SPSS聚类分析过程解析
SPSS手把手的教程案例不错,数据小兵是一个专注SPSS研究的博客,里面涉及SPSS各种经典分析方法的实际操作过程解析。今天给大家推荐的是《利用SPSS进行聚类分析的过程》。
案例过程涉及到spss层次聚类中的Q型聚类和R型聚类,单因素方差分析,Means过程等,是一个很不错的多种分析方法联合使用的 聚类分析案例。
案例数据源:有20种12盎司啤酒成分和价格的数据,变量包括啤酒名称、热量、钠含量、酒精含量、价格。数据来自《SPSS for Windows 统计分析》data11-03。
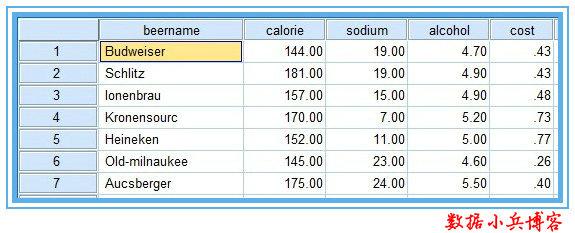
【一】问题一:选择那些变量进行聚类?——采用“R型聚类”
1、如何筛选聚类变量?现在我们有4个变量用来对啤酒分类,是否有必要将4个变量都纳入作为分类变量呢?热量、钠含量、酒精含量这3个指标是要通过化验员的辛苦努力来测定,而且还有花费不少成本,如果都纳入分析的话,岂不太麻烦太浪费?所以,有必要对4个变量进行降维处理,这里采用spss R型聚类(变量聚类),对4个变量进行降维处理。输出“相似性矩阵”有助于我们理解降维的过程。
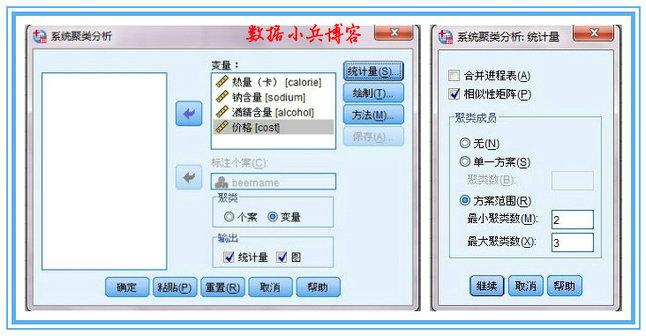
2、4个分类变量量纲各自不同,这一次我们先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,涉及到相关,4个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
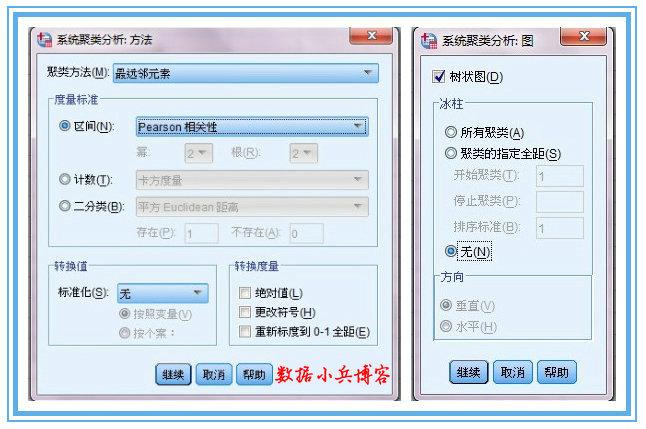
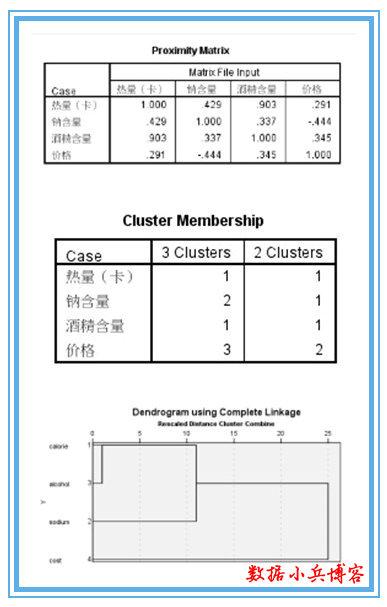
3、只输出“树状图”就可以了,个人觉得冰柱图很复杂,看起来没有树状图清晰明了。从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
【二】问题二:20中啤酒能分为几类?——采用“Q型聚类”
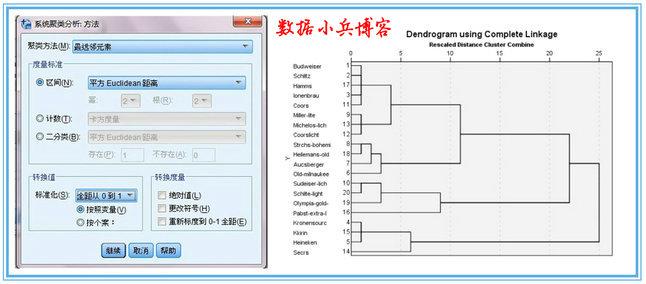
1、现在开始对20中啤酒进行聚类。开始不确定应该分为几类,暂时用一个3-5类范围来试探。Q型聚类要求量纲相同,所以我们需要对数据标准化,这一回用欧式距离平方进行测度。

2、主要通过树状图和冰柱图来理解类别。最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。我这里试着确定分为4类。选择“保存”,则在数据区域内会自动生成聚类结果。
【三】问题三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”
1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
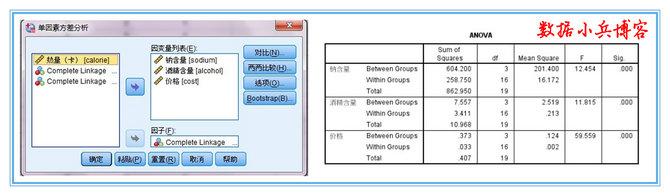
2、这个过程一般用 单因素方差分析来判断。注意此时,因子变量选择聚为4类的结果,而将三个聚类变量作为因变量处理。方差分析结果显示,三个聚类变量sig值均极显著,我们用于分类的3个变量对分类有作用,可以使用,作为聚类变量是比较合理的。
【四】问题四:聚类结果的解释?——采用”均值比较描述统计“
1、聚类分析最后一步,也是最为困难的就是对分出的各类进行定义解释,描述各类的特征,即各类别特征描述。这需要专业知识作为基础并结合分析目的才能得出。

2、我们可以采用spss的means均值比较过程,或者excel的透视表功能对各类的各个指标进行描述。其中,report报表用于描述聚类结果。对各类指标的比较来初步定义类别,主要根据专业知识来判定。这里到此为止。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330