《Python数据分析极简入门》
第2节 6 Pandas合并连接
在pandas中,有多种方法可以合并和拼接数据。常见的方法包括append()、concat()、merge()。
追加(Append)
append()函数用于将一个DataFrame或Series对象追加到另一个DataFrame中。
import pandas as pd
df1 = pd.DataFrame({'A': ['a', 'b'],
'B': [1, 2]})
df1
df2 = pd.DataFrame({'A': [ 'b', 'c','d'],
'B': [2, 3, 4]})
df2
df1.append(df2,ignore_index=True)
|
A |
B |
| 0 |
a |
1 |
| 1 |
b |
2 |
| 2 |
b |
2 |
| 3 |
c |
3 |
| 4 |
d |
4 |
合并(Concat)
concat()函数用于沿指定轴将多个对象(比如Series、DataFrame)堆叠在一起。可以沿行或列方向进行拼接。
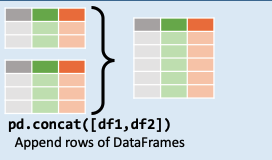 先看一个上下堆叠的例子
先看一个上下堆叠的例子
df1 = pd.DataFrame({'A': ['a', 'b'],
'B': [1, 2]})
df1
df2 = pd.DataFrame({'A': [ 'b', 'c','d'],
'B': [2, 3, 4]})
df2
pd.concat([df1,df2],axis =0)
|
A |
B |
| 0 |
a |
1 |
| 1 |
b |
2 |
| 0 |
b |
2 |
| 1 |
c |
3 |
| 2 |
d |
4 |
再看一个左右堆叠的例子
df1 = pd.DataFrame({'A': ['a', 'b']})
df1
df2 = pd.DataFrame({'B': [1, 2],
'C': [2, 4]})
df2
pd.concat([df1,df2],axis =1)
连接(Merge)
merge()函数用于根据一个或多个键将两个DataFrame的行连接起来。类似于SQL中的JOIN操作。

数据连接 1 (pd.merge)
先看一下 inner 和 outer连接
df1 = pd.DataFrame({'A': ['a', 'b', 'c'],
'B': [1, 2, 3]})
df1
df2 = pd.DataFrame({'A': [ 'b', 'c','d'],
'B': [2, 3, 4]})
df2
pd.merge(df1,df2,how = 'inner')
pd.merge(df1,df2,how = 'outer')
|
A |
B |
| 0 |
a |
1 |
| 1 |
b |
2 |
| 2 |
c |
3 |
| 3 |
d |
4 |
数据连接 2 (pd.merge)
再看左右链接的例子:
df1 = pd.DataFrame({'A': ['a', 'b', 'c'],
'B': [1, 2, 3]})
df1
df2 = pd.DataFrame({'A': [ 'b', 'c','d'],
'C': [2, 3, 4]})
df2
pd.merge(df1,df2,how = 'left',on = "A")
|
A |
B |
C |
| 0 |
a |
1 |
NaN |
| 1 |
b |
2 |
2.0 |
| 2 |
c |
3 |
3.0 |
pd.merge(df1,df2,how = 'right',on = "A")
|
A |
B |
C |
| 0 |
b |
2.0 |
2 |
| 1 |
c |
3.0 |
3 |
| 2 |
d |
NaN |
4 |
pd.merge(df1,df2,how = 'inner',on = "A")
pd.merge(df1,df2,how = 'outer',on = "A")
|
A |
B |
C |
| 0 |
a |
1.0 |
NaN |
| 1 |
b |
2.0 |
2.0 |
| 2 |
c |
3.0 |
3.0 |
| 3 |
d |
NaN |
4.0 |
补充1个小技巧
df1[df1['A'].isin(df2['A'])]
df1[~df1['A'].isin(df2['A'])]











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330