电信级数据流量与监控系统部署案例分享
编者按:挖掘用户的行为习惯和喜好,在凌乱纷繁的数据背后找到更符合用户兴趣和习惯的产品和服务,并对产品和服务进行针对性地调整和优化,这就是大数据的价值。今天分享的内容就是永洪大数据一个大数据分析平台的搭建部署案例。
以下为原文:
夜深了,电话铃声响起!这不是恐怖片的开头,却是我们工作的开始。
2013年5月,我们收到一个电话线索,客户需要支持几十亿数据量的实时查询与分析,包括数据抓取和存储,我们经过一番努力提出一个解决方案,客户觉得有些不妥,决定自己招聘Hadoop团队,实施该系统……
半个月后,客户打来第二个电话,明确表示Hadoop未能满足实时大数据分析的需求,决定接受我们的方案,但是客户要求我们不仅出产品,还要负责实施……
于是乎,开工!
项目价值
CMNET网间流量分析与监控系统(简称流控系统),是中国移动分公司的一个项目。项目要求能基于时间、地区、运营商、业务、App、IP分组、域名等维度对全省的上网流量进行实时分析和报告。这些分析报告能给客户带来如下好处:
1. 实现对接入链路和基站的全程监控。例如,一旦来自某链路或基站的流量很低,可及时对链路和基站进行检修,这将大大降低故障率。
2. 由于具备了对链路和基站进行全程监控的能力,客户可以对链路和基站的带宽进行动态调整,基于需求进行合理的资源配置。
3. 覆盖全省的全量数据,能提供基于业务/地域/App/行业/域名等维度的数据分析报告,具备100%的可信度和极高的商业价值。
数据流向
上网数据从硬件设备中抓取出来,形成压缩的日志文件存储在服务器上,服务器每五分钟生成新的日志文件。该服务器提供FTP访问。
我们方案中承担的流控系统,将通过FTP每五分钟访问一次日志文件服务器,将新生成的压缩日志文件抽取出来。这是一个典型的、增量更新的ETL过程,如下:
1. Extract: 定期抽取的日志文件并解压缩。
2. Transform: 解析出上网信息,同MySQL的维度表进行关联,生成包括业务/地域/App/行业/域名等维度的宽表。
3. Load: 将数据装载入我们的分布式集市。
初期验证(POC)
中国移动的日志数据分G类和A类,各取几块样本日志文件,验证数据流向的可行性以及性能。
我们很快完成了ETL的整个过程,宽表数据被成功地装载入我们的分布式集市。
性能上,我们按照用户提出的每天数据量5000万条增量,计算出支持100天50亿数据量的分布式集群所需的磁盘空间、内存总量、和CPU总量。由于客户一再强调预算有限,于是配置了6台低配PC server:1cpu x 4core,32G内存,1T硬盘。
我们模拟了常用的用户场景,整个系统的响应能力基本满足需求。系统架构如下:
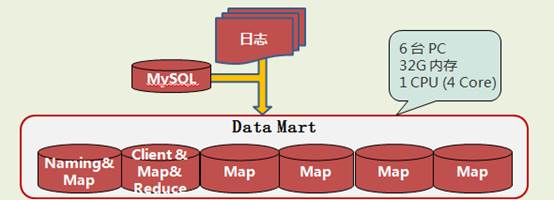
系统架构图
正式实施
中国移动分公司的上网数据在内网,一般不提供外网连接,需要严格申请之后才能在一定时间内提供外网连接。因而,我们先把整个系统的ETL工作开发完成之后,才正式申请了外网连接进行数据装载。
从开始进行上网数据的ETL工作,我们就发现数据量与预期严重不符。预期的上网数据是每天不超过5000万条,但实际上每天的上网数据在6亿条以上,100天保存的数据量将会达到惊人的六百亿条。6台低配PC server有点小马拉大车的感觉,完全达不到“海量数据、实时分析”的设计目标。我们赶紧联系客户,确定上网数据每天6亿条以上,而不是之前预估的每天5000万条左右。怎么办?
系统重构
经过与客户的详细沟通和理性分析,大家一致决定进行系统重构。
上网数据的日志文件是5分钟粒度的。我们将上网数据按照分析需求分为两类:
1. 细节数据:保留三天的细节数据(5分钟粒度),共约20亿条。这样,由于保留了细节数据,客户可以对近三天的上网数据进行任意的探索式BI分析。
2. 汇总数据:在认真研究了流控系统的分析报告需求之后,我们将五分钟的细节数据汇总为两小时的汇总数据。这样数据量可以降到约为原来的1/10,100天的数据总量大约60亿条。
重构之后的数据流如下:
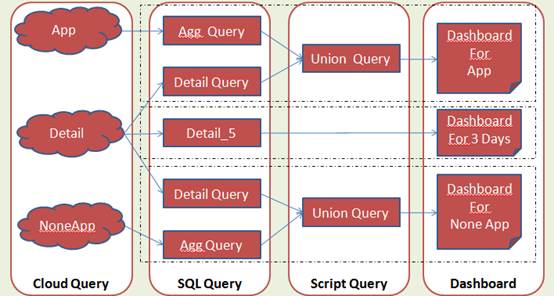
数据流图
后期,我们陆续进行了一些系统调优,包括JVM调优、存储调优、计算调优等等。客户打开一个Dashboard的响应时间基本控制在秒级,最极端的分析报告也能在一分钟之内生成。基本实现了“海量数据、实时分析”:
1. 系统定期推送日报、周报和月报。
2. 系统支持探索式BI分析。多数分析请求达到了秒级响应。
案例总结
1. 项目的数据量非常大,100天超过600亿条日志;
2. 项目的预算非常有限,采购了6台低端PC Server。硬件投入不大,软件性价比也很高;
3. ETL过程难度较高,随着降维的需求加入,BI层难度也相应提高;
4. 为达到秒级响应,以支持探索式BI的交互式分析,对系统进行了多个层面的优化。
结束语
有了大数据,还要从大数据中提取价值,离不开分析工具,通过丰富的分析功能,在繁杂的数据中找到其中的价值。而大数据给分析提供了一定的挑战,需要高性能计算做支撑,才能在大数据的金矿中挖到金子。
这些案例的成功实施和上线,完美诠释了我们的大数据之道:大数据,小投入。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330