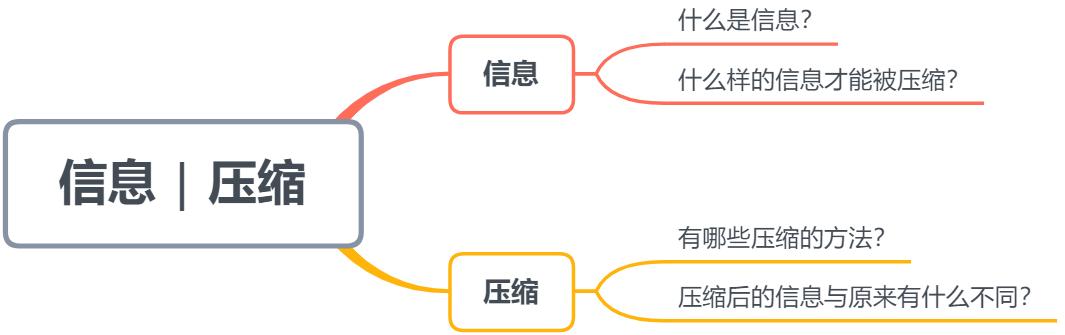
「信息压缩中的信息指什么?」
其实各种数据、变量都可被称为信息,而统计学家们常把方差当作信息。其实在做描述性统计分析的时候,只要能够表现我们数据的变异情况的统计量都可以被称作信息,如方差,极差等,只不过是极差会更好计算。以方差为例,方差变化越大,数据分布越分散,涵盖的信息就越多。
「什么样的信息/变量才能被压缩?」
-
只有相关性强的变量才能被压缩。如场景2的数学建模和科技节活动,都是学生们理科思维的体现方式,所以可以考虑把这两者合并成一个新的叫
“ 理科思维 ” 的变量,这样便可以不用两个变量都要费笔墨描述,关键是 “ 理科思维 ”
这个新的变量里面数学建模和科技节这两个旧变量的各自的占比是多少。(因为这里并没有因变量,所以这两个旧变量的权重系数无法简单的使用多元线性回归来完成)如果变量间的关系几乎是独立的却依然强制压缩(比如体育和演讲),则会大大加剧信息的缺失程度,这也是为什么
“ 压缩 ” 其实带有一丝迫不得已的意味,都是以尽可能损失最少的信息为前提。
-
主成分分析是只能针对连续变量来进行压缩,分类变量则不行。因为分类变量之间可以说是完全独立的,并没有正负两种相关性一说,如性别男和女之间就完全是独立的。如果一定也要将分类变量压缩的话,通常会对他们进行WOE转换(后续推文会提及),之后就可以愉快的进行压缩了。所以分类变量是没办法进行单独压缩的,因为没有对应的算法。有些人可能会直接对分类变量间进行卡方检验,然后把
p 值大的删去一些,这个其实应该被划分为手工的范畴,并不属于算法。
「有哪些压缩的方法?」
总的来说降维有两种方法,一种是特征消除,另一种是特征提取
-
特征消除:如上一问提到的采用卡方检验这样的非算法,又或者直接拍脑袋决策需要删掉哪些变量,但这可能会使我们丢失这些特征中的很多信息。
-
特征提取:通过组合现有特征来创建新变量,可以尽量保存特征中存在的信息。
PCA就是一种常见的特征提取方法,它会将关系紧密的变量们用尽可能少的新创建的变量代替,使这些新变量是两两不相关的。这就实现用较少的综合指标分别代表存在于各个变量中的各类信息。所以多元变量压缩思路的基础其实是相关分析。
「压缩后的信息与原来的有什么不同?」
