杀熟、窥私,暗黑的大数据能否成就善良
大数据的热浪,暗潮汹涌。如果现在向你提到「大数据」,大部分人大概都会像S君一样,脑子里闪过一系列的“标志性事件”:窃取5000万Facebook用户数据的Cambridge
Analytical公司,对阴谋论、假新闻和政治广告的精准投喂;李彦宏“用隐私交换便捷性”的争议论调,携程用“大数据杀熟”对用户进行逆向的价格歧视,信用评估的智慧平台ZMAL将更多的有色人种挡在“有信用”的高墙之外的丑闻……
诸如此类,“看上去很美”的大数据反而创造出越来越多信息的垃圾食品,让人上瘾,更难以抗拒。在这个以假乱真、信息污染的世界里,我们不禁好奇,数字民主真的只是幻觉?
要是不在数据流中挖掘商机,也不在在黑箱里窥视隐私,大数据将会把我们带向哪里?其实,除了精确瞄准买买买一族的那些“甜腻”的消费大数据,在全球范围内,还有很多有道德重量的、“美美与共”的数字世界的探路者,其背后有温度的巨量数据,更加值得我们关注。
一、照亮漂泊者:关于苦难的数据
人类学家Joel Robins在其经典文章「Beyond the suffering subject: Toward an anthropology of the good」(《超越受苦难主体:关于善的人类学》)中如是写道:
“那些生活在痛苦和贫困之中,那些饱受暴力与压迫折磨的苦难者,现在站在人类学的中央”。
这种直面社会生活残酷,直面压抑与绝望生命经验的“黑暗人类学”主张(Ortner,2016),也逐渐成为重建数据伦理的重要内容。
它希望数据不是抽离的、冰冷的、佯装价值中立的,而应该是直面黑暗,有切肤之痛的。数字可以照亮我们所“视而不见”的那些人——流离失所的城市流浪者、叙利亚的难民、无处为家的无国籍者……
2017年,《卫报》一项「Bussed Out: How America moves its homeless」的深度调查项目,将目光投向美国大城市中无名的流浪者。关注在美国版的“收容遣送”的城市计划中,无家可归者们颠沛流离的漂泊生活。
卫报用了18个月,爬梳了16个城市,超过20000名流浪者,34240次从此地到他地的被逐之旅。
