基于树的建模-完整教程(R & Python)
基于树的学习算法被认为是最好的方法之一,主要用于监测学习方法。基于树的方法支持具有高精度、高稳定性和易用性解释的预测模型。不同于线性模型,它们映射非线性关系相当不错。他们善于解决手头的任何问题(分类或回归)。
决策树方法,随机森林,梯度增加被广泛用于各种数据科学问题。因此,对于每一个分析师(新鲜),重要的是要学习这些算法和用于建模。
决策树、随机森林、梯度增加等方法被广泛用于各种数据科学问题。因此,对于每一个分析师(包括新人),学习这些算法并用于建模是非常重要的。
本教程是旨在帮助初学者从头学习基于树的建模。在成功完成本教程之后,有望初学者成为一个精通使用基于树的算法并能够建立预测模型的人。
注意:本教程不需要先验知识的机器学习。然而,了解R或Python的基础知识将是有益的。开始你可以遵循Python 和R的完整教程。
1.决策树是什么?它是如何工作的呢?
决策树是一种监督学习算法(有一个预定义的目标变量),主要是用于分类问题。它适用于分类和连续的输入和输出变量。在这种方法中, 基于在输入变量中最重要的分配器/微分器的区别,我们把人口或样本分成两个或两个以上的均匀集(或群体)。
例子:-
假设我们有30名学生作为样本,包含三个变量:性别(男孩/女孩),班级(IX/ X)和身高 (5到6英尺)。这30名学生中超过15人在闲暇时间打板球。现在,我想创建一个模型来预测谁会在休闲期间打板球。在这个问题上,我们需要根据非常重要的三个输入变量来隔离在闲暇时间打板球的学生。
这就是决策树的帮助,它根据三变量的所有值和确定变量隔离学生,创造最好的同质组学生(这是异构的)。在下面的图片中,您可以看到相比其他两个变量性别变量是最好的能够识别的均匀集。
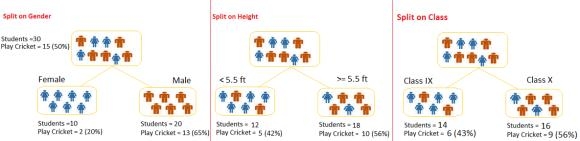
正如上面提到的,决策树识别最重要的变量,它最大的价值就是提供人口的均匀集。现在出现的问题是,它是如何识别变量和分裂的?要做到这一点,决策树使用不同的算法,我们将在下一节中讨论。
决策树的类型
决策树的类型是基于目标变量的类型。它可以有两种类型:
1.分类变量决策树: 有分类目标变量的决策树就称为分类变量决策树。例子:在上述情况下的学生问题,目标变量是“学生会打板球”,即“是”或“否”。
2.连续变量决策树: 有连续目标变量的决策树就称为连续变量决策树。
例子:假设我们有一个问题,预测客户是否会支付他与保险公司续保保险费(是 / 否)。在这里我们知道客户的收入是一个重要的变量,但保险公司没有所有客户收入的详细信息。现在,我们知道这是一个重要的变量,我们就可以建立一个决策树来根据职业、产品和其他变量预测客户收入。在这种情况下,我们的预计值为连续变量。
决策树相关的重要术语
让我们看看使用决策树的基本术语:
1.根节点:它代表总体或样本,这进一步被分成两个或两个以上的均匀集。
2.分裂:它是将一个节点划分成两个或两个以上的子节点的过程。
3.决策节点:当子节点进一步分裂成子节点,那么它被称为决策节点。
4.叶/终端节点:节点不分裂称为叶或终端节点。
