Python增量循环删除MySQL表数据的方法
有一业务数据库,使用MySQL 5.5版本,每天会写入大量数据,需要不定期将多表中“指定时期前“的数据进行删除,在SQL SERVER中很容易实现,写几个WHILE循环就搞定,虽然MySQL中也存在类似功能,怎奈自己不精通,于是采用Python来实现
话不多少,上脚本:
# coding: utf-8
import MySQLdb
import time
# delete config
DELETE_DATETIME = '2016-08-31 23:59:59'
DELETE_ROWS = 10000
EXEC_DETAIL_FILE = 'exec_detail.txt'
SLEEP_SECOND_PER_BATCH = 0.5
DATETIME_FORMAT = '%Y-%m-%d %X'
# MySQL Connection Config
Default_MySQL_Host = 'localhost'
Default_MySQL_Port = 3358
Default_MySQL_User = "root"
Default_MySQL_Password = 'roo@01239876'
Default_MySQL_Charset = "utf8"
Default_MySQL_Connect_TimeOut = 120
Default_Database_Name = 'testdb001'
def get_time_string(dt_time):
"""
获取指定格式的时间字符串
:param dt_time: 要转换成字符串的时间
:return: 返回指定格式的字符串
"""
global DATETIME_FORMAT
return time.strftime(DATETIME_FORMAT, dt_time)
def print_info(message):
"""
将message输出到控制台,并将message写入到日志文件
:param message: 要输出的字符串
:return: 无返回
"""
print(message)
global EXEC_DETAIL_FILE
new_message = get_time_string(time.localtime()) + chr(13) + str(message)
write_file(EXEC_DETAIL_FILE, new_message)
def write_file(file_path, message):
"""
将传入的message追加写入到file_path指定的文件中
请先创建文件所在的目录
:param file_path: 要写入的文件路径
:param message: 要写入的信息
:return:
"""
file_handle = open(file_path, 'a')
file_handle.writelines(message)
# 追加一个换行以方便浏览
file_handle.writelines(chr(13))
file_handle.close()
def get_mysql_connection():
"""
根据默认配置返回数据库连接
:return: 数据库连接
"""
conn = MySQLdb.connect(
host=Default_MySQL_Host,
port=Default_MySQL_Port,
user=Default_MySQL_User,
passwd=Default_MySQL_Password,
connect_timeout=Default_MySQL_Connect_TimeOut,
charset=Default_MySQL_Charset,
db=Default_Database_Name
)
return conn
def mysql_exec(sql_script, sql_param=None):
"""
执行传入的脚本,返回影响行数
:param sql_script:
:param sql_param:
:return: 脚本最后一条语句执行影响行数
"""
try:
conn = get_mysql_connection()
print_info("在服务器{0}上执行脚本:{1}".format(
conn.get_host_info(), sql_script))
cursor = conn.cursor()
if sql_param is not None:
cursor.execute(sql_script, sql_param)
row_count = cursor.rowcount
else:
cursor.execute(sql_script)
row_count = cursor.rowcount
conn.commit()
cursor.close()
conn.close()
except Exception, e:
print_info("execute exception:" + str(e))
row_count = 0
return row_count
def mysql_query(sql_script, sql_param=None):
"""
执行传入的SQL脚本,并返回查询结果
:param sql_script:
:param sql_param:
:return: 返回SQL查询结果
"""
try:
conn = get_mysql_connection()
print_info("在服务器{0}上执行脚本:{1}".format(
conn.get_host_info(), sql_script))
cursor = conn.cursor()
if sql_param != '':
cursor.execute(sql_script, sql_param)
else:
cursor.execute(sql_script)
exec_result = cursor.fetchall()
cursor.close()
conn.close()
return exec_result
except Exception, e:
print_info("execute exception:" + str(e))
def get_id_range(table_name):
"""
按照传入的表获取要删除数据最大ID、最小ID、删除总行数
:param table_name: 要删除的表
:return: 返回要删除数据最大ID、最小ID、删除总行数
"""
global DELETE_DATETIME
sql_script = """
SELECT
MAX(ID) AS MAX_ID,
MIN(ID) AS MIN_ID,
COUNT(1) AS Total_Count
FROM {0}
WHERE create_time <='{1}';
""".format(table_name, DELETE_DATETIME)
query_result = mysql_query(sql_script=sql_script, sql_param=None)
max_id, min_id, total_count = query_result[0]
# 此处有一坑,可能出现total_count不为0 但是max_id 和min_id 为None的情况
# 因此判断max_id和min_id 是否为NULL
if (max_id is None) or (min_id is None):
max_id, min_id, total_count = 0, 0, 0
return max_id, min_id, total_count
def delete_data(table_name):
max_id, min_id, total_count = get_id_range(table_name)
temp_id = min_id
while temp_id <= max_id:
sql_script = """
DELETE FROM {0}
WHERE id <= {1}
and id >= {2}
AND create_time <='{3}';
""".format(table_name, temp_id + DELETE_ROWS, temp_id, DELETE_DATETIME)
temp_id += DELETE_ROWS
print(sql_script)
row_count = mysql_exec(sql_script)
print_info("影响行数:{0}".format(row_count))
current_percent = (temp_id - min_id) * 1.0 / (max_id - min_id)
print_info("当前进度{0}/{1},剩余{2},进度为{3}%".format(temp_id, max_id, max_id - temp_id, "%.2f" % current_percent))
time.sleep(SLEEP_SECOND_PER_BATCH)
print_info("当前表{0}已无需要删除的数据".format(table_name))
delete_data('TB001')
delete_data('TB002')
delete_data('TB003')
执行效果:
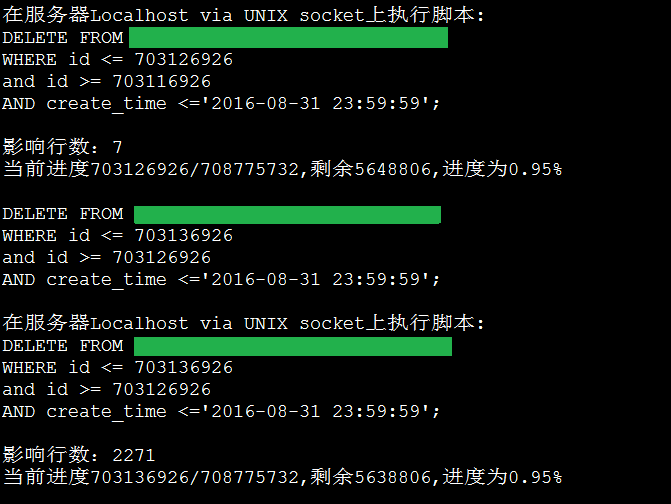
实现原理:
由于表存在自增ID,于是给我们增量循环删除的机会,查找出满足删除条件的最大值ID和最小值ID,然后按ID 依次递增,每次小范围内(如10000条)进行删除。
实现优点:
实现“小斧子砍大柴”的效果,事务小,对线上影响较小,打印出当前处理到的“ID”,可以随时关闭,稍微修改下代码便可以从该ID开始,方便。
实现不足:
为防止主从延迟太高,采用每次删除SLEEP1秒的方式,相对比较糙,最好的方式应该是周期扫描这条复制链路,根据延迟调整SLEEP的周期,反正都脚本化,再智能化点又何妨!
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330