7个因素决定大数据的复杂性 如何处理
我们谈论了很多关于复杂数据及其为你的商业智能带来的挑战和机遇,但是导致数据复杂化的是什么呢?
以及你如何区分你的公司当前的数据是否是“复杂的”,亦或不久的将来会变得复杂?本文将解决这些问题。
为什么这很重要?
当你试图将数据转化为商业价值时,它的复杂度很可能会预示你将面对的困难程度——复杂数据的准备和分析通常要比简单数据更加困难,以及通常需要一组不同的BI 工具来实现。复杂数据在可以“成熟的”分析和可视化之前需要额外的准备工作和数据模型。因此重要的是,通过了解您目前的数据的复杂程度以及它在未来的复杂性趋向,来评估您的大数据/商业智能项目是否能够胜任这一任务。
简单测试:大数据或者异构数据
在高级层面上,有两种基本的迹象表明你的数据可能被视为是复杂的:
你的数据很“大”:我们把大放在引号里是因为它貌似符合“大数据”术语的含义。然而事实是,处理海量数据在计算资源需要处理巨大的数据集方面提出了一个挑战, 就像把小麦从谷壳分开的困难,或者说在一个巨大的原始信息中辨别信号和杂音。
你的数据来自许多不同的数据源:多重数据源通常意味着脏数据,或者遵循着不同的内部逻辑结构的简单的多个数据集。为了确保数据源有统一的数据语言,数据必须被转换或整合到一个中央资源库。
可以认为这是两个最初的(可供选择的)征兆:如果你正处理大数据或异构数据,你应当开始思考数据的复杂性。但是深究一下,对你的公司的数据的复杂性,以下有7个更具体的指标。
(注意,以上两点之间有相似之处,但不互相排除——反之,例如,离散数据往往意味着各种各样的数据结构类型)
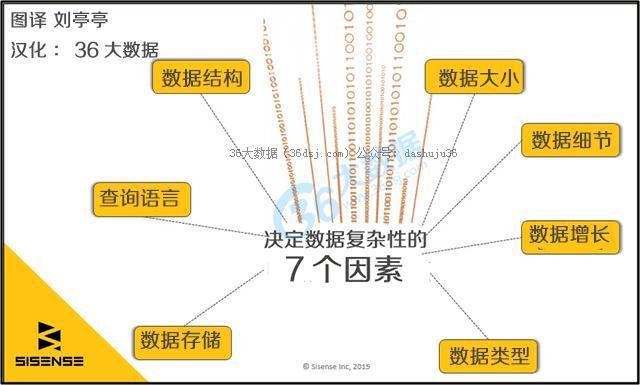
7个因素决定你的数据的复杂性
1、数据结构
不同数据源的数据,或甚至来自同一个源的不同表,通常设计同样的信息但结构却完全不同:
举例来说,想象你们人力资源部有三种不同的表格,一个是员工个人信息表,另一个是员工职位和薪资表第三个是员工职位要求表,诸如此类——而你们财务部门随同保险、福利和其他花费一起记录同样的信息到单个表中。另外,在这些表中的一些表可能提到员工的全名,而另一些则只有名字的首字母,或者二者的结合。为了从所有表中有效使用数据,同时不丢失或重复信息,需要数据建模或准备工作。
这是最简单的用例:更进一步复杂化的是处理最初没有适当地模式的非结构化数据源(例如NoSQL 数据库)。
2、数据大小
再次回到模糊的“大数据”概念,你收集的数据量会影响你需要用来分析它的软硬件的类型。这个可以通过原始大小来衡量:字节,TB或PB——数据增长越大,越有可能“窒息”广泛使用的内存数据库(IMDB),依赖于转化压缩数据到服务器内存。其他因素包括多元异构数据——包含很多数据行的表(Excel,可以说是最常用的数据分析工具,最大行数限制为1048576行),或结构化数据——包含很多数据列的表。
你将会发现在分析工具和方法上用于分析100,000行数据和那些用于分析1亿行数据的是明显不同的。
3、数据细节
你想要探索的数据的粒度水平。当创建一个仪表盘或报表,展现总结或聚合数据时常常比让终端用户钻取到每一个细节更容易实现——然而这是以牺牲数据分析的深度和数据挖掘为代价而做的权宜之计。
创建一个BI系统,使其具有颗粒向海量数据钻取处理分析的能力,(不依赖于预定义查询,聚合或汇总表)
4、查询语言
不同的数据源有不同的数据语言:虽然SQL是从常见数据源和RDBMS提取数据的主要手段,但是当使用第三方平台时你会经常需要通过它自己的API和语法去连接它,以及解析用于访问数据的数据模型和协议。
你的BI工具需要足够灵活的根据数据源允许这种本地连接的方式,或者通过内置插件或API访问,否则你会发现你自己将不得不重复一个繁琐的导出数据到表格\SQL数据库\数据仓库的过程,然后导入到你的商业智能软件里,从而使你的分析变得麻烦。
5、数据类型
一方面动态数据以表格形式存储,处理的大多是数值型数据,但是大规模和非结构化的机器数据完全是另外一回事儿,就像是文字数据集存储在MongoDB中,当然了,更别提像视频音频这种超大规模的非结构化数据了。
不同的数据类型具有不同的规则,为使得商业决策建立在对公司数据的全面考虑的基础上,找到一种建立单一可信来源的方法是至关重要的。
6、离散数据
数据存储在多个位置:例如,组织里的不同部门,本地或云(付费存储或通过云应用),来自客户或供应商的外部数据等。这种数据不仅收集起来很困难(简单来说是由于及时而有效的接收数据而需要的利益相关者的数量)。而且一旦收集了——在不同的数据集交叉引用和分析之前,通常需要“清理”或标准化,因为每个本地数据集是根据相关组织\应用程序自身的实际和关注收集数据。
7、数据量的增长
最终,你不仅需要考虑当前数据,还有数据的增长或变化的速度。如果经常更新数据源,或经常增加新的数据源,这将会消耗你的软硬件资源(无论何时当源数据发生重大更改时,不是非常先进的系统都需要重新获取整个数据集),以及上述提到的关于结构、类型、大小的复合性问题等。
怎样掌控复杂数据?
如果你认同上述的一个或更多以及你的数据刚刚好是复杂的,不要绝望:理解,是找到一个合适的解决方案的第一步,以及复杂数据的分析本身不需要过于复杂。我们将在未来的文章中涉及解决复杂数据的方法,但是你将想问自己的第一件事可能是——控制复杂数据你实际需要多少BI系统。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330