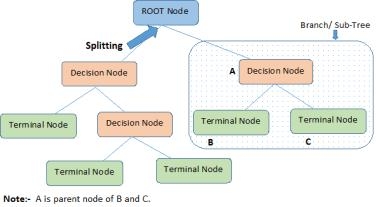
5.修剪:当我们删除一个决定节点的子节点,这个过程称为修剪。也可以说相反分裂的过程。
6.分支/子树:整个树的子部分称为分行或子树。
7.父节点和子节点:被分为子节点的节点称为父节点,就像子节点是父节点的孩子。
这些是常用的决策树。正如我们所知,每个算法都有优点和缺点,下面是一个人应该知道的重要因素。
优势
1.容易理解:决策树输出是很容易理解的,即便是在那些从属于以非思辩背景的人。它不需要任何统计知识来阅读和解释它们。它的图形表示非常直观,用户可以很容易地理解他们的假说。
2.有用的数据探索:决策树是用一种最快的方式来识别最重要的变量和两个或两个以上变量之间的关系。在决策树的帮助下,我们可以创建新变量或有更好的能力来预测目标变量的功能。您可以参考文章(技巧提高的力量回归模型)这样一个方法。它也可以用于数据探索阶段。例如,我们正在研究一个问题,在数以百计的变量信息中,决策树将有助于识别最重要的变量。
3.较少的数据清洗要求: 相比其他建模技术它需要较少的数据清洗。它的公平程度不受异常值和缺失值的影响。
4.数据类型不是一个约束:它可以处理数值和分类变量。
5.非参数方法:决策树被认为是一种非参数方法。这意味着决策树没有假设空间分布和分类器结构。
缺点
1.过拟合: 过拟合是决策树模型最现实的困难。这个问题只能通过设置约束模型参数和修剪来解决 (在下面详细讨论)。
2.不适合连续变量:在处理连续数值变量时,决策树在对不同类别变量进行分类时失去信息。
2.回归树vs分类树
我们都知道,终端节点(或树叶)位于决策树的底部。这意味着我们通常会颠倒绘制决策树,即叶子在底部根在顶部(如下所示)。

这些模型的功能几乎相似,让我们看看回归树和分类树主要的差异和相似点:
①用于回归树的因变量是连续的,而用于分类树的因变量是无条件的。
②在回归树中,训练数据中的终端节点的价值获取是观测值落在该区域的平均响应。因此,如果一个看不见的数据观察落在那个区域,我们将它估算为平均值。
③在分类树中, 训练数据中终端节点获得的价值是观测值落在该区域的模式。因此,如果一个看不见的数据落在该地区,我们会使用众数值作为其预测值。
④这两个树将预测空间(独立变量)划分为明显的非重叠区域。为了简单起见,你可以认为这些区域是高维盒子或箱子。
⑤这两种树模型都遵循的自上而下的贪婪的方法称为递归二分分裂。我们之所以叫它为“自上而下”,是因为当所有的观察值都在单个区域时它先从树的顶端开始,然后向下将预测空间分为两个分支。它被称为“贪婪”,是因为该算法(寻找最佳变量可用)关心的只有目前的分裂,而不是构建一个更好的树的未来的分裂。
⑥这个分裂的过程一直持续到达到一个用户定义的停止标准。例如:我们可以告诉该算法一旦观察每个节点的数量少于50就停止。
⑦在这两种情况下,分裂过程达到停止标准后就会构建出一个成年树。但是,成年树可能会过度适应数据,导致对未知数据的低准确性。这就带来了“修剪”。修剪是一个解决过度拟合的技术。我们会在以下部分了解更多关于它的内容。
3.树模型是如何决定在哪分裂的?