这张图是27岁的流浪汉Quinn Raber的足迹。他拿着旧金山市为他购买的单程车票,坐上灰狗巴士,穿行2275英里,来到陌生的印第安纳波利斯。
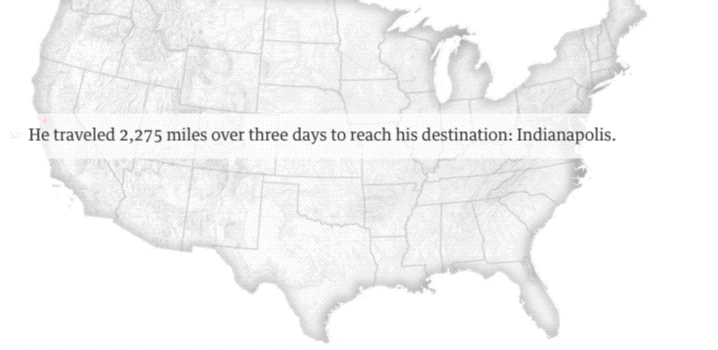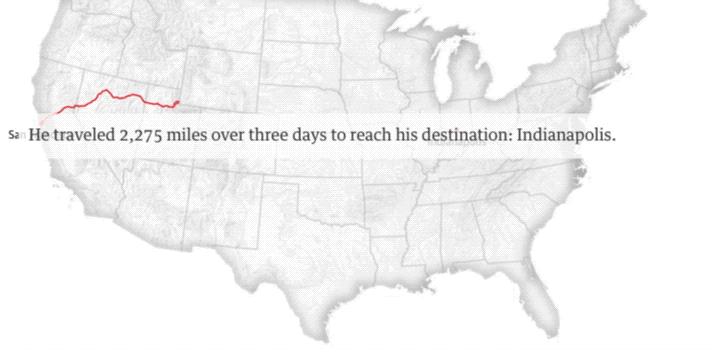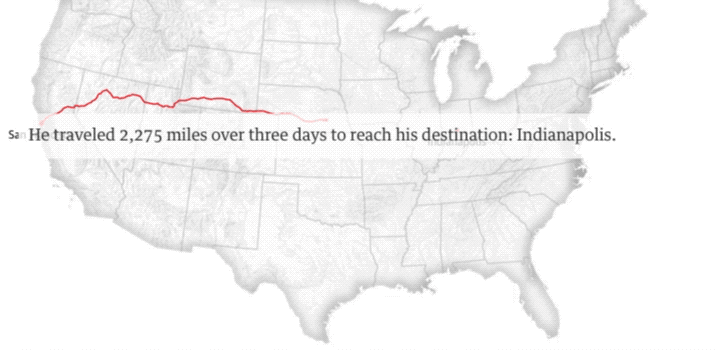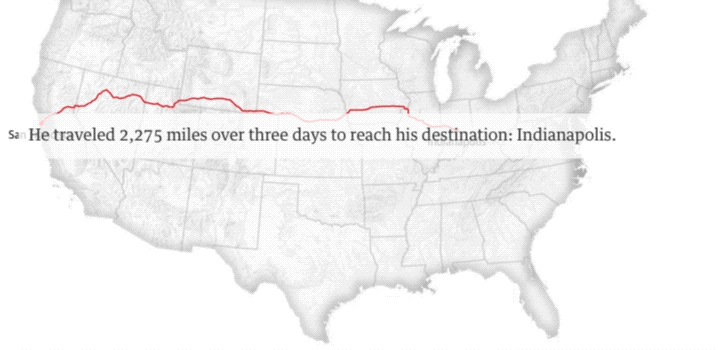
旧金山作为无家可归群体的大本营,从2005年开始实施一项“嫌贫爱富”的旧金山巴士计划。它旨在通过为流浪者提供免费的单程巴士车这种廉价而有效的方式,来削减城市流浪群体的总量。
在过去12年的时间,这种“将问题运往别处”的冷酷治理术富有卓效。就像这张动态图所呈现的一样,一边是10570位无家可归者被灰色的巴士陆续运往他乡,一边越来越少的流浪者有机会进入到旧金山。

纽约这座城市则显得更加的“势利眼”,在《卫报》采集的34240次流浪者离途中,有将近50%来自纽约。而在接受无家可归者的重镇波多黎各,纽约输送了2350名流浪者,比其他的美国城市要多得多。
可是,波多黎各的家庭收入中位数只有19606美元,远不及纽约的60741美元,失业率更是全国平均水平的两倍,这无疑将使流浪者生活雪上加霜。而且,在近九成的被驱逐之旅中,都重复了纽约这种从“富城”到“穷乡”的糟糕方式。
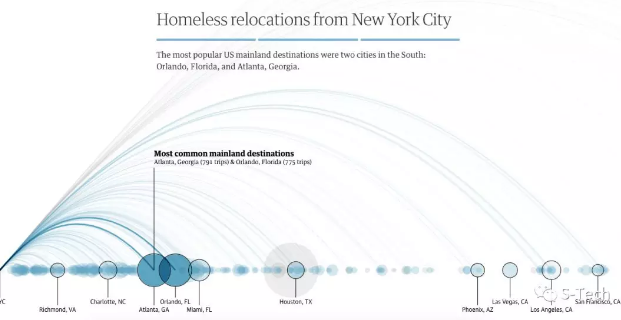
对于这些城市的游民,我们或是视而不见,或是视为“问题”。不愿装睡的《卫报》,将这幅完整的、命如草芥的流浪者们的数字足迹图摆在我们面前。他们如蝼蚁般,从一地驱离到另一地,无处为家。这些地图上流动的点,是一个个灰暗的、苦闷的、饱受侮辱与歧视的生命境况,是我们道德与伦理上的刺,是他者生活的残酷现实,也是我们必须设身处地地去反思的价值问题。

