正在研究机器学习?我们帮你准备了27个小抄…
机器学习Machine
Learning有很多方面,当我开始研究学习它时,我发现了各种各样的“小抄”,它们简明地列出了给定主题的关键知识点。最终,我汇集了超过 20
篇的机器学习相关的小抄,其中一些我经常会翻阅,而另一些我也获益匪浅。这篇文章里面包含了我在网上找到的 27
个小抄,如果你发现我有所遗漏的话,请告诉我。
机器学习领域的变化是日新月异的,我想这些可能很快就会过时,但是至少在 2017 年 6 月 1 日时,它们还是很潮的。
如果你想要这些图表,你无需向我一样一张张下载,只需要从这里点击下载就可以了。
如果你喜欢这篇文章,那就分享给更多人,如果你想感谢我,就到原帖地址点个赞吧。
机器学习
这里有一些有用的流程图和机器学习算法表,我只包括了我所发现的最全面的几个。
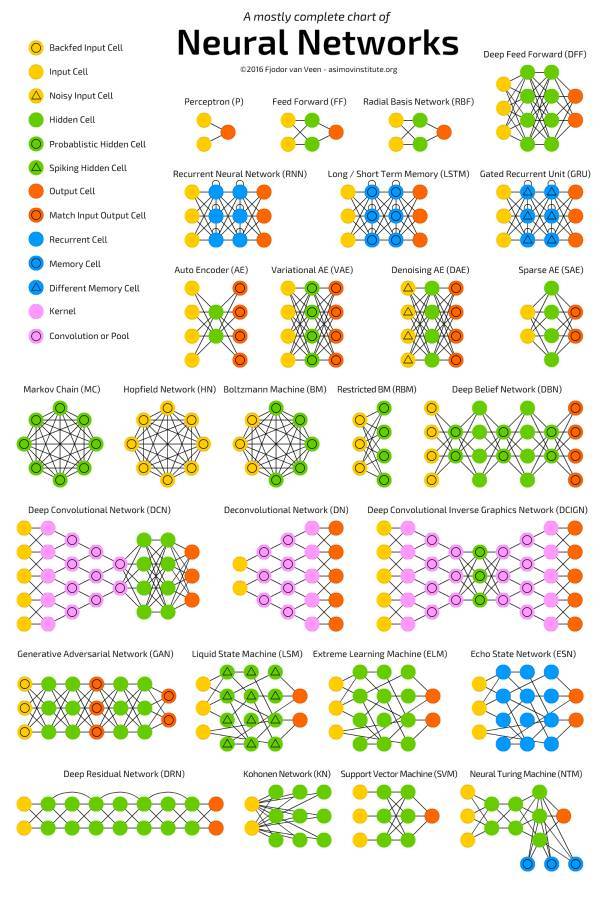
神经网络架构
来源: http://www.asimovinstitute.org/neural-network-zoo/
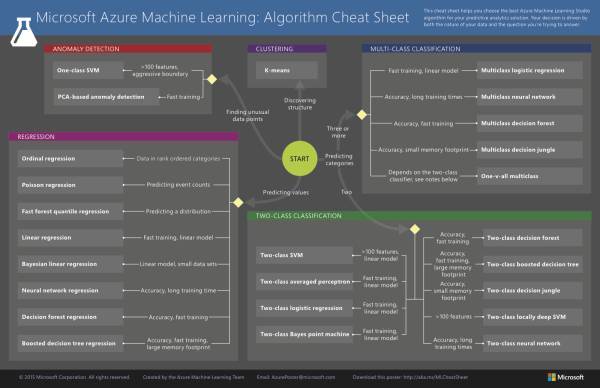
微软 Azure 算法流程图
来源: https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-cheat-sheet
用于微软 Azure 机器学习工作室的机器学习算法:
SAS 算法流程图
来源: http://blogs.sas.com/content/subconsciousmusings/2017/04/12/machine-learning-algorithm-use/
SAS:我应该使用哪个机器学习算法?:

算法总结
来源: http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms
机器学习算法指引:

来源: http://thinkbigdata.in/best-known-machine-learning-algorithms-infographic/
已知的机器学习算法哪个最好?:

算法优劣
来源: https://blog.dataiku.com/machine-learning-explained-algorithms-are-your-friend

