大数据时代出现的必然性
大数据是当下非常火爆的一个词,人人都在谈论大数据。但大数据的定义是什么?它到底是如何出现的?它有什么特别之处?它最大的应用领域在哪里?它的发展方向是什么?对于以上问题,其实大多数人是弄不清楚的。
1)大数据时代出现的必然性
大数据和云计算这两个词经常被同时提到,很多人误以为大数据和云计算是同时诞生的、具有强绑定关系。其实这两者之间既有关联性,也有区别。云计算指的是一种以互联网方式来提供服务的计算模式,而大数据指的是基于多源异构、跨域关联的海量数据分析所产生的决策流程、商业模式、科学范式、生活方式和关联形态上的颠覆性变化的总和。大数据处理会利用到云计算领域的很多技术,但大数据并非完全依赖于云计算;反过来,云计算之上也并非只有大数据这一种应用。
云计算的起源可以追溯到 2003 年末 Amazon 公司工程师 Chris Pinkham 提交给 CEO Jeff Bezos 的一篇论文中的一个设想:将 Amazon 内部使用的计算基础设施开放给全世界的开发者。次年 11 月,Amazon 发布了第一版云计算服务:Simple
Queue Service。Simple Queue Service 再往后发展至 2006 年,演变成立今天著名的 AWS(Amazon
Web Sercice)。同在 2006 年,Google 公司 CEO Eric Schmidt 首次公开提出了“云计算”(Cloud Computing)的这一概念,云计算也在这一年开始变得广为人知。
大数据这个词的流行却晚了好几年——直到 2009 年,大数据这个说法才逐渐开始在互联网圈内传播。但仅仅在互联网领域流行,仍然不足以引起普遍关注,因为纯互联网经济毕竟只占全球经济总量的很小一部分。而大数据概念真正变得火爆,却是因为美国奥巴马政府在 2012 年高调宣布了其“大数据研究和开发计划”——美国政府希望利用大数据解决一些政府部门面临的非常重要的问题,该计划由横跨 6 个政府部门的 84 个子课题组成。这标志着大数据真正开始进入主流的传统线下经济。
大数据出现的时间点自有它深刻的原因。2009 年至 2012
年这段时间正是电子商务在包括中国在内的全球全面开花的几年。众所周知,互联网领域有 3 大类商业模式:广告、游戏和电子商务。而电子商务又是第 1
个真正将纯互联网经济与传统经济嫁接在一起诞生的混合模式。准确地说,正是互联网与传统经济的碰撞,才真正催生出了今天几乎全民关注的“大数据”。大数据横跨了互联网产业与传统产业,而且大数据真正广阔的应用领域其实也正是比纯互联网经济大得多的传统产业。
从数据量的角度来看,在电子商务模式出现以前,传统企业的数量增长缓慢。传统企业的数据仓库中的数据大多数来自于交易型数据,而交易这种行为处于用户消费决策漏斗的最底部,这就决定了交易前的各种浏览、搜索、比较等用户行为数据的都量远远超过交易数据。电子商务模式使得企业可以采集到用户的浏览、搜索、比较等行为,这就导致企业的数据规至少提升了一个数量级。现在日益流行的移动互联网以及将来会流行的物联网又必将使数据量提高两三个数量级。从这个角度来讲,大数据时代是必然会出现的。
从 IT 产业的发展来看,第一代 IT 巨头大多是 2B 的,比如 IBM、Microsoft、Oracle、SAP 这类传统 IT
企业;第二代 IT 巨头大多是 2C 的,比如 Yahoo、Google、Amazon、Facebook 这类互联网企业。一个有意思的现象是:大数据时代前,这两类公司彼此之间基本是井水不犯河水,我们很少看见这两类公司的老板们在一起坐而论道;但在当前这个大数据时代,这两类公司已经开始直接竞争。比如
Amazon 已经开始提供云模式的数据仓库服务,直接抢占 IBM、Oracle 的市场。这个现象出现的本质原因是:在互联网巨头的带动下,传统
IT 巨头的客户普遍开始从事电子商务业务,正是由于客户进入了互联网,所以传统 IT
巨头们不情愿地被拖入了互联网领域。如果他们不进入互联网,他们业务必将萎缩。所以第三代 IT 巨头可能会是 2B 与 2C 融合的 IT 公司。
2)大数据的核心内涵
