Excel 数据转存数据库的应用框架
随着企业IT系统的不断升级,很多企业有提升遗留系统的强烈需求。而整合遗留系统中的信息资源是其中最为关键的一步,进而可对信息进行数据挖掘等创新工作。本文涉及这
样的一个应用案例,企业的数据信息是以 Excel
文件作为其附件的方式,分散存储在企业不同的服务器上的,客户要求把这些文件里面的数据信息转存到数据库中。
读者可能也会遇到其它的应用场景,要求把 Excel 文件中的数据信息解析出来并存入到数据库中。
本文则提供了一种相对高效而智能的解决方案用以解析 excel 文件,并转存入数据库中。
Apache POI (POI-HSSF and POI-XSSF) 简介
POI
是 Apache 基金组织的子项目,POI(Poor Obfuscation Implementation)的目标就是提供一组 Java
API 来使得基于 Microsoft OLE 2 Compound Document 格式的 Microsoft Office 文件易于操作。
HSSF(Horrible Spreadsheet Format)是 POI 项目 Excel 文件格式(97 - 2007)的纯 java
实现,通过 HSSF,开发者可用纯 Java 代码来读取、写入、修改 Excel 文件。而 XSSF 则是 Excel 2007
OOXML(.xlsx) 文件格式的纯 java 实现。
本文主要涉及到应用 HSSF 和 XSSF 读取 Excel 文件中的数据。
Excel 文件到表的映射元数据定义
如
何把 Excel 表里面的数据映射为关系数据库表中的数据呢?关系数据库中的二维表是结构化的数据存储,而一个 Excel 文件的一个 Sheet
页面就可能包含多个可映射为数据库表结构的信息块。这个信息块可能很简单,也可能非常复杂。在本文中,针对 Excel
中信息块的实际情况,我们定义了几种 Excel
文件到数据库表的映射规则。这些规则就是我们用以解析的元数据。离开了这些元数据,我们就谈不上智能而高效的解析了。
映射规则一:单元格单一映射
Excel 表中的一个单元格(cell)对应关系数据库中某一个模式(Schema)下一张表(Table)的一个域(Field)。 如: A1 -> name
映射规则二:单元格组合映射
Excel
表中的多个单元格对应关系数据库中某一个模式(Schema)下一张表(Table)的一个域(Field)。 组合的方式是字符串的连接,比如
C1,C2, F3 -> address 。可以在映射规则里定义字符串的分隔符,例如,在上面的例子中是用逗号“,”组合的。
映射规则三:Excel 列的单一映射
Excel 表中的某一列的数据对应关系数据库中某一个模式(Schema)下一张表(Table)的一个域(Field)的数据。和前面两条规则相比较,该规则是将信息块中行的记录和数据库中表的行记录相对应起来的。例如 Column H -> 出口额。
映射规则四:Excel 列的组合映射
如
下图 1 所示,Excel
表中的多列的数据组合对应关系数据库中某一个模式(Schema)下一张表(Table)的一个域(Field)的数据。组合的方式是字符串数据的拼接,
分隔符也可以在映射规则中定义。例如 Column A, Column B, Column C -> 授信统计类型。
图 1. Excel 列的组合映射

以上四种规则比较常用,但由于 Excel 文件中信息块结构的复杂性,我们还可以根据需要定义其它的映射规则。(比如,Excel 文件以附近形式放置在 Domino 服务器上的,则可以结合 Domino 文档中的域来定义映射规则)
读者可能会问,如何自动的生成这些映射规则呢?完全自动的生成,是很难做到的。我们是应用 Symphony
Container,构建复合应用程序辅助“专家”来生成映射规则的。换句话说,一定有一个“专家”需要根据领域业务需求,完成数据库表的设计。在设计表的过程中,知
道那些 excel 文件里的信息块需要提取出来。基于这些知识,并利用一些辅助工具生成出映射规则元数据信息。
下面是基于 XML 语法结构的映射元数据片段,如清单 1 所示(如果是 Domino 的应用,可以创建 Domino 的文档用以保存映射元数据,进而应用 Notes 的 Java API 来解析)。
清单 1. 映射规则(Mapping Rule)示例
<?xml version="1.0" encoding="UTF-8"?>
<tns:mappingRule xmlns: tns=http://sample.com.cn/mappingRule
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://sample.com.cn/profile MPSchema.xsd ">
<excelType> 授信 </excelType>
<excelVersion>2008</excelVersion>
<rules>
<! — mapping rule type 1 -->
<rule1>
<sheetNumber>0</sheetNumber>
<sheetName>sheet1</sheetName >
<cellPos>A1</cellPos>
<DBschema>LitieDS</DBschema>
<DBTable>employee</DBTable>
<DBField>name</DBField>
</rule1>
<! — mapping rule type 2 -->
<rule2>
……
<cellPoses>C1,C2,F3</cellPoses>
<separator>,</separator>
<DBField>address</DBField>
……
</rule2>
<! — mapping rule type 3 -->
<rule3>
……
<sheetColumn>H</sheetColumn>
<DBField> 出口额 </DBField>
……
</rule3>
<! — mapping rule type 4 -->
<rule4>
……
<sheetColumns>A,B,C</sheetColumns>
<separator>,</separator>
<DBField> 授信统计类型 </DBField>
……
</rule4>
…
</rules>