我们需要明确的是,无论是主成分还是后续推文的稀疏主成分分析,都有一个问题:他们得到的主成分均没有什么业务含义,如果希望得到的压缩后的变量是有意义的,则可以考虑变量聚类。
压缩过程
下图为两个正态分布的变量间可能存在的三种关系的示意图,去正态分布和相关系数为 0.9 是为了从比较理想化的角度来解释变量压缩的步骤。
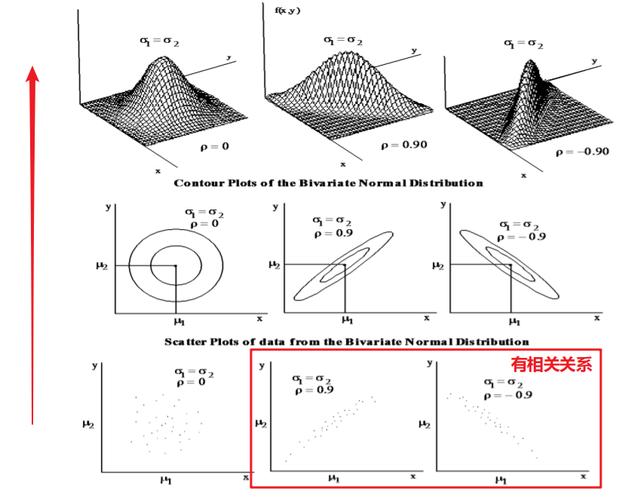
可以看到,若两变量间的关系是较强的正/负相关,用铅笔把散点图的范围圈起来的话呈现的都是一个较扁的椭圆;反之,完全独立的两个变量的分布更像是一个肥胖的圆形。关于压缩过程我们依旧对以下几个常见的问题进行解释。
「如何通过散点图理解信息压缩?」
直接看散点图只能判断出是否值得压缩,毕竟只有变量间具有一定的相关性才值得压缩。接下来将涉及到 PCA 中很重要的一个知识点:坐标轴旋转
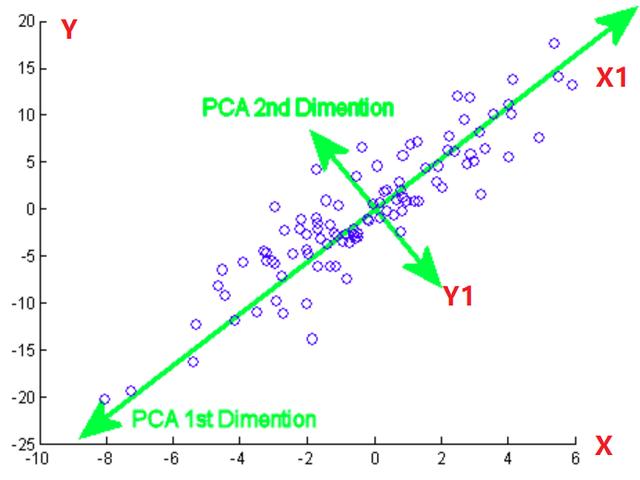
「旋转坐标轴的作用?」
旋转后的坐标轴与原坐标轴一样,都是正交(垂直)的。这样的旋转方式可以使两个相关的变量的信息在坐标轴上得到最充分的体现(如果以极差作为信息,则点在 X1 的投影范围最长)。之后便可从短轴方向来压缩,当这个椭圆被压扁到一定程度时,短轴上的信息就可以忽略不计,便达到了信息压缩的目的。
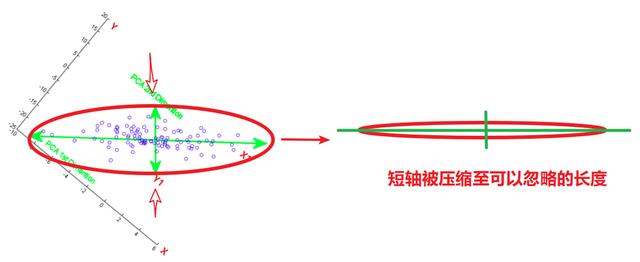
「如果有三个变量该如何压缩?」
三维的也是如此,只不过是由椭圆变成椭球(三个变量都相关)。步骤还是一样,找到最长轴后,在轴上做切面,切面一旦有了,便又回归到了二维的情况。这时可以找到次长轴和最短轴,这就可以依次的提取,当我们认为最短轴可以忽略不计的时候,就又起到了信息压缩的作用。
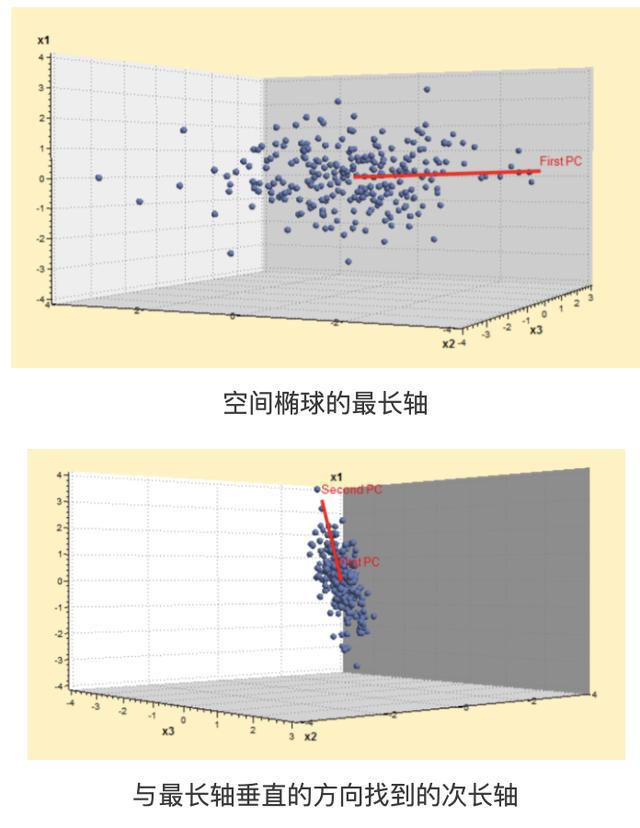
要注意的是如果呈球形分布,这说明变量间没有相关关系,没有必要做主成分分析,也不能做变量的压缩。
建模分析
前面已经说到,PCA后所得到的压缩的主成分并没有什么意义,比如5个变量压缩成2个主成分P1和P2。

这两个主成分中的组成等式为:
其中,等式右边的系数正负与否并没有什么意义,通常看绝对值即可。第一个主成分 P1中受五个变量的影响程度无明显差别,权重都在0.42 ~ 0.47间 主成分P2受第一个变量的影响最大,权重系数为0.83,受第三个变量影响最小,权重为0.14