大数据概念虽然非常火爆,但少有人真正理解大数据的核心内容。一个普遍而且严重的误解就是:大数据= 数据大,即大数据就是量大的数据。事实上,除了数据量大这个字面意义,大数据还有两个更重要的特征:
1) 跨领域数据的交叉融合。相同领域数据量的增加是加法效应,不同领域数据的融合是乘法效应
2) 数据的流动。数据必须流动,流动产生价值
对于第 1) 点,百分点推荐系统研究中心实验结果显示:百分点公司有 3 家客户,分别是从事服装、化妆品和箱包销售的电商,百分点向这 3
家客户提供个性化商品推荐服务,即:百分点挖掘用户的偏好,不同的用户上同一家电商网站时,向他们展现不同的服装、化妆品或箱包,从而提高电商的转化率和客单价。我们做过两种测试:
a) 将每家网站的数据隔离。当每家网站自身的数据量增加到以前的 4 倍时,推荐效果大约能提高 5%;
b) 将三家网站的数据在去除敏感信息之后进行某种融合。融合后的数据大致是与单家网站的数据的 3
倍,比第一种情况数据量还少。但利用融合后的数据进行数据挖掘时,推荐效果能提升
30%,而且推荐商品并未发生变化,仍然是:用户上服饰类网站时只看见服装、上化妆品网站时只看见化妆品、上箱包网站时只看见箱包。
解释得详细一点,上述实验说明:对同一个消费者,如果我们要向其推荐服装。第一种方法是我们根据他过去的 4
次购买服装的行为来预测其下一次可能会购买的服饰;第二种方法是我们根据他过去分别购买服装、化妆品和箱包的各 1
次行为来预测其下一次可能会购买的服饰。两种方法的基于的用户行数分别是 4 次和 3 次,但第二种方法的效果明显更好。
对于第 2) 点,其实 10
多年前传统企业开始做数据仓库时,数据仓库从业者经常强调一个观点:企业级数据仓库的目标是让不同部门的数据流动起来,各个部门数据割裂,数据的价值就得不到发挥。到了今天的互联网时代,我们发现即使企业已经打通了内部各个部门之间的数据,但与整个互联网比起来,数据量仍然微乎其微,数据应该以互联网为媒介在企业之间某种形式的流动。参照“企业级数据仓库”的概念,现在已经开始出现了“互联网数据仓库”的概念:就是企业通过互联网渠道将与自己相关的外部数据与内部数据进行整合,从而形成“互联网数据仓库”。百分点已经在零售与媒体领域比较成功地打造了“开放数据联盟”,该联盟的成员可以在公允、安全的情况下基于该联盟建立起自己的“互联网数据仓库”,从而享用海量数据的价值。
3)大数据的应用领域
大数据的起源要归功于互联网与电子商务,但大数据最大的应用前景却在传统产业。一是因为几乎所有传统产业都在互联网化,二是因为传统产业仍然占据了国家 GDP 的绝大部分份额。
哪些传统企业最需要大数据服务呢?至少有 3 类企业:
1) 对大量消费者提供产品或服务的企业
2) 做小而美模式的中长尾企业
3) 面临互联网压力之下必须转型的传统企业
第 1) 类企业都需要利用大数据精准分析不同消费者的偏好,提高营销和服务的质量;第 1) 类企业都需要利用大数据分析精准定位自己的客户群;第 3) 类企业主要指哪些正在遭受来自互联网的新玩家冲击的传统企业,此类企业自然都需要利用互联网和大数据作为自我进化的工具。当然,第 3) 类企业与前 2 类企业有重叠。
具体来讲,中国最需要大数据服务的行业就是受互联网冲击最大的产业,首先是线下零售业,其次是金融业。
受电商的冲击,国内很多零售巨头都增长严重放缓,甚至遭遇负增长,线下零售已经到了不得不变革的危机关头。我们也看到了银泰百货、王府井百货、万达集团这些具有创新意识的传统巨头开始利用互联网和大数据来改造线下商业。其中银泰百货以手机为载体、利用 O2O 方式进行双线数据挖掘的创新非常值得借鉴。
而金融行业就更加特殊:金融业并不销售任何实体商品,它自诞生起就是基于数据的产业。由于国家管制,金融业在前几年享受了非常好的政策红利,内部变革动力不足。而目前金融业已经逐渐开始放松管制,新兴的金融机构必将利用互联网以及大数据工具向传统金融巨头发起猛烈攻击。而传统金融机构在互联网方面的技术积累和数据积累都不足,要快速应对新进入者的挑战,必然需要大数据服务。我们也看到了中信银行信用卡中心、招商银行信用卡中心已经在开始利用互联网大数据进行创新。