而像卫报这种重建大数据的伦理与道德维度的,还有Sasaki的Understanding Homelessness(理解无家可归者)公共行动,以及博尔扎诺自由大学的People’s Republic of Bolzano(用数字为被污名化的意大利华人社群发声)项目,呈现叙利亚难民跨国流亡之路的Humanizing Syrian Refugee Visualization计划,关注巴西无国籍者的Stateless in Brazil数字行动等等。
二、挖掘历史真相:关于文本的数据
再来看谷歌的一款“黑科技”——Google Ngram
Viewer。作为野心勃勃的谷歌图书项目的重要分支,它囊括了1500年到2008年间5195769册来自于世界各地的书籍,并通过OCR技术将其分解成5000亿个独立的语汇,造就一个史学家和语言学家们难以想象的、巨量无比的语料库。
有学者认为:Google Ngram这样的数字利器,可以帮助我们探寻印刻在语言与文字背后更大的历史真相。
权力怪兽对自由与独立思想的钳制,在这个“黑科技”的照妖镜下就露出了马脚。下图是犹太艺术家Marc Chagall在德文与英文书中的“亮相”词频:
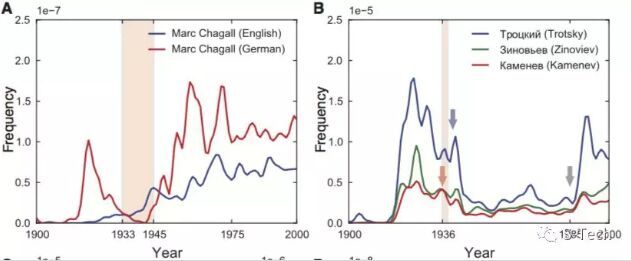
1910年,30岁的他逐渐成为德国艺术界一颗冉冉升起的新星。但随着纳粹势力的甚嚣尘上,Chagall开始成为不合时宜的“异类”,变成现代版“焚书坑儒”的替罪羔羊。1936-1944年纳粹统治时期,他的名字被彻底抹去。但与此同时,他的盛名开始在英文国家里得到认可。
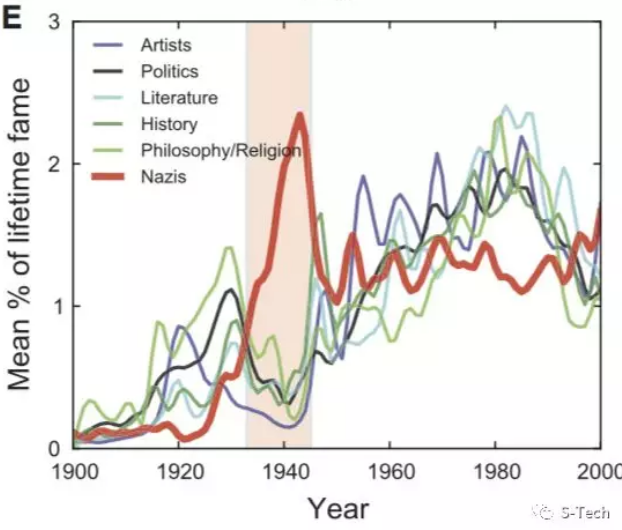
下面这张图,则让我们更系统地理解纳粹势力,如何像“权力的毛细血管”一样,逐渐渗透到社会生活与个人心灵里。1936-1944年间,纳粹党员的名字在公共舞台的出现频率飙升,可艺术家、文学家、哲学家、历史学家和政治学家的词频则跌落至历史谷底。
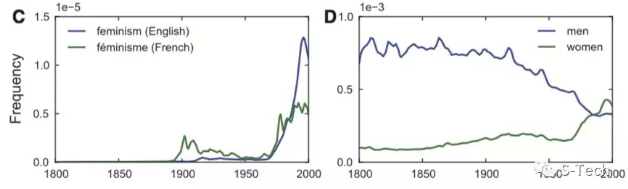
女性主义的研究,也可以在大数据的助力,焕发新的活力。我们可以在这两张曲线图中看到,女性主义(feminism/