Python
自然而然,也有许多在线资源是针对 Python 的,这一节中,我仅包括了我所见过的最好的那些小抄。
算法
来源: https://www.analyticsvidhya.com/blog/2015/09/full-cheatsheet-machine-learning-algorithms/

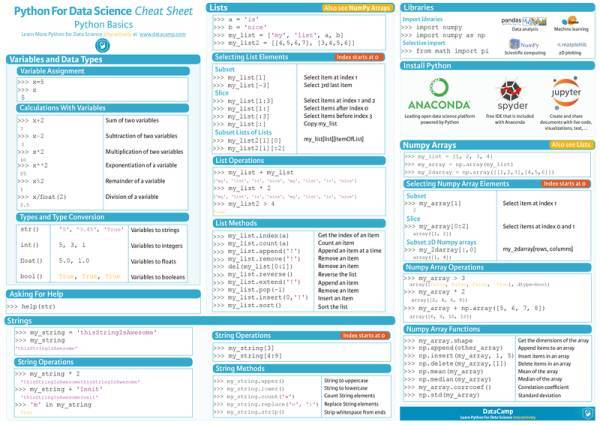
Python 基础
来源: http://datasciencefree.com/python.pdf

来源: https://www.datacamp.com/community/tutorials/python-data-science-cheat-sheet-basics#gs.0x1rxEA
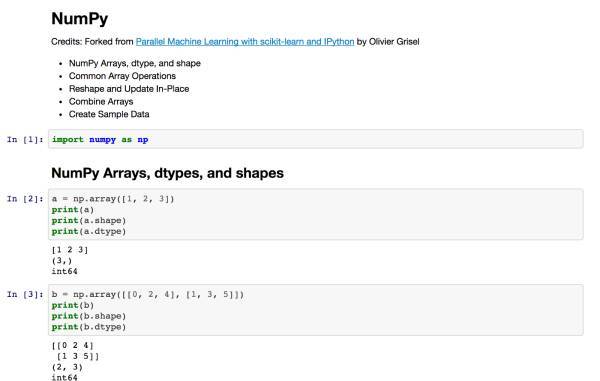
Numpy
来源: https://www.dataquest.io/blog/numpy-cheat-sheet/

来源: http://datasciencefree.com/numpy.pdf

来源: https://www.datacamp.com/community/blog/python-numpy-cheat-sheet#gs.Nw3V6CE

来源: https://github.com/donnemartin/data-science-ipython-notebooks/blob/master/numpy/numpy.ipynb
Pandas
来源: http://datasciencefree.com/pandas.pdf

来源: https://www.datacamp.com/community/blog/python-pandas-cheat-sheet#gs.S4P4T=U

来源: https://github.com/donnemartin/data-science-ipython-notebooks/blob/master/pandas/pandas.ipynb
Matplotlib
来源: https://www.datacamp.com/community/blog/python-matplotlib-cheat-sheet

来源: https://github.com/donnemartin/data-science-ipython-notebooks/blob/master/matplotlib/matplotlib.ipynb

Scikit Learn
来源: https://www.datacamp.com/community/blog/scikit-learn-cheat-sheet#gs.fZ2A1Jk

来源: http://peekaboo-vision.blogspot.de/2013/01/machine-learning-cheat-sheet-for-scikit.html
来源: https://github.com/rcompton/ml_cheat_sheet/blob/master/supervised_learning.ipynb
Tensorflow
来源: https://github.com/aymericdamien/TensorFlow-Examples/blob/master/notebooks/1_Introduction/basic_operations.ipynb
Pytorch
来源: https://github.com/bfortuner/pytorch-cheatshee
数学
如果你希望了解机器学习,那你就需要彻底地理解统计学(特别是概率)、线性代数和一些微积分。我在本科时辅修了数学,但是我确实需要复习一下了。这些小抄提供了机器学习算法背后你所需要了解的大部分数学知识。
概率
来源: http://www.wzchen.com/s/probability_cheatsheet.pdf

线性代数
来源: https://minireference.com/static/tutorials/linear_algebra_in_4_pages.pd

统计学
来源: http://web.mit.edu/~csvoss/Public/usabo/stats_handout.pd

微积分
来源: http://tutorial.math.lamar.edu/getfile.aspx?file=B,41,N

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330