数据挖掘 SPSS Modeler 脚本功能的应用场景和编写技巧
数据挖掘软件 IBM SPSS Modeler 以用户界面友好、可视化功能强大著称。关于其脚本功能,参考资料很少。作者认为,脚本功能实际上旨在实现数据处理和分析建模过程的自动化。在需要动态改变数据处理过程、数据流自动执行和自动执行批量任务等应用场景下,必须补充编写一些脚本才能完成某些特定功能。所以,脚本功能是用户界面的必要补充,而不仅仅是用户界面鼠标操作功能的代码化。
SPSS Modeler 自带的脚本编写用户指南没有按照脚本功能的常用应用场景组织内容,这给脚本编写人员参考查阅造成一定的不便。同时,缺少完整的实用的例子,给出的例子多数是模拟用户界面上的常用操作。而实际情况是编写脚本通常是为了补充用户界面上很少使用或者不能实现的功能。作者就经常为找不到可以参考的例子而苦恼。
本文首先介绍用户界面上无法或者不便实现而必须编写脚本的常见的五种应用场景。每种场景下均给出完整的应用实例,重点介绍脚本编写的方法和技巧。在第二节,基于作者经验,总结了编写脚本的常用技巧。本文所附的实例均来自实际项目,且在 SPSS Modeler 15.0 环境下测试通过。
脚本功能的应用场景
什么情况下需要脚本功能?根据作者的经验,遇到下列情况应考虑使用脚本功能:需要重复执行某些数据处理;需要动态改变数据处理的过程;数据流最终需要部署到第三方环境;数据流需要自动执行 ( 而不是鼠标操作执行 );需要批量修改已有的数据流或者自动执行批量任务。
重复执行的数据处理
我们知道,Modeler 数据流默认都是顺序执行的,多个节点的依次连接而成的数据流提前指定了数据处理的顺序。然而,实际建模中经常会遇到部分数据流需要重复多次执行,且可能带参数,这时手工执行就很不方便。同时,可能需要根据某个变量的取值重复执行一段数据流 ( 实现动态循环 ),这种情况下就必须借助脚本来实现。
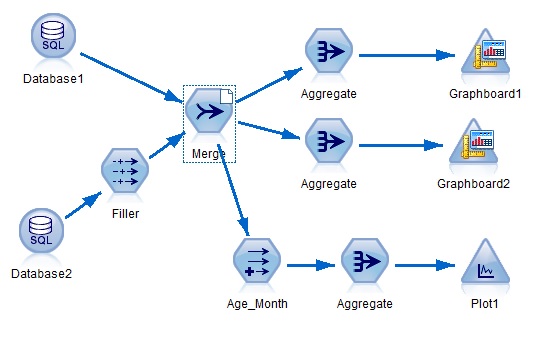
图 1 所示的数据流来自是一个预测产品销售的时间序列模型。需要分别预测每个销售分支机构 (IMT) 在未来一个季度的销售总额。当销售机构较多 (=21) 且动态变化时,需要根据 Table 节点 IMT_List 的输出结果,循环多次逐行取出 IMT 的取值,然后根据此值设置 Select1 和 IMT 节点,从而实现动态的重复执行的数据处理。这里的主要技巧是从 Table 节点循环取数。
图 1. 从 Table 节点循环取数

点击查看大图
图 1 中方框内的三个节点是脚本涉及的主要部分,对应的脚本内容如下:
清单 1 脚本内容 - 从 Table 节点循环取数
清单 1. 脚本内容 - 从 Table 节点循环取数

脚本编写的要点:执行 Table 节点读取所有的循环变量取值。利用 Result 对象的 output 属性和 Value 命令逐个读取循环变量的取值。使用 set 命令为多个节点动态赋值。
动态改变的数据处理过程
SPSS Modeler 数据流默认都是顺序执行的,多个节点的依次连接而成的数据流预先指定了数据处理过程。如果需要改变顺序执行为根据条件执行不同的流分支,则需要使用脚本 if...then...else... 命令。
下面的实例来自一个销售绩效评估项目,需要根据用户命令行参数的设置自动选择执行不同的数据流分支。具体来说,根据命令行参数,自动选择是否重新训练模型和根据不同季度选择不同的数据调整方法。
图 2. 根据命令行参数选择是否训练模型和季度调整方法

这个数据流在用户界面上调试时,不需要脚本,但是当部署完成集成到生产环境下自动执行时,就必须编写一些脚本以实现根据命令行参数动态选择不同的数据处理过程。本例的脚本如下:
清单 2. 带命令行参数的脚本