制造战略性的分裂决定将严重影响树的准确性。分类树和回归树的决策标准是不同的。
决策树算法使用多个算法决策将一个节点分裂成两个或两个以上的子节点。子节点的创建增加了合成子节点的同质性。换句话说,我们可以说节点的纯度随着对目标变量得尊重而增加。决策树在所有可用的变量上分裂节点,然后选择产生最均匀的子节点的分裂。
算法的选择也要基于目标变量的类型。让我们来看看这四个最常用的决策树算法:
基尼系数
基尼系数表示,如果总量是纯粹的,我们从总量中随机选择两项,那么这两项必须是同一级别的,而且概率为1。
①它影响着无条件的分类目标变量的“成功”或“失败”。
②它只执行二进制分裂。
③基尼值越高同质性越高。
④CART (分类树和回归树)使用基尼系数方法创建二进制分裂。
通过计算尼基系数来产生分裂的步骤:
①计算子节点的尼基系数,使用公式计算成功和失败的概率的平方和 (p ^ 2 + ^ 2)。
②使用加权尼基系数计算每个节点的分裂。
例子:参照上面使用的例子,我们要基于目标变量(或不玩板球)隔离学生。在下面的快照中,我们使用了性别和班级两个输入变量。现在,我想使用基尼系数确定哪些分裂产生了更均匀的子节点。
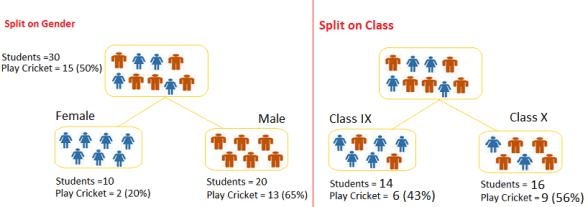
性别节点:
①计算,女性子节点的基尼=(0.2)*(0.2)+(0.8)*(0.8)= 0.68
②男性子节点的基尼=(0.65)*(0.65)+(0.35)*(0.35)= 0.55
③为性别节点计算加权基尼=(10/30)* 0.68 +(20/30)* 0.55 = 0.59
班级节点的相似性:
①IX子节点的基尼=(0.43)*(0.43)+(0.57)*(0.57)= 0.51
②X子节点的基尼=(0.56)*(0.56)+(0.44)*(0.44)= 0.51
③计算班级节点的加权基尼=(14/30)* 0.51 +(16/30)* 0.51 = 0.51
以上,你可以看到基尼得分在性别上高于班级,因此,节点分裂将取于性别。
l卡方
这是一个用来找出子节点和父节点之间差异的统计学意义的算法。我们测量它的方法是,计算观察和期望频率与目标变量之间标准差的平方和。
①它影响到无条件分类目标变量的“成功”或“失败”。
②它可以执行两个或更多的分裂。
③卡方值越高,子节点和父节点之间差异的统计学显著性越明显。
④每个节点的卡方检验都是使用公式计算。
⑤卡方=((实际-预期)^ 2 /预期)^ 1/2
⑥它生成树称为CHAID(卡方自动交互检测器)
卡方计算节点分裂的步骤:
①通过计算成功与失败的偏差为单个节点计算卡方。
②通过计算每个节点成功和失败的卡方和来计算卡方分割点。
例子:让我们使用上面用来计算基尼系数的例子。
性别节点:
①首先我们填充女性节点,填充的实际内容为“打板球”和“不打板球”,这些分别为2和8。
②计算期望值“打板球”和“不打板球”,这对双方而言都是5,因为父节点有相同的50%的概率,我们应用相同的概率在女性计数上(10)。
③通过使用公式计算偏差,实际—预期。实际上就是“打板球”(2 – 5 = -3),“不打板球”(8 – 5 = 3)。
④计算卡方节点的“打板球”和“不打板球”的公式=((实际-预期)^ 2 /预期)^ 1/2。您可以参考下表计算。
⑤遵循同样的步骤计算男性节点卡方值。
⑥现在添加所有卡方值来计算卡方性别分裂点。

班级节点:
执行以上类似的步骤来计算班级分裂点,你就会得出下面的表。

以上,你也可以看到,卡方识别性别分裂比班级更重要。
l信息增益
看看下面的图片,你认为哪个节点容易描述。我相信你的答案是C,因为它需要更少的信息,所有的值是相似的。另一方面,B需要更多的信息来描述它,A需要最大的信息。换句话说,我们可以说,C是一个纯粹的节点,B是较不纯粹的,而A是最不纯粹的。
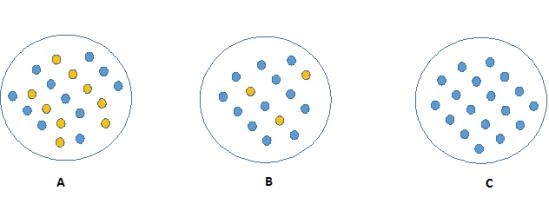
