【数据质量】--指标治理的三个步骤及必要条件
“同名同义”、“同义同名”、“异名异义”,三个词,即是指标治理的三个步骤。“由上推下,由小及大”是内在逻辑。在展开说明之前,我们先全盘阐述数据治理的范畴和逻辑关系。
数据治理的范畴和逻辑关系
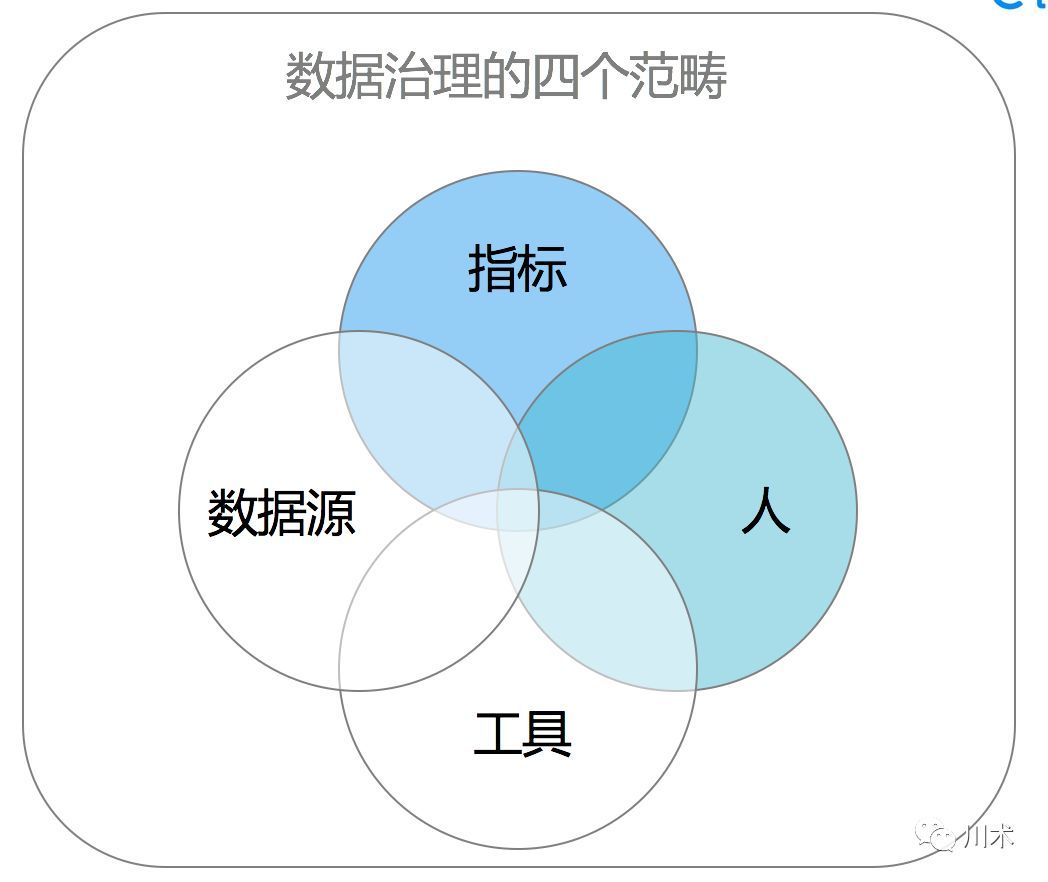
数据治理,即为了提升数据质量,我们需要从指标、人、工具、数据源四方面着手。在我看来,指标治理是最显性也是最优先的。以指标治理为核心(这是决策层最有体感的部分),才能形成从上至下的压力,进而将人的意识和习惯、工具的应用和维护、数据源的扩展和萃取三部分的工作可持续地做好。所谓“由上推下”。
又一个大前提需要说明:指标治理是有范围的,并不能武断地进行全公司或者全事业部的指标统一;建议是先在具体部门或者业务线中,做好指标治理工作,进而寻求更大范围统一的可能性。所谓“由小及大”。
指标治理的步骤说明
有了上面的认知,我们对指标治理步骤展开说明。归纳为下图的内容。

首先,我们追求指标的同名同义。从两个方面来达成:
第一,当我们遇到两个相同名称的指标,数值却不相同时,需要做检查,若是计算错误就及时修正,若是口径不同,则将两个名称区别开,记住一定要规范命名(规范命名的方式在下一篇中会说明);
第二,当我们在做数据产品或者研究时,需要定义某种指标的时候,要优先与现有的指标进行对照,如果重叠,在不产生理解歧义的情况下,继承现有指标命名;若继承名称不合适或者不存在类似的指标,则采用规范的命名方式,将自己所使用的指标与现有的指标区别开。
当然,在同名同义阶段,有一种最讨巧而实用的方式,就是都按命名规范,先定义成与其他指标不同名字,并在产出结果中给出详细的口径说明。
接着是同义同名。在这个过程中,需要由指标治理的负责人,有规律地对各业务人员和分析师在使用的指标进行遍历检查。发现有计算口径或者业务含义相同或接近的指标,进行名称上的整合。需要非常注意,并不是所有意义相同或者相近的指标都要整合,我们千万不能一根筋做事情。比如完全处在两个业务线或者两种主题下的指标,就没有必要非得统一成一个名称。这反而导致本业务线内的指标名称体系的混乱。
最后,是追求异名异义。为什么说“追求”?因为这个状态只要去接近就可以,而没必要真的达到。我们真正要达到的是“不存在同名异义,而存在异名同义”。
首先是人的意识。不管是管理者、决策者还是执行者,都要具备数据质量意识,在日常接触数据产出时,脑中始终有所“戒备”,养成“遇数三问”的好习惯。

其次,需要有指标维护的工具,可成为指标平台的工具,由指定人员进行管理和维护。在这个工具上,数据使用者能方便的查阅具体指标的名称、计算口径、样例代码、负责人、变更历史等信息。
接着,指标变更需要有一定的流程,尤其是如上篇所说的“评价流”中的指标。应该有一个上至决策层的审批流程,毕竟这是决策层重要的判断依据。
最后,也是最重要的,分析师或者其他数据结果的生产者,一定要具备良好的习惯(也可以上升为职业素养):
-
在任何数据产出中,一定标注规范的指标名称、计算口径。
-
在取数代码或者分析代码中,要有清晰的注释来说明计算逻辑和字段定义。
-
当发现其他人的产出中,有忽视数据质量的情况时,一定要给予当事人和数据使用方提醒;必要的时候向上反馈。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330