</tns:mappingRule >
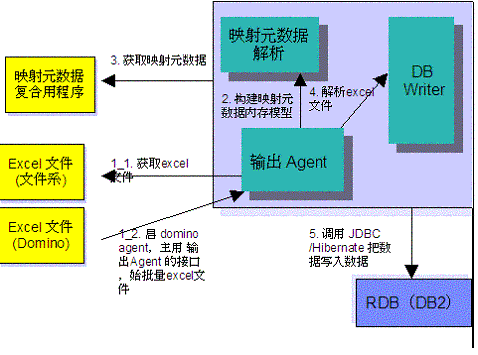
转换框架的介绍
如图 2 所示,本文介绍的框架程序有两个入口,针对的是两种情况(如果,这两种情况都不是读者所遇见的,比如 excel 文件是以大对象形式存储在 Oracle 数据库中,那么读者需要自己写解析器,拿到 excel 文件,本文略之)。
如
果 Excel 文件在文件系统中,则输出 Agent 模块是主程序。它首先获取文件系统中的 Excel 文件,然后可以启动多个线程去处理一批
Excel 文件。获取 Excel 文件的类型和版本号,根据 Excel 类型和版本号去获取用以描述 Excel
和关系数据库的映射元数据,就是上节我们讲述的内容。进而解析元数据构建元数据的内存模型。并且采用缓存机制,同一种类型,并且是同一种版本的
Excel 文件应用内存中已经构建好的元数据模型来解析,不必每次都去重新获取元数据。这样可以显著的提高性能。
如
果 Excel 文件是存放在 Domino 服务器上的,则需要一个 Domino Agent 程序主动调用输出 Agent
所提供的接口,批量的转换用解析程序从 domino 数据文档中解析出来的 excel 文件。
按照映射的元数据模型,应用
HSSF/XSSF 解析 Excel 的相应单元格、列,进而构造 SQL 语句(采用 JDBC 方式的模式)。在一个事务中提交该 Excel
文件所要执行的所有 SQL 语句, 保证一个 Excel 文件写入或者完全成功,或者出错回滚,并报告错误信息。如清单 2 所示。
图 2. 转换框架
清单 2. 插入 SQL 语句
private void insertSQLStatements(){
//Insert into database
List<String> sqlList = new ArrayList<String>();
CADataStore dataStore = new CADataStore();
if(tableSQLsMap!= null && tableSQLsMap.size()!= 0){
Iterator<String> itsql = tableSQLsMap.keySet().iterator();
while(itsql.hasNext()){
String tableName = itsql.next();
List<String> theList = tableSQLsMap.get(tableName);
sqlList.addAll(theList);
}
dataStore.write(sqlList); // 一个事务中完成所有 sql 语句的插入操作,事务是以一个 excel
// 文件为单位的,可涉及到若干个表
}
}
本
转换框架具有很大的可扩展性,我们不局限于遗留系统中已有的 Excel 文件信息,遗留系统可以继续使用,比如用户可以继续提交新类型的以 Excel
文件为存储格式的数据信息。系统可以定期不定期的进行转换工作。由图 2 可见,该转换框架清晰明了,是解决这类问题的一个通用模式。
在 Excel 解析的过程中,对于映射规则四,我们需要额外的算法支持。
Excel 列的组合映射的算法分析
在
映射规则四中,我们定义的规则是,Excel 表的多列对应关系数据库中表的一个域。组合的方式是字符串的连接。问题是 Excel
表中,有很多单元格是合并的单元格,对于合并的单元格我们需要进行特殊的处理,目的是使得组合后的数据内容比较准确的表达了原 Excel
文件信息块中的内容信息。清单 3 是 POI API 获取 Excel 一个给定单元格值的程序。
清单 3. 获取单元格的值
private static Object getCellValue(Cell cell) {
Object obj = null;
if(cell == null) return null;
switch (cell.getCellType()) {
case Cell.CELL_TYPE_STRING:
obj = cell.getRichStringCellValue().getString().trim();
break;
case Cell.CELL_TYPE_NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
obj = cell.getDateCellValue();
} else {
obj = cell.getNumericCellValue();
}
break;
case Cell.CELL_TYPE_BOOLEAN:
obj = cell.getBooleanCellValue();
break;
case Cell.CELL_TYPE_FORMULA:
obj = cell.getCellFormula();
break;
default:
}
return obj;
}
对
于合并的单元格,应用上面的 API,除了左上角第一个单元格有值外,其它已经合并起来的单元格返回值均是 null 。 HSSF 的解析 API
中对此有一个类叫 CellRangeAddress,该类用以记录 Excel
表中被合并(Merged)的一个区域。在程序中,我们只关心给定区域内的合并单元块,这样可以极大的提高性能,如清单 4 所示。
在清单 5 中,我们给出了如何获取某一行内指定列的组合值。
清单 4. 获取指定合并区域
public static List<CellRangeAddress> getCellRawRangeAddresses(HSSFSheet sheet1,
int startIndex, int endIndex, short[] indexes){ //indexes, excel column indexes
List<CellRangeAddress> resultList = new ArrayList<CellRangeAddress>();
for (int i = 0; i < sheet1.getNumMergedRegions(); i++) {
CellRangeAddress cellRA = sheet1.getMergedRegion(i);
int firstRow = cellRA.getFirstRow();
int lastRow =cellRA.getLastRow();