Féminisme)从1968年开始,在法语与英语世界中日渐显现,并在80年到90年代成为一股迅速飙升的解放力量。Women与Men这一对性别语汇之间的悬殊落差,也逐渐缩小。80年初,“women”在英文世界终于能顶半边天了。
可是现代女性的平权之路,并非坦途,这注定一场永不停歇的抗争。
这是Google Trends所制作的Me Too Rising专题,它统计了从2017年10月至今,世界各个国家“Me Too” 的动态搜索数据。我们发现:Me Too的浪潮从从北美向全球扩,星星之火,可以燎原。
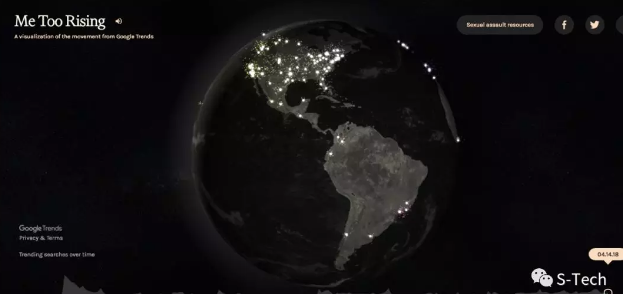
而有几个高频搜索的城市,是出乎我们意料之外的:印度的印多尔、马来西亚的吉隆坡、危地马拉的首都。这也从侧面反映了:Me Too运动有唤醒当地女性权利意识,激发其参与反抗男性霸权集体行动的巨大潜能。
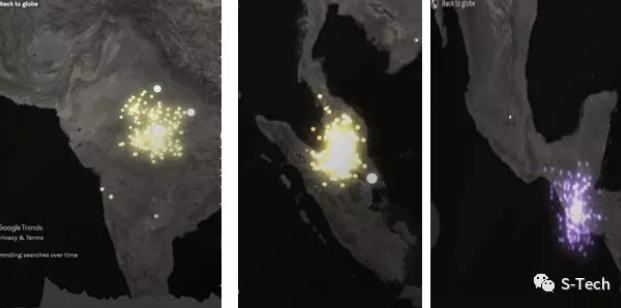
从左至右分别对应: 印多尔、吉隆坡、危地马拉
三、冲破壁垒之墙:关于共享的数据
大数据时代,各个数据王国“分封而治”。离散的数据,不是被密封在民族国家的保险柜里,就是藏在科技巨头们的黑箱中。这种数字割据的状态,常使我们在全球问题中陷入无能,无感的境地。
全球渔业就是最好的例证,各国的海洋捕鱼数据长期以来是不透明的,不开放给公众与研究者,数据标准杂乱不一。这不仅造成了过量猎杀、非法捕鱼、奴隶劳工、海洋污染和渔业资源枯竭等严峻问题,而且使我们很难对全球商业捕鱼有一个整体性的洞察与监测。
2014年,Google, Skytruth和Oceana共同创建非营利组织Global Fishing
Watch。它构建了一个冲破信息藩篱的,透明公开的大数据平台(正如其核心所述Sustainability through
Transparency),我们可以实时追踪商业捕鱼船舶的全球足迹,监测非法海洋捕捞的活动,观察全球海上转运船只的动态。
