盘点机器学习中那些神奇的损失函数
我最近在学习R语言,但是估R语言我应该没能跟sas一样玩那么好。今天来更新在机器学习中的一些专业术语,例如一些损失函数,正则化,核函数是什么东西。
损失函数:损失函数是用来衡量模型的性能的,通过预测值和真实值之间的一些计算,得出的一个值,这个值在模型拟合的时候是为了告诉模型是否还有可以继续优化的空间(模型的目的就是希望损失函数是拟合过的模型中最小的),损失函数一般有以下几种,为什么损失函数还有几种呢,因为不同的算法使用的损失函数有所区分。
1
0-1损失函数:
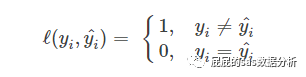
这个损失函数的含义,是最简单的,预测出来的分类结果跟真实对比,一样的返回1,不一样返回0,这种方式比较粗暴,因为有时候是0.999的时候,其实已经很接近了,但是按照这个损失函数的标准,还是返回0,所以这个损失函数很严格,严格到你觉得特别没有人性。
2
感知损失函数
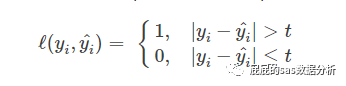
那么这个感知损失函数,其实是跟混淆矩阵那种算法是一样,设定一个阀值,假设真实值与预测值之间的差距超过这个阀值的话,就是1,小于的话就是0,这种就多多少少弥补了0-1损失函数中的严格,假设以0.5为界限,那么比0.5大的我们定义为坏客户,小于0.5定义为坏客户,假设用这种方式,那么大部分好客户聚集在0.6,以及大部分好客户聚集在0.9这个位置,感知损失函数,判断的时候可能是差不多的效果。但是很明显两个模型的效果是,后者要好。当然你在实际的做模型的时候也不会单靠一个损失函数衡量模型啦,只是你在拟合的时候可能使用的损失函数来拟合出机器觉得是最优的。
3
Hinge损失函数
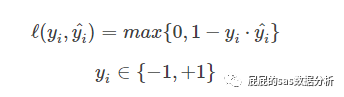
Hinge损失函数是源自于支持向量机中的,因为支持向量机中,最终的支持向量机的分类模型是能最大化分类间隔,又减少错误分类的样本数目,意味着一个好的支持向量机的模型,需要满足以上两个条件:1、最大化分类间隔,2、错误分类的样本数目。错误分类的样本数目,就回到了损失函数的范畴。

我们看上面这张图:把这四个点,根据下标分别叫1、2、3、4点,可以看到hinge衡量的是该错误分类的点到该分类的分类间隔线之间的距离,像1点,他虽然没有被正确分类,但是是在分类间隔中,所以他到正确被分类的线的距离是小于1的(分类间隔取的距离是1),那么像2,3,4点他们到正确的分类间隔的距离都是超过1,正确分类的则置为0,那么回到上面的公式,支持向量机中,分类使用+1,-1表示,当样本被正确分类,那么就是0,即hinge的值为0,那么如果在分隔中的时候,hinge的值为1-真实值与预测值的积。举个例子,当真实值yi是1,被分到正确分类的分类间隔之外,那么yi=1,>1,那么这时候即样本被正确分类hinge值则为0。那么如果是被错误分类,则hinge值就是大于1了。这就是hinge损失函数啦。
4
交叉熵损失函数
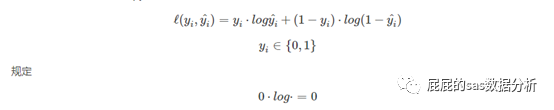
这个函数是在逻辑回归中最大化似然函数推出来,在公式层面的理解,可以看到就是计算样本的预测概率为目标值的概率的对数。这个你不想听公式推导也看下去啦,因为这对于优化问题的理解可以更深刻。

以上的公式中的h(x)代表的样本是目标值的概率,那么模型最极端的预测是什么,y=1的样本的h(x)都为1,y=0的样本的h(x)都是0,那么你这个模型的正确率就是100%,但在实际建模中这个可能性是极低的,所以这时候使用最大似然估计将全部的样本的预测值连乘,那么这时候意味着对于y=1的样本,h(x)的值越大越好,y=0的时候h(x)的值越小越好即1-h(x)的值越大越好,这时候似然估计这种相乘的方式貌似很难衡量那个模型是最好的,所以加上log函数的转化之后再加上一个负号,全部的项变成相加,这时候我们只要求得-ln(l())最小就可以了。这就是交叉熵损失函数。那么这里你可能会问,为什么用的是log,不是用什么exp,幂函数这些,因为log是单调递增的,在将式子从相乘转成相加的同时,又保证了数值越大,ln(x)的值越大。
5
平方误差
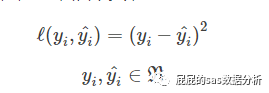
平方差,这个大家很熟啦,线性回归很爱用这个,这个衡量线性关系的时候比较好用,在分类算法中比较少用。
6
绝对误差
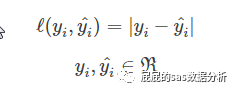
那么这个也是回归中比较常用的,也不做多的解释。
7
指数误差
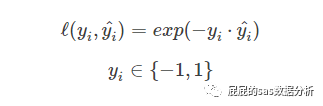
这是adaboosting中的一个损失函数,假设目标变量还是用-1,1表示,那么就以为在上面的公式中,当yi=1的时候,就希望越大越好,即越小越好,同样可推当yi=0的时候。思想跟逻辑回归类似,但是因为这里使用-1,1表示目标变量,所以损失函数有些区别。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330