那么如何知道应该压缩成几个主成分?PCA 的功能是压缩信息,压缩后的每个主成分都能够解释一部分信息的变异程度(统计学家喜欢用方差表示信息的变异程度),所以,只需要满足解释信息的程度达到一定的值即可。
-
计算每个成份因子
-
将不同成分因子所能解释的变异百分比相加 3. 得到的值被称之为累积变异百分比 4. PCA 过程中,我们将选择能使得这个值最接近于 1 的维度个数
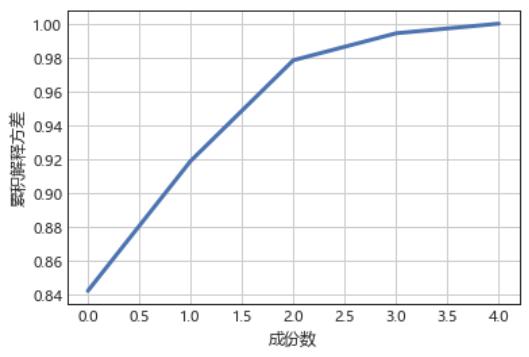
明显可以看出随着成分数目的增加,累积变异百分比逐渐增加。不建议使得累积百分比等于1,这将会导致有些主成分带来冗余信息,通常等于 0.85
就可以了。当然我们也可以选择两个主成分,因为当我们增加第三个主成分因子时,会发现增加它对于累积变异的百分比没有太大的影响。
Python实战
在正式开始 Python 代码实战前,简要了解主成分分析的运用场景是非常有必要的
-
综合打分:这种情况在日常中经常遇到,比如高考成绩的加总、员工绩效的总和排名。这类情况要求只出一个综合打分,因此主成分分析比较适合。相对于讲单项成绩简单加总的方法,主成分分析会赋予区分度高的单项成绩以更高的权重,分值更合理。不过当主成分分析不支持只取一个主成分时,就不能使用该方法了。
-
数据描述:描述产品情况,比如著名的波士顿矩阵,子公司业务发展状况,区域投资潜力等,需要将多变量压缩到少数几个主成分进行描述,如果压缩到两个主成分是最理想的。这类分析一般做主成分分析是不充分的,做到因子分析更好。
-
为聚类或回归等分析提供变量压缩:消除数据分析中的共线性问题,消除共线性常用的有三种方法,分别是:
-
同类变量中保留一个最有代表性的;
-
保留主成分或因子;
-
从业务理解上进行变量修改。
❝
案例背景:某金融服务公司为了了解贷款客户的信用程度,评价客户的信用等级,采用信用评级常用的5C(品质 Character,能力
Capacity,资本 Capital,抵押 Collateral,条件 Condition)方法, 说明客户违约的可能性。
❞
本次实战将围绕综合打分,即只选出一个主成分的情况来实现客户信用评级。
数据探索