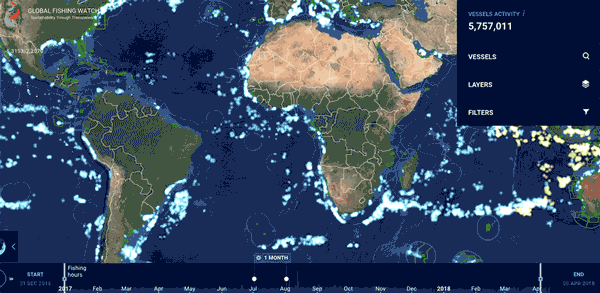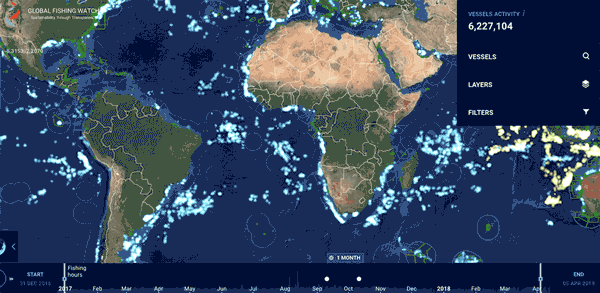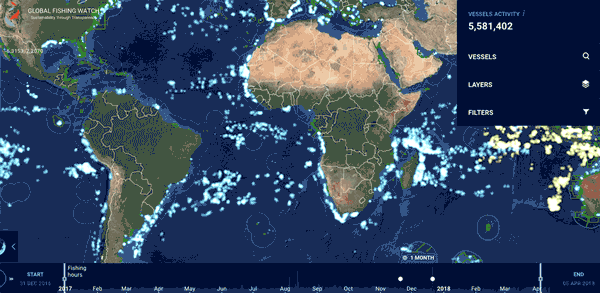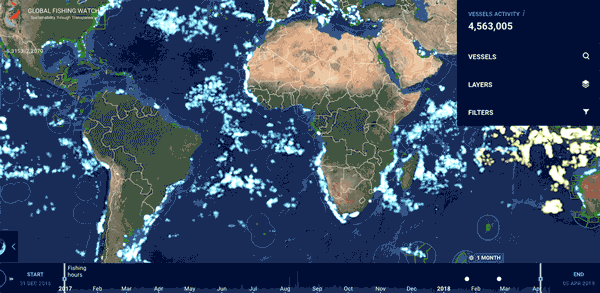
在2012-2016年,它利用卫星监测和谷歌的机器学习工具,共处理了220亿个船舶自动识别的信息,跟踪了7万余艘商业捕鱼船舶,共计4000万小时,200亿千瓦时能耗的渔业活动。
它追踪了世界各地的渔船4.6亿公里的海上活动足迹,这相当于往返月球600次。这个全球共享的数据库,在为地理学家、海洋学家和气象学家们提供了研究的利器的同时,也不断探寻与各个国家之间的数据共享和集体行动(如印度尼西亚,秘鲁将其船舶监测系统的国家数据(VMS)纳入其中)。
不得不说,Global Fishing Watch是数字王国里的“异教徒”,是数字封建割据时代伟大的世界主义先锋。
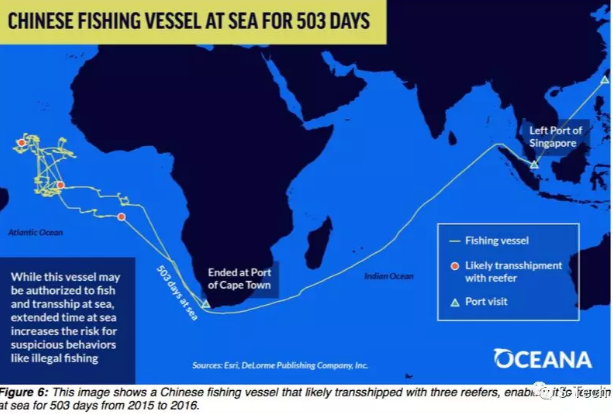
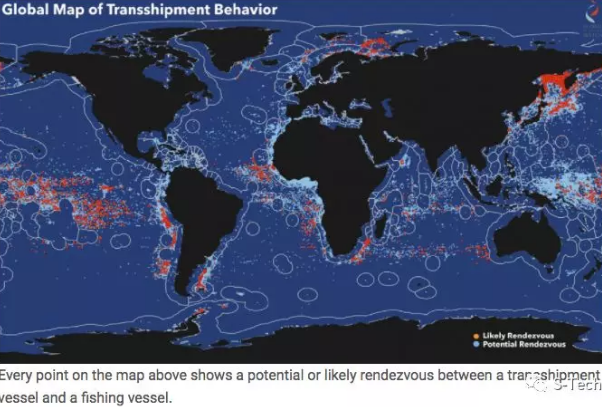
这张是全球渔船转运的热点图。监测海上转运船舶的动态信息非常重要,因为在商业捕鱼活动中,海上中转长期处于监管的真空地带,这使得非法捕捞、强迫劳动、毒品走私和远洋渔船上侵犯人权行为有了可乘之机。
这张图来自于2016年荣获普利策公共服务奖的Seafood from Slaves,这是一艘穿梭于泰国和巴布新几内亚之间的渔船,而这支远洋渔船藏着血汗劳工的恶行。美联社在收集这些远洋捕捞渔船上惨无人道的罪证时,充分借助了大数据与新科技的力量。
遥感与数字地图公司通过AIS信号确定了这艘船舶的海上活动轨迹,太空影像服务商则透过卫星捕捉到这艘渔船海上转运的高分辨图像,其长期深藏不露的海上罪行,现了原形。
今天的文章,我们主要罗列了三种应用大数据的案例,在这些巨量的数据背后,可能没有所谓消费行为和用户分析,但却有演变历史的真相和直面苦难的真实;可能没有办法谋求商业模式,但却可以做到高效的犯罪监管。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330