脚本编写的要点:使用 if...then...else... 命令,结合 CLEM 表达式和脚本参数,实现根据命令行参数动态选择不同的数据处理过程。
部署到第三方环境的数据流
构建好的数据流可能需要部署到第三方环境下使用。此时,数据流的执行往往不同于 SPSS Modeler 环境,有些情况下必须编写一点脚本,以实现预设的功能。
最简单的部署数据流的方法是使用 SPSS Modeler 批处理方式 (Batch Mode) 在第三方环境通过执行批命令来执行数据流。另外一种常用的部署方法是使用 Solution Publisher 在第三方环境执行数据流。下面就这两种部署方法分别给出一个应用实例。图 3 是一个资产效能优化项目中展示变压器报警分布情况的数据流。
图 3. 部署到第三方环境的数据流 (Batch Mode)
清单 3. 批处理方式部署

在用户界面上操作时不需要右边图示的脚本,但如果需要把这个流文件部署到第三方环境执行时,就必须增加这些脚本,且必须设置为与数据流同步执行 ( 选择 Run this script)。否则会提示输入数据库源节点的 Password 且不会自动执行三个图形输出节点。对应的执行这个数据流的批命令文件的内容如下:
批处理命令
...\clemb.exe -hostname IP -port 28052 -username UN -password PW -stream "...\Alarm Distribution Pattern Transformer.str" -execute -server -appendlog
下面的例子是一个资产效能优化项目中预测铁路设备故障的数据流。
图 4. 部署到第三方环境的数据流 (Solution Publisher)
清单 4. Solution Publisher 部署

这些脚本在部署环境下执行必须编写,否则提问密码,而且不能更新模型和输出预测结果。所以,用户界面下正常执行的数据流,在完成部署并自动执行的情况下,有些功能必须借助脚本来实现。特别需要注意的是:如果没有 insert model 这行脚本,模型就不能正常更新。没有脚本 execute 'Alarm Rail',预测结果就不能输出到指定的数据库表。对应的调用 Solution Publisher 执行这个数据流的批命令文件的内容如下:
批处理命令
"...\modelerrun.exe" -p "...\Alarm_Prediction_Rail.par" "...\Alarm_Prediction_Rail.pim"
自动执行的数据流
构建好的数据流可能需要部署到正式的生产环境,这时通常需要定期地自动执行这些数据流。直接复制用户界面调试好的数据流 ( 手工执行 ),当在生产环境自动执行时,有些功能就可能不能实现。
自动执行数据流有三种模式:Batch 模式、Client 模式和 Solution Publisher 模式。对应的可执行文件分别为:clemb.exe、modelerclient.exe 和 modelerrun.exe。前两种模式的典型命令行命令如下:
命令
clemb/modelerclient -server -hostname myserver -port 80 -username dminer -password 1234 -stream mystream.str -execute
对于 Solution Publisher 模式,在 Command Line 窗口下的执行命令如下:
命令
modelerrun – p *.par *.pim
当需要自动执行数据流时,原先在用户界面上调试好的,即手工执行的数据流可能需要补充一些脚本以实现指定的功能。例如,建模节点的自动执行、模型节点的自动更新、导出类节点 (Export) 的结果导出等都需要编写脚本。
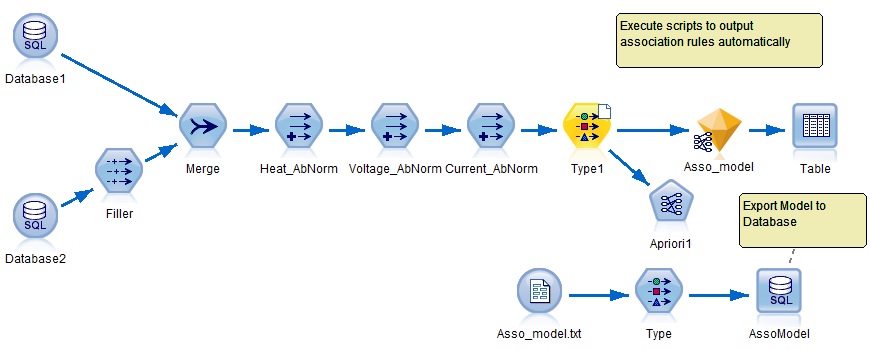
图 5 所示是一个资产效能优化项目中挖掘变压器失效与 DCS 监控数据异常的关联规则的数据流。这个数据流需要使用 Solution Publisher 部署到第三方环境自动执行,同时需要输出关联规则到数据库。由于 Solution Publisher 只支持二维数据的输出而不能输出关联规则模型本身,所以难点在于如何自动更新模型并输出关联规则模型本身的结果到 Oracle 数据库表,这就需要编写脚本。这个实例的特点是同时实现了建模节点的自动执行、模型节点的自动更新和导出节点的结果保存。
图 5. 关联规则的自动输出
点击查看大图
清单 5. 关联规则自动输出的脚本

