大数据与海量数据的区别
如果仅仅是海量的结构性数据,那么解决的办法就比较的单一,用户通过购买更多的存储设备,提高存储设备的效率等解决此类问题。然而,当人们发现数据库中的数据可以分为三种类型:结构性数据、非结构性数据以及半结构性数据等复杂情况时,问题似乎就没有那么简单了。
大数据汹涌来袭
当类型复杂的数据汹涌袭来,那么对于用户IT系统的冲击又会是另外一种处理方式。很多业内专家和第三方调查机构通过一些市场调查数据发现,大数据时代即将到来。有调查发现,这些复杂数据中有85%的数据属于广泛存在于社交网络、物联网、电子商务等之中的非结构化数据。这些非结构化数据的产生往往伴随着社交网络、移动计算和传感器等新的渠道和技术的不断涌现和应用。
如今大数据的概念也存在着很多的炒作和大量的不确定性。为此,编者详细向一些业内专家详细了解有关方面的问题,请他们谈一谈,大数据是什么和不是什么,以及如何应对大数据等问题,将系列文章的形式与网友见面。
有人将多TB数据集也称作”大数据”。据市场研究公司IDC统计,数据使用预计将增长44倍,全球数据使用量将达到大约35.2ZB(1ZB = 10亿TB)。然而,单个数据集的文件尺寸也将增加,导致对更大处理能力的需求以便分析和理解这些数据集。
EMC曾经表示,它的1000多个客户在其阵列中使用1PB(千兆兆)以上的数据数据,这个数字到2020年将增长到10万。一些客户在一两年内还将开始使用数千倍多的数据,1EB(1艾字节 = 10亿GB)或者更多的数据。
对大企业而言,大数据的兴起部分是因为计算能力可用更低的成本获得,且各类系统如今已能够执行多任务处理。其次,内存的成本也在直线下降,企业可以在内存中处理比以往更多的数据,另外是把计算机聚合成服务器集群越来越简单。IDC认为,这三大因素的结合便催生了大数据。同时,IDC还表示,某项技术要想成为大数据技术,首先必须是成本可承受的,其次是必须满足IBM所描述的三个”V”判据中的两个:多样性(variety)、体量(volume)和速度(velocity)。
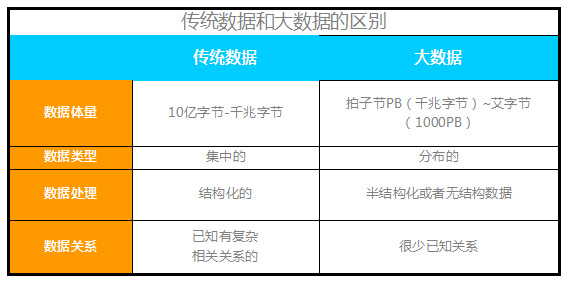
多样性是指,数据应包含结构化的和非结构化的数据。
体量是指聚合在一起供分析的数据量必须是非常庞大的。
而速度则是指数据处理的速度必须很快。
大数据”并非总是说有数百个TB才算得上。根据实际使用情况,有时候数百个GB的数据也可称为大数据,这主要要看它的第三个维度,也就是速度或者时间维度。
Garter表示,全球信息量正在以59%以上的年增长率增长,而量是在管理数据、业务方面的显著挑战,IT领袖必须侧重在信息量、种类和速度上。
量:企业系统内部的数据量的增加是由交易量、其它传统数据类型和新的数据类型引发的。过多的量是一个存储的问题,但过多的数据也是一个大量分析的问题。
种类:IT领袖在将大量的交易信息转化为决策上一直存在困扰 – 现在有更多类型的信息需要分析 – 主要来自社交媒体和移动(情景感知)。种类包括表格数据(数据库)、分层数据、文件、电子邮件、计量数据、视频、静态图像、音频、股票行情数据、金融交易和其它更多种类。
速度:这涉及到数据流、结构化记录的创建,以及访问和交付的可用性。速度意味着正在被生成的数据有多快和数据必须被多快地处理以满足需求。
虽然大数据是一个重大问题,Gartner分析师表示,真正的问题是让大数据更有意义,在大数据里面寻找模式帮助组织机构做出更好的商业决策。
诸子百家谈如何定义”大数据”
尽管”Big Data”可以翻译成大数据或者海量数据,但大数据和海量数据是有区别的。
定义一:大数据 = 海量数据 + 复杂类型的数据
Informatica中国区首席产品顾问但彬认为:”大数据”包含了”海量数据”的含义,而且在内容上超越了海量数据,简而言之,”大数据”是”海量数据”+复杂类型的数据。
但彬进一步指出:大数据包括交易和交互数据集在内的所有数据集,其规模或复杂程度超出了常用技术按照合理的成本和时限捕捉、管理及处理这些数据集的能力。
大数据是由三项主要技术趋势汇聚组成:
-
海量交易数据:在从 ERP应用程序到数据仓库应用程序的在线交易处理(OLTP)与分析系统中,传统的关系数据以及非结构化和半结构化信息仍在继续增长。随着企业将更多的数据和业务流程移向公共和私有云,这一局面变得更加复杂。
-
海量交互数据:这一新生力量由源于 Facebook、Twitter、LinkedIn 及其它来源的社交媒体数据构成。它包括了呼叫详细记录(CDR)、设备和传感器信息、GPS和地理定位映射数据、通过管理文件传输(Manage File Transfer)协议传送的海量图像文件、Web 文本和点击流数据、科学信息、电子邮件等等。
-
海量数据处理:大数据的涌现已经催生出了设计用于数据密集型处理的架构,例如具有开放源码、在商品硬件群中运行的 Apache Hadoop。对于企业来说,难题在于以具备成本效益的方式快速可靠地从 Hadoop 中存取数据。
定义二:大数据包括A、B、C三个要素
如何理解大数据?NetApp 大中华区总经理陈文认为,大数据意味着通过更快获取信息来使做事情的方式变得与众不同,并因此实现突破。大数据被定义为大量数据(通常是非结构化的),它要求我们重新思考如何存储、管理和恢复数据。那么,多大才算大呢?考虑这个问题的一种方式就是,它是如此之大,以至于我们今天所使用的任何工具都无法处理它,因此,如何消化数据并把它转化成有价值的洞见和信息,这其中的关键就是转变。
基于从客户那里了解的工作负载要求, NetApp所理解的大数据包括A、B、C三个要素:分析(Analytic),带宽(Bandwidth)和内容(Content)。
1. 大分析(Big Analytics),帮助获得洞见 – 指的是对巨大数据集进行实时分析的要求,它能带来新的业务模式,更好的客户服务,并实现更好的结果。
2. 高带宽(Big Bandwidth),帮助走得更快 – 指的是处理极端高速的关键数据的要求。它支持快速有效地消化和处理大型数据集。
3. 大内容(Big Content),不丢失任何信息- 指的是对于安全性要求极高的高可扩展的数据存储,并能够轻松实现恢复。它支持可管理的信息内容存储库、而不只是存放过久的数据,并且能够跨越不同的大陆板块。
大数据是一股突破性的经济和技术力量,它为 IT 支持引入了新的基础架构。大数据解决方案消除了传统的计算和存储的局限。借助于不断增长的私密和公开数据,一种划时代的新商业模式正在兴起,它有望为大数据客户带来新的实质性的收入增长点以及富于竞争力的优势。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330