基于用户的协同过滤推荐算法原理和实现
在推荐系统众多方法中,基于用户的协同过滤推荐算法是最早诞生的,原理也较为简单。该算法1992年提出并用于邮件过滤系统,两年后1994年被 GroupLens 用于新闻过滤。一直到2000年,该算法都是推荐系统领域最著名的算法。
本文简单介绍基于用户的协同过滤算法思想以及原理,最后基于该算法实现园友的推荐,即根据你关注的人,为你推荐博客园中其他你有可能感兴趣的人。
基本思想
俗话说“物以类聚、人以群分”,拿看电影这个例子来说,如果你喜欢《蝙蝠侠》、《碟中谍》、《星际穿越》、《源代码》等电影,另外有个人也都喜欢这些电影,而且他还喜欢《钢铁侠》,则很有可能你也喜欢《钢铁侠》这部电影。
所以说,当一个用户 A 需要个性化推荐时,可以先找到和他兴趣相似的用户群体 G,然后把 G 喜欢的、并且 A 没有听说过的物品推荐给 A,这就是基于用户的系统过滤算法。
原理
根据上述基本原理,我们可以将基于用户的协同过滤推荐算法拆分为两个步骤:
1. 找到与目标用户兴趣相似的用户集合
2. 找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户
1. 发现兴趣相似的用户
通常用 Jaccard 公式或者余弦相似度计算两个用户之间的相似度。设 N(u) 为用户 u 喜欢的物品集合,N(v) 为用户 v 喜欢的物品集合,那么 u 和 v 的相似度是多少呢:
Jaccard 公式:
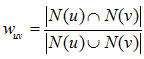
余弦相似度:
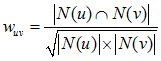
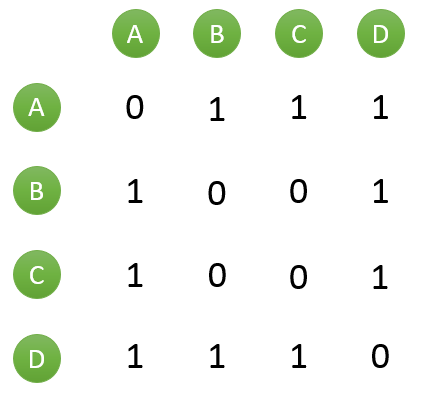
假设目前共有4个用户: A、B、C、D;共有5个物品:a、b、c、d、e。用户与物品的关系(用户喜欢物品)如下图所示:

如何一下子计算所有用户之间的相似度呢?为计算方便,通常首先需要建立“物品—用户”的倒排表,如下图所示:

然后对于每个物品,喜欢他的用户,两两之间相同物品加1。例如喜欢物品 a 的用户有 A 和 B,那么在矩阵中他们两两加1。如下图所示:
计算用户两两之间的相似度,上面的矩阵仅仅代表的是公式的分子部分。以余弦相似度为例,对上图进行进一步计算:

到此,计算用户相似度就大功告成,可以很直观的找到与目标用户兴趣较相似的用户。
2. 推荐物品
首先需要从矩阵中找出与目标用户 u 最相似的 K 个用户,用集合 S(u, K) 表示,将 S 中用户喜欢的物品全部提取出来,并去除 u 已经喜欢的物品。对于每个候选物品 i ,用户 u 对它感兴趣的程度用如下公式计算:
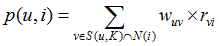
其中 rvi 表示用户 v 对 i 的喜欢程度,在本例中都是为 1,在一些需要用户给予评分的推荐系统中,则要代入用户评分。
举个例子,假设我们要给 A 推荐物品,选取 K = 3 个相似用户,相似用户则是:B、C、D,那么他们喜欢过并且 A 没有喜欢过的物品有:c、e,那么分别计算 p(A, c) 和 p(A, e):
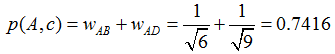
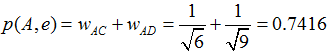
看样子用户 A 对 c 和 e 的喜欢程度可能是一样的,在真实的推荐系统中,只要按得分排序,取前几个物品就可以了。
园友推荐
在社交网络的推荐中,“物品”其实就是“人”,“喜欢一件物品”变为“关注的人”,这一节用上面的算法实现给我推荐 10 个园友。
1. 计算 10 名与我兴趣最相似的园友
由于只是为我一个人做用户推荐,所以没必要建立一个庞大的用户两两之间相似度的矩阵了,与我兴趣相似的园友只会在这个群体产生:我关注的人的粉丝。除我自己之外,目前我一共关注了23名园友,这23名园友一共有22936个唯一粉丝,我对这22936个用户逐一计算了相似度,相似度排名前10的用户及相似度如下:
|
昵称
|
关注数量
|
共同数量
|
相似度
|
|
蓝枫叶1938
|
5
|
4
|
0.373001923296126
|
|
FBI080703
|
3
|
3
|
0.361157559257308
|
|
鱼非鱼
|
3
|
3
|
0.361157559257308
|
|
Lauce
|
3
|
3
|
0.361157559257308
|
|
蓝色蜗牛
|
3
|
3
|
0.361157559257308
|
|
shanyujin
|
3
|
3
|
0.361157559257308
|
|
Mr.Huang
|
6
|
4
|
0.340502612303499
|
|
对世界说你好
|
6
|
4
|
0.340502612303499
|
|
strucoder
|
28
|
8
|
0.31524416249564
|
|
Mr.Vangogh
|
4
|
3
|
0.312771621085612
|
2. 计算对推荐园友的兴趣度
这10名相似用户一共推荐了25名园友,计算得到兴趣度并排序:
|
排序
|
昵称
|
兴趣度
|
|
1
|
wolfy
|
0.373001923296126
|
|
2
|
Artech
|
0.340502612303499
|
|
3
|
Cat Chen
|
0.340502612303499
|
|
4
|
WXWinter(冬)
|
0.340502612303499
|
|
5
|
DanielWise
|
0.340502612303499
|
|
6
|
一路前行
|
0.31524416249564
|
|
7
|
Liam Wang
|
0.31524416249564
|
|
8
|
usharei
|
0.31524416249564
|
|
9
|
CoderZh
|
0.31524416249564
|
|
10
|
博客园团队
|
0.31524416249564
|
|
11
|
深蓝色右手
|
0.31524416249564
|
|
12
|
Kinglee
|
0.31524416249564
|
|
13
|
Gnie
|
0.31524416249564
|
|
14
|
riccc
|
0.31524416249564
|
|
15
|
Braincol
|
0.31524416249564
|
|
16
|
滴答的雨
|
0.31524416249564
|
|
17
|
Dennis Gao
|
0.31524416249564
|
|
18
|
刘冬.NET
|
0.31524416249564
|
|
19
|
李永京
|
0.31524416249564
|
|
20
|
浪端之渡鸟
|
0.31524416249564
|
|
21
|
李涛
|
0.31524416249564
|
|
22
|
阿不
|
0.31524416249564
|
|
23
|
JK_Rush
|
0.31524416249564
|
|
24
|
xiaotie
|
0.31524416249564
|
|
25
|
Leepy
|
0.312771621085612
|
只需要按需要取相似度排名前10名就可以了,不过看起来整个列表的推荐质量都还不错!
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330