现在,我们可以提出一个结论:较不纯粹的节点需要更少的信息来描述它,而纯粹度越高需要的信息越多。定义这一个系统的无序程度的信息理论称为熵。如果样品完全均匀,那么熵为0,如果样品是同等划分(50% – 50%),那么它的熵为1 。
熵可以使用公式计算:
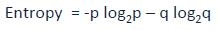
这里的p和q分别为成功和失败的概率节点。熵也用于分类目标变量。选择相比父节点和其他节点分裂最低的熵。熵越小越好。
计算熵分割的步骤:
①计算父节点的熵。
②计算每个独立节点分割的熵,并计算分裂中所有子节点得加权平均值。
例子:我们用这种方法来为学生例子确定最佳分割点。
①父节点的熵= – (15/30)log2(15/30)-(15/30)log2(15/30)= 1。1表示这是一个不纯洁的节点。
②女性节点的熵= -(2/10)log2(2/10)-(8/10)log2(8/10)= 0.72和男性节点,-(13/20)log2(13/20)(7/20)log2(7/20)= 0.93
③子节点性别分割的熵=加权熵=(10/30)* 0.72 +(20/30)* 0.72 = 0.86
④IX班级子节点的熵,-(6/14)log2(6/14)(8/14)log2(8/14)= 0.99 X班级子节点,-(9/16)log2(9/16)(7/16)log2(7/16)= 0.99。
⑤班级分割的熵=(14/30)* 0.99 +(16/30)* 0.99 = 0.99
以上,你可以看到性别分裂的熵在所有之中是最低的,所以这个树模型将在性别上分裂。我们可以得出信息熵作为1 -熵。
l减少方差
到现在,我们已经讨论了分类目标变量的算法。减少方差算法用于连续目标变量(回归问题)。该算法使用标准方差公式选择最佳分裂。选择方差较低的分裂作为总量分裂的标准:
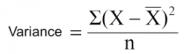
以上X指的是值,X是实际得值,n是值的数量。
方差的计算方法:
①为每个节点计算方差。
②为每个节点方差做加权平均。
例子:——让我们分配数值1为打板球和0为不玩板球。现在按以下步骤确定正确的分割:
①方差为根节点,这意味着值是(15 * 1 + 15 * 0)/ 30 = 0.5,我们有15个 1和15个 0。现在方差是((1 – 0.5)^ 2 +(1 – 0.5)^ 2 +…。+ 15倍(0 – 0.5)^ 2 +(0 – 0.5)^ 2 +…)/ 30的15倍,这可以写成(15 *(1 – 0.5)^ 2 + 15 *(0 – 0.5)^ 2)/ 30 = 0.25
②女性节点的平均值=(2 * 1 + 8 * 0)/ 10 = 0.2和方差=(2 *(1 – 0.2)^ 2 + 8 *(0 – 0.2)^ 2)/ 10 = 0.16
③男性节点的平均值=(13 * 1 + 7 * 0)/ 20 = 0.65,方差=(13 *(1 – 0.65)^ 2 + 7 *(0 – 0.65)^ 2)/ 20 = 0.23
④分割性别的方差=子节点的加权方差=(10/30)* 0.16 +(20/30)* 0.16 = 0.21
⑤IX班级节点的平均值=(6 * 1 + 8 * 0)/ 14 = 0.43,方差=(6 *(1 – 0.43)^ 2 + 8 *(0 – 0.43)^ 2)/ 14 = 0.24
⑥X班级节点的平均值=(9 * 1 + 7 * 0)/ 16 = 0.56和方差=(9 *(1 – 0.56)^ 2 + 7 *(0 – 0.56)^ 2)/ 16 = 0.25
⑦分割性别的方差=(14/30)* 0.24 +(16/30)* 0.25 = 0.25
以上,你可以看到性别分割方差比父节点低,所以分割会发生在性别变量。
到这里,我们就学会了基本的决策树和选择最好的分裂建立树模型的决策过程。就像我说的,决策树可以应用在回归和分类问题上。让我们详细了解这些方面。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330