int firstCol = cellRA.getFirstColumn();
int lastCol = cellRA.getLastColumn();
if(lastRow >= startIndex && firstRow <= endIndex){
if(lastCol>= getMin(indexes) && firstCol <= getMax(indexes))
resultList.add(cellRA);
}
}
return resultList;
}
清单 5. 获取给定行的组合值
public static String getCominbedValue(HSSFSheet sheet1, Row row, short[] indexes ,
List<CellRangeAddress> limitedCellRAs){
StringBuffer resultBf = new StringBuffer(); // 用以存储最终结果
Map<CellPosition, CellRangeAddress> theMap =
new LinkedHashMap<CellPosition, CellRangeAddress>();
// 记录被合并的单元格所在的合并区域
int rowIndex = row.getRowNum();
Iterator<CellRangeAddress> itcra = limitedCellRAs.iterator();
while(itcra.hasNext()){
CellRangeAddress cra = itcra.next();
int firstRow = cra.getFirstRow();
int lastRow =cra.getLastRow();
if(rowIndex>= firstRow && rowIndex<= lastRow){
int firstCol = cra.getFirstColumn();
int lastCol = cra.getLastColumn();
for(int j=0; j<indexes.length;j++){
short index = indexes[j];
if(index >= firstCol && index <= lastCol){
theMap.put(new CellPosition(rowIndex,index),cra);
}
}
}
}
// 记录合并单元格所对应的列号
Iterator<CellPosition> itpos = theMap.keySet().iterator();
short[] compIndexes = new short[theMap.size()];
int count =0;
while(itpos.hasNext()){
CellPosition cellPos = itpos.next();
int colIndex = cellPos.getCol();
compIndexes[count]=(short)colIndex;
count++;
}
List<CellPosition> cachedList =new ArrayList<CellPosition>();
for(int i =0;i< indexes.length;i++){
if(!constains(compIndexes, indexes[i])){
// 如果不包含此列号,则对应的 cell 不是一个合并单元格,调用清单 2 中的方法获取其值
Cell cell = row.getCell(indexes[i]);
Object result= getCellValue(cell);
if(!StringUtility.checkNull(result))
resultBf.append( result+","); //$NON-NLS-1$
}else{
CellRangeAddress cellRA = theMap.get(new CellPosition (rowIndex, indexes[i]));
if(cellRA != null){
int cellrow = cellRA.getFirstRow();
int cellcol = cellRA.getFirstColumn();
CellPosition cPos = new CellPosition(cellrow,cellcol);
//If it is Not the cached CellRangeAddress object
if(!cachedList.contains(cPos)){
cachedList.add(cPos); // 放到缓存中,如果是同一个合并单元格,我们取其值一次
Object value = getMergedRegionValue(sheet1,cellRA); // 获得合并区域的值
resultBf.append(value +","); //$NON-NLS-1$
}
}
}
}
//resultBf 可能不包含任何数据
if(resultBf.length()>0 && resultBf.charAt(resultBf.length()-1)==','){
resultBf.deleteCharAt(resultBf.lastIndexOf(",")); //$NON-NLS-1$
}
return resultBf.toString();
}
本
文的解决方案不局限于 IBM DB2 数据库,同时支持 MySQL
等若干数据库。针对不同数据库的数据类型,解析框架会动态的加载相应的类型配置文件,并对解析到的 Excel 信息作相应的修整(比如:DB2
数据库某一字段的数据类型要求是 decimal 的 , 如果解析器取到的 excel
相应的内容是字符串格式的话,那么需要进行转换,并保证一定的容错性),从而保证生成正确的 SQL 语句信息。
小结
本
文提供了一种解决Excel数据转存数据库的通用解决方案。重点介绍了几种映射规则,这些规则都是最基本的,也是最常用的,读者可以根据需要,基于此而设计更复杂的映射规则。同时本
文也着重介绍了,映射规则四的一些实现算法,希望能够为被这类问题所困扰的同志们提供一些有价值的参考。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330