首先导入相关包并进行探索性分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'})
# 设置中文字体的支持
df = pd.read_csv('loan_apply.csv')
df
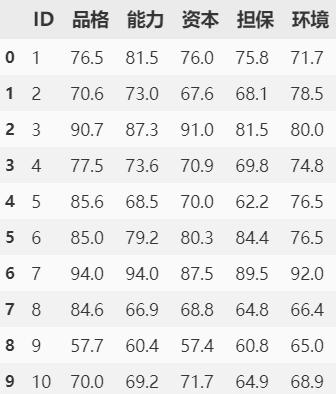
参数解释:
-
品格:指客户的名誉;
-
能力:指客户的偿还能力;
-
资本:指客户的财务实力和财务状况;
-
担保:指对申请贷款项担保的覆盖程度;
-
环境:指外部经济政策环境对客户的影响
进行主成分分析前,一定要对数据进行相关分析,因为相关性较低或独立的变量不可做PCA
# 求解相关系数矩阵,证明做主成分分析的必要性
## 丢弃无用的 ID 列
data = df.drop(columns='ID')
import seaborn as sns
sns.heatmap(data.corr(), annot=True)
# annot=True: 显示相关系数矩阵的具体数值
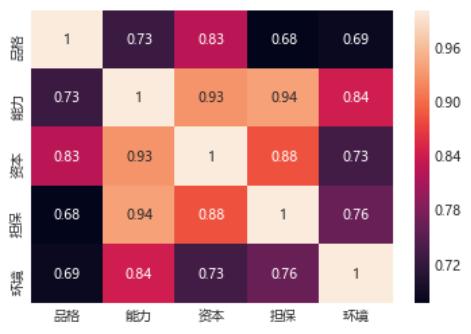
发现变量间相关性都比较高,大于0.7,有做PCA的必要
PCA 建模前,数据需要进行标准化,通常使用中心标准化,也就是将变量都转化成Z分数的形式,即偏离平均数的标准差个数,这样才能防止量纲问题给建模带来的影响。如身高-体重的量纲1.78-59与178-60在散点图上的显示会有比较大的区别!
# PCA 通常用中心标准化,也就是都转化成 Z 分数的形式
from sklearn.preprocessing import scale
data = scale(data)
使用sklearn进行PCA分析,注意:
-
第一次的n_components参数最好设置得大一些(保留的主成份)
-
观察explained_variance_ratio_取值变化,即每个主成分能够解释原始数据变异的百分比
from sklearn.decomposition import PCA
pca = PCA(n_components=5) # 直接与变量个数相同的主成分
pca.fit(data)
结果分析
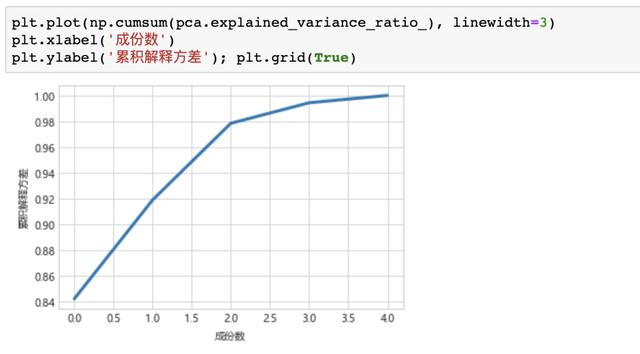
累计解释变异程度

明显看出第一个主成分就已经能够解释84%的信息变异程度了!