脚本编写的要点:使用 set 命令提前设置数据库密码。使用 export model 命令输出关联规则模型为纯文本文件。使用 Export 节点把纯文本格式的关联规则输出到数据库。
自动执行的批量任务
实际应用中可能会遇到需要批量修改已有的数据流,以提高模型构建效率或者适用不同的客户项目。例如,可能需要把所有字段名修改为大写字母。手工修改对于节点或字段较多时就不方便。
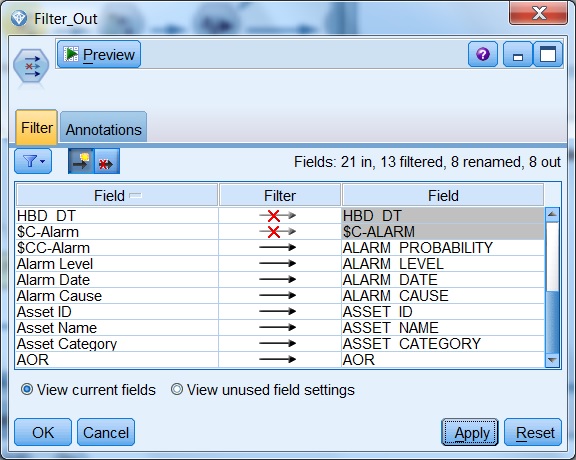
下面的例子来自一个资产效能优化项目。以前调试好的数据流,原先数据导出到 Excel 表,现在客户环境发生变化需要导出到 Oracle 数据库。由于 Oracle 数据库的库表名称和字段名称必须用大写字母且不能有空格,所以需要批量替换所有的 Filter 节点的小写字母和中间空格。手工修改对于 Filter 节点较多或字段较多时不方便,可以使用脚本自动修改。下面一段脚本,可以实现类似于图 6 所示的 Filter 节点 (Filter_Out) 的所有 Filter 节点的字段名称的大写转换和空格到下划线的转换。
图 6. 字段名称大写和空格的自动转换
清单 6. 批量任务的脚本

脚本编写的要点:搜索当前数据流中包含的所有 Filter 节点,然后逐个节点对新的字段名称逐个进行大写转换,并把中间空格替换为下划线。使用了 set 命令、循环语句和条件语句。
脚本编写的常用技巧
脚本运行不同于鼠标操作的情况
SPSS Modeler 脚本功能是辅助的,鼠标操作是其基本的使用方式。所以,有些看似功能类似的脚本在实际运行时的效果不同于鼠标操作。常见情况可分为三种:
• 脚本中使用的节点需要重新命名。不同于鼠标操作模式,在运行脚本时不能出现重名的节点,否则报错。
• 建模节点的脚本执行不会自动更新模型节点 (Nugget)。例如,图 5 所示脚本的命令 execute 'Apriori1'仅执行建模节点'Apriori1'并把建好的模型节点放到管理器,而不自动更新工作区的模型节点,需要编写脚本把模型节点插入 ( 使用命令 insert model)。
• 使用脚本执行数据流时,末端的图形或数据的输出节点不会自动执行。例如,本文“1.3 部署到第三方环境的数据流”一节图 3 所示的例子,在用户界面上,点击按钮“运行当前流”(Run the current stream),所有末端的输出节点自动执行,但当部署到第三方环境执行这个数据流时,就需要在这个数据流上附加脚本才能完成输出。
脚本编写的常用技巧
屏蔽文件覆盖的提问:脚本自动执行时不希望中间跳出窗口提问是否覆盖文件。这个功能没有对应的脚本命令,只能使用菜单改变该数据流的用户选项 (Tools...Options...User Options),不选 Warn when a node overwrites a file。
调试方法:没有提供调试功能,只能点击按钮 Run selected lines only,选择部分脚本运行。
自动刷新数据源节点:当原始数据改变时,需要刷新对应的数据源节点。使用命令 set ^stream.refresh_source_nodes = True 实现所有数据源节点的自动刷新。
屏蔽数据源密码提问:对应通过 ODBC 连接的数据库数据源,数据流自动执行时会提问密码。屏蔽这种提问的命令:set 'Database1':databasenode.password = "mypassword"
模型节点的自动更新:不同于鼠标操作,脚本执行建模节点不会自动更新对应的模型节点。需要使用 insert model 命令更新模型。如果需要同时更新多个模型节点,还需使用 duplicate 命令。例如,下列脚本根据建模节点 AutoNumeric 的执行结果,自动更新 Actual2 和 Actual3 两个模型节点:
execute 'AutoNumeric'
insert model Actual2 connected between 'Type2':typenode and 'AFFV_AR_Q1':derivenode
duplicate Actual2 as Actual3 connected between 'Type3':typenode and 'Filter3':filternode
清除已有的模型节点:常用命令有三种,注意它们的区别。
delete Actual2 ( 命令 delete NODE) 从工作区上删除模型节点;
clear generated palette 清除管理器上的所有模型节点;
delete model Actual2 清除管理器上而不是删除工作区的模型节点。
高级脚本功能需要使用对象 (Object):常用的对象有四种:Output; Node; Model; Result。每类对象都有一些专用的命令用于定义和检索这些对象,例如 get output; execute 'Node1'; export model; value 'Result1' at Row1 Column1。详细命令参见用户指南第四章内容 (Scripting Commands)。例如,根据 Table 节点的输出读取循环变量,就可使用 Result 对象的 value 命令。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330