拥抱大数据需要大智慧
近年来,有关大数据的热点话题一浪高过一浪,关注大数据应用的人也越来越多。总体来说,人们对大数据的前景持乐观态度,比如谈到大数据的技术特征,人们最容易想起的就是4个“v”:vast(数量庞大)、variety(种类繁多)、velocity(增长迅速)和value(总价值高)。这些都没错,但仔细一想,它们都是偏重说明大数据的正面优势的。但其实,大也有大的难处,大数据也不可避免地存在着一些负面劣势。结合笔者的从业经验,大数据的负面劣势可以概括为4个“n”,下面逐一说明每个n的含义。
inflated大数据是肥胖的。大数据的大不仅仅体现在数据记录的行数多,更体现在字段变量的列数多,这就为分析多因素之间的关联性带来了难度。哪怕是最简单的方差分析,计算一两个还行,计算一两百个就让人望而生畏了。
unstructured大数据是非结构化的。大数据的结构也是非常复杂的,既包括像交易额、时间等连续型变量,像性别、工作类型等离散型变量这样传统的结构化数据,更增添了如文本、社会关系网络,乃至语音、图像等大量新兴的非结构化数据,而这些非结构化数据蕴含的信息量往往更加巨大,但分析手段却略显单薄。
incomplete大数据是残缺的。在现实的世界里,由于用户登记的信息不全、计算机数据存储的错误等种种原因,数据缺失是常见的现象。在大数据的场景下,数据缺失更是家常便饭,这就为后期的分析与建模质量增加了不确定的风险。
abnormal大数据是异常的。同样,在现实的世界里,大数据里还有不少异常值(outlier)。比如某些连续型变量(如一个短期时间内的交易金额)的取之太大,某些离散型变量(如某个被选购的产品名称)里的某个水平值出现的次数太少,等等。如果不删除,很可能干扰模型系数的计算和评估;如果直接删除,又觉得缺乏说服力,容易引起他人的质疑。这使得分析人员落到了一个进退两难的境地。
如果不能处理好这些不利因素,大数据应用的优势很难发挥出来。想要拥抱大数据,并不是一项在常规条件下数据分析的简单升级,而是一项需要大智慧的综合工作。STIR(唤醒)策略是笔者在实践工作中提炼出来的、能够在实际工作中有效克服大数据负面劣势的应对方法。具体来说,STIR策略包含了四种技术手段,目前都已经有机地整合在统计分析与数据挖掘专业软件JMP中了,它可以用来解决上文提出的四个问题,下面将分别说明。
Switching Variables切换变量
它是用来解决大数据“残缺”问题的。通过“列转换器”、“动画播放”等工具,海量因素之间的关联性分析变得十分简单、快捷,还可以根据需要对关联性的重要程度进行排序,大数据分析的效率由此得到大幅提升。
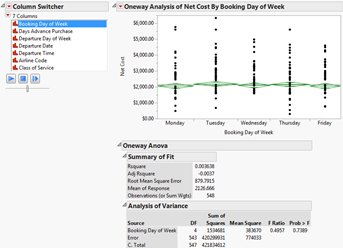
基于JMP软件的关联性分析筛选的界面
Text Mining文本挖掘
它是用来解决大数据“非结构化”问题的。通过先对文字、图像等新媒体信息源进行降维、去噪、转换等处理,产生结构化数据,再用成熟的统计分析和数据挖掘方法进行评价和解释。这样一来,大数据的应用范围得到了极大的拓展。
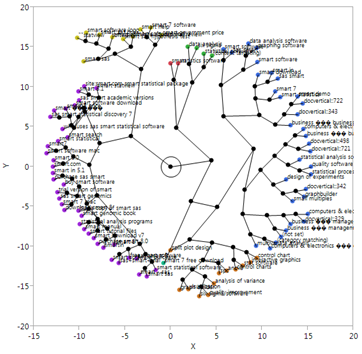
基于JMP软件的文本分析结果的最终展现界面
Imputation缺失数赋值
它是用来解决大数据“残缺”问题的。在有missing data的时候,我们并不完全排斥直接删除的方法,但更多的时候,我们会在条件允许的情况下,用赋值的方法去替代原先的缺失值。具体的技术很多,简单的如计算平均值、中位数、众数之类的统计量,复杂的如用回归、决策树、贝叶斯定理去预测缺失数的近似值等。这样一来,大数据的质量大为改观,为后期的分析与建模奠定了扎实的基础。
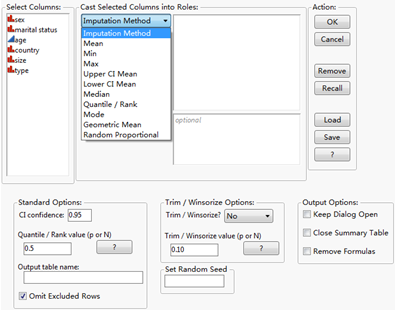
基于JMP软件的缺失数赋值方法选择的操作界面
Robust Modeling稳健建模
它是用来解决大数据“异常”问题的。在融入了自动识别、重要性加权等处理手段后,分析人员既直接消除了个别强影响点的敏感程度,又综合考虑了所有数据的影响,增强了模型的抗干扰能力,使得模型体现出良好的预测特性,由此做出的业务决策自然变得更加科学、精准。
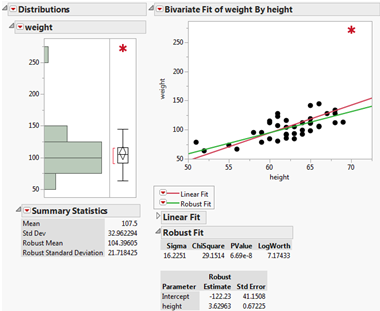
基于JMP软件的模型稳健拟合的报表界面
总之,我们必须要对大数据有一个全面、客观的认识。只有在不同的业务和数据背景下采用不同的战略战术,才能在大数据时代,真正发挥大数据的杠杆作用,有效提高企业的运营效率和市场竞争力。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330