Pearson于1901年提出,再由Hotelling(1933)加以发展的一种多变量统计方法。通过析取主成分显出最大的个别差异,也用来削减回归分析和聚类分析中变量的数目,可以使用样本协方差矩阵或相关系数矩阵作为出发点进行分析。
通过对原始变量进行线性组合,得到优化的指标:把原先多个指标的计算降维为少量几个经过优化指标的计算(占去绝大部分份额)
基本思想:设法将原先众多具有一定相关性的指标,重新组合为一组新的互相独立的综合指标,并代替原先的指标。
成分的保留:Kaiser主张(1960)将特征值小于1的成分放弃,只保留特征值大于1的成分。
接下来以小学生基本生理属性为案例分享下R语言的具体实现,分别选取身高(x1)、体重(x2)、胸围(x3)和坐高(x4)。具体如下:
student<- data.frame( x1=c(148,139,160,149,159,142,153,150,151), x2=c(41 ,34 , 49 ,36 ,45 ,31 ,43 ,43,
42), x3=c(72 ,71 , 77 ,67 ,80 ,66 ,76 ,77,77), x4=c(78 ,76 , 86 ,79 ,86 ,76 ,83 ,79 ,80)
) student.pr <- princomp(student,cor=TRUE) summary(student.pr,loadings=TRUE) screeplot(student.pr,type="
lines")
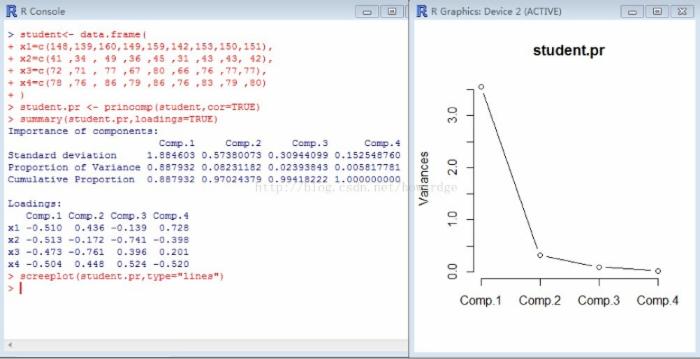
结果如截图:
 由上图可见四项指标做分析后,给出了4个成分,他们的重要性分别为:0.887932、0.08231182、0.02393843、0.005817781,累积贡献为:0.887932、0.97024379、
由上图可见四项指标做分析后,给出了4个成分,他们的重要性分别为:0.887932、0.08231182、0.02393843、0.005817781,累积贡献为:0.887932、0.97024379、
0.99418222 1.000000000各个成分的碎石图也如上,可见成份1和成份2的累积贡献已经达到95%,因此采用这两个成份便可充分解释学生的基本信息。
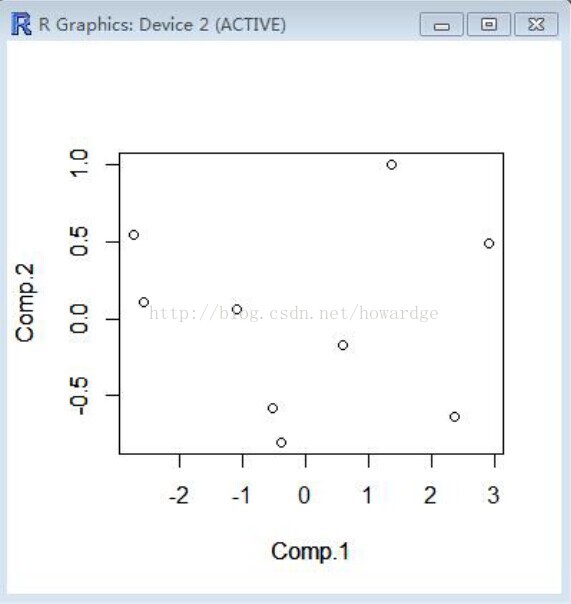
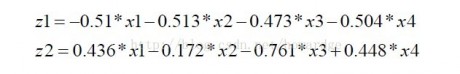 我们可以通过R自动算出各主成份的值,并画出散点图:
我们可以通过R自动算出各主成份的值,并画出散点图:
temp<-predict(student.pr)
plot(temp[,1:2])
结果如图:
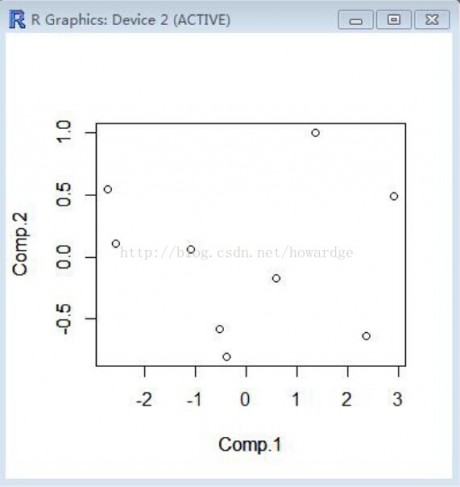
观察如图可见两个成分的分离度很高,比较理想。

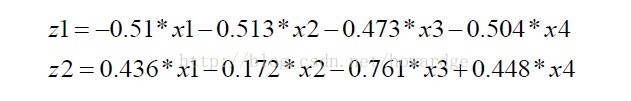










 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330