那么传统产业需要什么样的大数据服务呢?这主要包括 3 层:
1) 基于大数据的行业垂直应用。每个行业都有自己的特点,所以自然会存在行业应用的需求;
2) 顾客标签与商品标签的整理。不管什么行业,都需要精细化整理自己顾客的属性标签以及商品属性标签,而且这些标签必须能够细化到单个顾客和单个商品。标签是行业应用的基础;
3) 企业内部和外部数据的整合与管理。要给顾客和商品打标签,首先必须整合企业内部和外部数据,尤其是日益重要和庞大的外部数据。
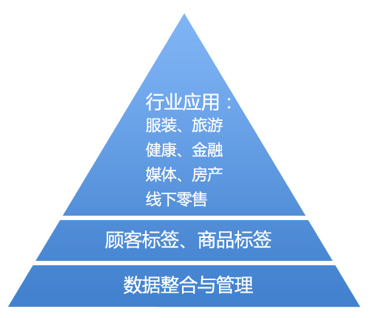
图:传统企业需要的大数据服务
第 3 层和第 2 层的方法相对比较通用,行业特殊性相对较少。百分点已经在第 3 层和第 2 层做出了比较成熟的产品,并且也开始在第 1 层做出了一些具体的行业应用产品,比如针对服饰行业的时尚服饰搭配系统。
4)大数据的发展方向
大数据产业未来会向什么方向发展?随着数据逐渐成为企业的一种资产,数据产业会向传统企业的供应链模式发展,最终形成“数据供应链”。拿钢铁产业来讲,铁矿石公司从矿场中挖出矿石,经过粗加工,卖给钢铁企业;钢铁企业再进行精细一点的加工,将板材、钢条卖给下游制造业公司;这些制造业公司做出汽车、飞机、门窗、电脑等产品卖给下游公司。这个产业链中存在找矿、运输、加工等诸多环节,每个环节都有对应的企业。

图:传统企业的供应链
在“数据供应链”中,存在数据、数据整合与挖掘工具以及数据应用这 3
大环节。数据就好比矿场的矿石;数据整合与挖掘工具就好比钢厂的冶炼炉;而精准营销、服饰搭配等数据应用就好比汽车、电脑等可以出售给消费者的产品。企业在数据供应、数据整合与挖掘、数据应用等所有环节都需要专业的服务。这里尤其有两个明显的现象:
1) 外部数据的重要性日益超过内部数据。在互联互通的互联网时代,单一企业的内部数据与整个互联网数据比较起来只是沧海一粟;
2) 能提供包括数据供应、数据整合与加工、数据应用等多环节服务的公司会有明显的综合竞争优势。
5) 什么样的大数据企业会胜出
常有大数据从业者以及投资人和我们探讨一个问题:大数据产业中,什么样的企业会最终胜出?这是一个很难回答的问题,而且即使回答了,三五年内可能都无法判断其正确性。但从“数据供应链”中的各个环节来分析,还是可以得出一些具有参考价值的结论。
1)
数据供应。在互联网没有流行的时代,企业做数据仓库、商业智能、数据挖掘等系统时采用的数据基本都来自于企业内部,企业几乎无法获取外部数据,所以很少有专业的数据供应商。互联网改变了这一局面,将来会有专业的数据供应商。但既然是因为互联网的出现导致了数据供应商的出现,那么反过来数据供应商就必须具有很强的互联网基因;
2)
数据整合与挖掘。数据挖掘工具供应商在非互联网时代就早已存在。但互联网时代使得企业的数据量激增、数据类型发生极大变化(不同于传统的来自于单一领域的结构化数据,互联网数据以跨域的非结构化数据为主),传统的数据挖掘工具供应商的技术和方法已经很难适应。要跟上时代的变化,数据挖掘技术与工具应用商必须具备互联网公司的海量数据处理和挖掘的能力;
3) 数据应用。具体的行业应用与传统行业的业务关系密切,要做好行业应用,最好需要有服务传统行业的经验,了解传统行业的内部运作模式。这时候仅仅具有 2C 经验的互联网基因的公司又稍显不足。
综合起来看,如果一家大数据从业公司同时兼备互联网数据获取能力、互联网技术、互联网执行力,又有做 2B 服务的经验,那么这家公司将比较容易取得领先优势。这个结论其实一点也不奇怪:如本文开篇所述,大数据本来就是互联网与传统产业碰撞时的产物。
用“方兴未艾”这个词来形容大数据产业的发展阶段都还为时过早,目前的大数据产业只能说是小荷才露尖尖角。国内企业在第 1 代 IT 产业(硬件和软件产业)中是明显落后国外企业的;在第 2 代 IT 产业(互联网产业)中,国内企业已经与国外企业差距不大甚至在很多方面超过了国外企业;希望在第 3 代 IT 产业(云计算和大数据)浪潮中,国内企业能够完全赶上并且超过国外企业,我们也认为这是很有可能的。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330