掌握机器学习技术从这些编程语言和程式库开始
在我们之前分享的文章《一名合格的机器学习工程师需要具备的5项基本技能,你都get了吗?》收到了读者的热烈响应。在这片广受赞誉的文章当中我们向大家介绍了成为机器学习牛人所需具备的关键技能。现在,我们将来自读者关于上一篇文章的问题进行汇总,发现其中大家最关心的就是:掌握机器学习技能到底需要学会哪一种编程语言?
这个问题的答案或许会让你大跌眼镜——掌握哪一种编程语言都无关紧要!
因为只要你熟悉机器学习库以及你所使用编程语言的工具,这时候语言本身并不是很重要的问题。不同的编程语言具有各种类型的机器学习程式库。在选择编程语言及其工具的时候,你一定要以你在公司中职位的作用以及你正在努力完成的任务为选择参考对象,这样才能让你的工作成效更胜一筹。
R
R语言,是一种专门为统计计算目的所创建的编程语言,R语言在处理大规模数据挖掘、可视化和报告方面的优势无人能及。你可以轻松的获取大量的软件包,这些软件包可以让你运用绝大多数的机器学习算法、统计测试以及分析过程。这种编程语言本身具有非常优雅的特性,虽然在表述关系、转换数据以及在执行并行运算时的句法结构让人难以捉摸。
从KDNuggets最近发起的一份调查报告当中我们可以看到,尽管Python已经在过去的两年中积累了很高的人气,但是R语言仍是2015年度在数据分析、挖掘和数据科学领域内最受欢迎的一种编程语言。
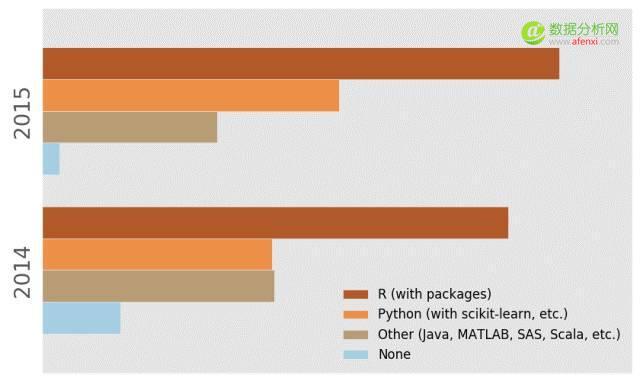
KDNuggets2015年度民众调查:分析、数据挖掘数据科学任务所用的基本编程语言
MATLAB
由于MATLAB具备非常强悍的计算技术,包括执行复杂的数学表达式、丰富的代数与微积分支持功能、符号计算法以及适用于从数字信号处理到计算生物学等领域的大量工具包,因此MATLAB深受学术机构的青睐。这种语言经常被用来创建新的机器学习算法原型,在某些特定的情况中,可以形成完整的解决方案。这种语言也为商业用途的项目提供大量的许可证,但是仍然值得我们使用这种编程方式,因为它可以大大地节省科研开发的精力。虽然Octave拥有与MATLAB几乎相近的语法结构,并也可以作为MATLAB的代替工具,但是前者的工具箱数量有限并且其集成开发环境还远不如后者成熟。
Python
尽管Python是一种多用途的编程和脚本语言,但是仍不能妨碍它俘获了很多数据科学家和机器学习工程师的芳心。和R语言或者MATLAB不同的是,Python的数据处理和科学计算习惯用语并非建立在语言本身,而是建立在NumPy、SciPy和Pandas扩展包之上,这些扩展包以一种更容易实现的语法结构提供和Python相同功能的编程语言。
scikit-learn, Theano以及TensorFlow这种专业的机器学习程式库让你拥有使用分布式计算基础设施培训各种机器学习模型的能力。这些程式库的效率关键代码通常还是通过Python的封装包或者API插件包,经由C/C++或者由 Fortran编写而成。
Python生态系统的最大优势在于它可以简单地将复杂的端到端的产品或者服务整合到一起,比如使用了Django 或者Flask的网页应用程序,或者使用了PyQt的桌面应用程序,乃至使用了ROS的代理机器人。
Java
Java是软件工程师的编程语言之选,因为它可以整洁并持续地执行以目标为导向的编程项目,以及使用JVM系统的独立平台。为了清晰性和可靠性,它牺牲了简洁和灵活度,因此它在执行关键的企业系统方面的能力广受好评。为了维持相同水平的灵活性并避免乱写错误的接口,那些一直都在使用Java的公司为了开辟他们在机器学习方面的需求更倾向于坚持自己的选择。
除了可以提供用于分析和原型设计的用途之外,Java还有很多种用于建造大规模分布式学习系统的非常棒的选择,比如asSpark+MLlib、Mahout、H2O和Deeplearning4j。在类似Hadoop/HDFS这样工业化标准数据处理和储存系统的协同作用下,这些程序库和架构可以很好地发挥作用。
C/C++
C/C++是操作系统插件和网络协议这种低层级软件的理想选择,因为对于这些软件而言,计算速度和内存效率至关重要。也是由于同样的原因,它也是执行机器学习程序最受欢迎的手段。但是由于这种语言缺少数据处理所需的地道语言表达方式,并且内存管理所需的开销很大,导致了该语言不适合初学者,而且对于开发完整的端到端的系统而言这种编程语言反而会成为一种负担。
一旦植入了类似智能轿车、智能装置以及传感器这样的系统,我们就必须使用C/C++编程。在其他情况下,由于基础设施和特定应用程序的代码已经是现成的了,所以这种语言就显得特别的便利。在任何一种案例当中,C/C++语言从来不会缺少机器学习程序库,比如LibSVM, Shark和mlpack。
企业解决方案
除了这些语言和程序库之外,在受到更多监管的数据处理环境中,还有很多其他用于统计建模的商业产品和应用了机器学习模型的商业分析技术。包括RapidMiner、IBM SPSS、SAS+JMP和Stata在内的这些产品提供了可靠并且端到端的数据分析解决方案,同时还具备可供编程使用的API接口或者脚本语法。
最近在这个领域当中有新增了很多以云为基础的机器学习为服务的平台( Machine-Learning-as-a-Service platforms),比如Amazon Machine Learning、Google Prediction、IBM Watson和Microsoft AzureMachine Learning。这些平台可以帮助你扩大处理大量数据的学习解决方案,并快速地对不同的模型进行试验。只要是具备非常牢固的机器学习技术基础,那么使用新的产品或者平台工作就像学习使用一种新工具一般简单。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330