重新建模
重新选择主成分个数进行建模

主成分中各变量的权重分析
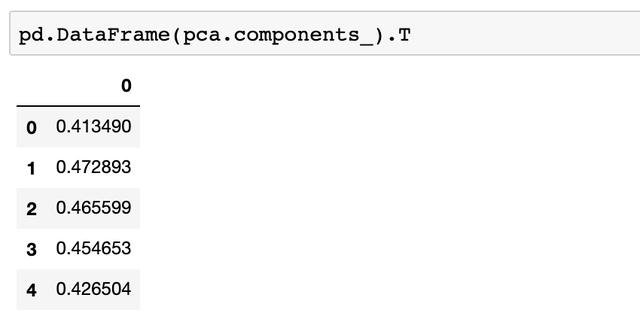
第一个主成分(解释了84% 的变异的那个)与5个自变量的系数关系可以理解成:「第一主成分 = 0.413 * 品格 + 0.47 * 能力 + 0.46 * 资本 + 0.45 * 担保 + 0.42 * 环境」。所以说生成的主成分除降维意义显著外,并没有什么其他的意义,并不好解释。
做出决策
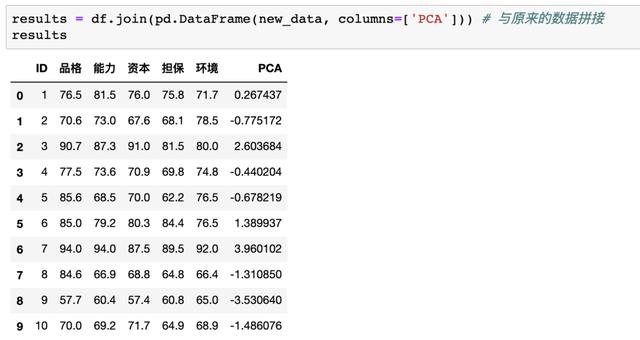
这里的new_data是上文代码pca.fit_transform(data)生成的降维后的数据,接着按照综合打分从高到低进行排序
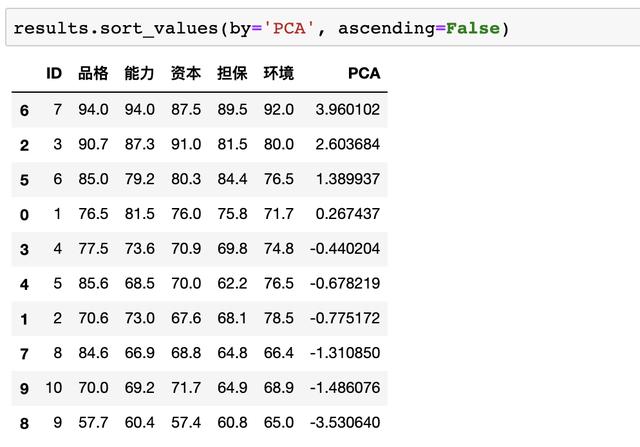
根据结果我们可以发现贷款给7号客户风险最低,给9号客户风险最高!
小结
本文通过生活实例引出为什么要进行信息的压缩与提炼,讲解了主成分分析 PCA
的原理与使用时的注意事项,并使用Python示范了完整的建模流程,给读者提供了参考和借鉴。另外,作为数据分析师必会的PCA在图像处理如人脸识别和手写数字识别等机器学习领域也有很广的运用,值得好好琢磨并熟练掌握。











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330