数据仓库架构设计的一点概念
1、数据仓库所处环节
在一个成体系、结构化的数据应用场景下,数据和处理有四个层次: 操作层、数据仓库层、部门/数据集市层、个体层。
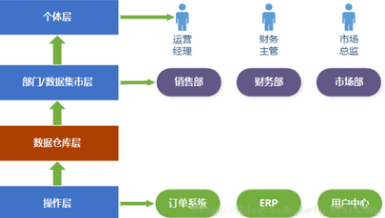
操作层
操作层是指为具体业务提供实时响应的各个业务系统,比如常见的订单系统、ERP、用户中心等等具体业务系统,这些系统中的数据一般都是存入关系型数据库。它们是数据的来源。
数据仓库
数据仓库收集操作层各个业务系统中的数据,进行统一格式、统一计量单位,规整有序地组织在一起,为数据分析、数据挖掘等需求提供数据支持。
数据集市
部门/数据集市层是各个部门根据自己的数据分析需求,从数据仓库中抽取自己部门所关心的数据报表。
个体层
个体层中的不同角色个体有读取不同数据的权限。
2、数据仓库概念
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
面向主题的
数据仓库不同于传统的操作型系统,传统的操作型系统中的数据是围绕功能进行组织的,而数据仓库是针对于某一个主题进行分析数据用的,比如针对于销售主题、针对于客户主题等等。
集成的
不同产品或者系统中的数据是分散在各自系统中的,并且格式不一致、计量单位不一致。而数据仓库必须将多个分散的数据统一为一致的、无歧义的数据格式后,并解决了命名冲突、计量单位不一致等问题,然后将数据整合在一起,才能称这个数据仓库是集成的。
随时间变化的
数据仓库要体现出数据随时间变化的情况,并且可以反映在过去某一个时间点上数据是什么样子的,也就是随时间变化的含义。而传统的操作型系统,只能保存当前数据,体现当前的情况。
非易失的
非易失是指:数据一旦进入数据仓库,就不能再被改变了,当在操作型系统中把数据改变后,再进入数据仓库就会产生新的记录。这样数据仓库就保留了数据变化的轨迹。
3、一般架构

1、 STAGE层
业务系统的数据接入到数据仓库时,首先将业务数据仓储到STAGE层中,Stage层作为一个临时缓冲区,并屏蔽对业务系统的干扰。
STAGE层中的表结构和数据定义一般与业务系统保持一致。
Stage中的数据可以每次全量接入也可以每次增量接入,一般都有会数据老化的机制,不用长期保存。
Stage的数据不会对外部开放。
2、 ODS层
ODS才是数据仓库真正意义上的基础数据,数据是被清洗过的,ODS层的数据是定义统一的、可以体现历史的、被长期保存的数据。
ODS层的数据粒度与Stage层数据粒度是一致的。
Stage层中的数据是完全形式的源数据,需要进行清洗才能进入ODS层,所以说ODS层是数据仓库格式规整的基础数据,为上层服务。
3、 MDS层
MDS是数据仓库中间层,数据是以主题域划分的,并根据业务进行数据关联形成宽表,但是不对数据进行聚合处理,MDS层数据为数据仓库的上层的统计、分析、挖掘和应用提供直接支持。
MDS层的数据也可以执行一定的老化策略。
4、 ADS层
ADS层是数据仓库的应用层,一般以业务线或者部门划分库。这一层可以为各个业务线创建一个数据库。
ADS层的数据是基于MDS层数据生成的业务报表数据,可以直接作为数据仓库的输出导出到外部的操作型系统中(MySQL、MSSQL、Hbase、Elasticsearch等)。
5、 DIM层
DIM层是数据仓库数据中,各层公用的维度数据。比如:省市县数据。
6、 ETL调度系统
对接入数据仓库的数据进行清洗、数据仓库各层间数据流转都需要大量的程序任务来操作,这些任务一般都是定时的,并且之间都是有前后依赖关系的,为了能保证任务的有序执行,就需要一个ETL调度系统来管理。
7、 元数据管理系统
描述数据的数据叫做元数据,元数据信息一般包括表名、表描述信息、所在数据库、表结构、存储位置等基本信息,另外还有表之间的血缘关系信息、每天的增量信息、表结构修改记录信息等等。
数据仓库中有大量的表,元数据管理系统就是用来收集、存储、查询数据仓库中元数据的工具,这个系统为数据使用方提供了极大的便利。
4、设计的两个重要问题1、 粒度
粒度是指数据仓库中数据单元的细节程度或综合程度的级别。粒度会深刻地影响数据量的大小以及数据仓库的查询能力。
细节程度越高,粒度级别就越低,查询就越灵活;相反,细节程度越低,粒度级别就越高。
双重粒度:
双重粒度是存储两个粒度下的数据:一个是全量的细节数据;另一个是轻度综合的数据。
2、 分区
数据分区是指把数据分散到可独立处理的分离物理单元中去。恰当地进行分区可以给数据仓库带来多个方面的好处:
(1) 数据装载 (2) 数据访问 (3) 数据存档 (4) 数据删除 (5) 数据监控 (6) 数据存储
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330