基于标记数据学习降低误报率的算法优化
无论是基于规则匹配的策略,还是基于复杂的安全分析模型,安全设备产生的告警都存在大量误报,这是一个相当普遍的问题。其中一个重要的原因是每个客户的应用场景和数据都多多少少有不同的差异,基于固定判断规则对有统计涨落的数据进行僵化的判断,很容易出现误判。
在没有持续人工干预和手动优化的情况下,策略和模型的误报率不会随着数据的积累而有所改进。也就是说安全分析人员通过对告警打标签的方式,可以将专业经验传授给智能算法,自动得反馈到策略和模型当中,使之对安全事件做出更精准的判断。本文介绍利用专家经验持续优化机器学习的方法,对告警数据进行二次分析和学习,从而显著地降低安全威胁告警的误报率。
为了降低误报率,当前大体上有两种技术途径:
根据不同客户的各种特定情况修正策略和模型,提高策略或者模型的适应能力;
定期(如每月一次)对告警进入二次人工分析,根据分析结果来调整策略和模型的参数配置。
这两种方法对降低误报率都有一定的作用。但是第一种没有自适应能力,是否有效果要看实际情况。第二种效果会好一些,但是非常耗时耗力,而且由于是人工现场干预和调整策略和模型,出错的概率也非常高。
MIT的研究人员[1]
介绍了一种将安全分析人员标记后的告警日志作为训练数据集,令机器学习算法学习专家经验,使分析算法持续得到优化,实现自动识别误报告警,降低误报率的方法(以下简称“标签传递经验方法”)。这种把安全分析人员的专业智能转化成算法分析能力的过程,会让分析算法随着数据的积累而更加精确。继而逐渐摆脱人工干预,提高运维效率。如下图所示:
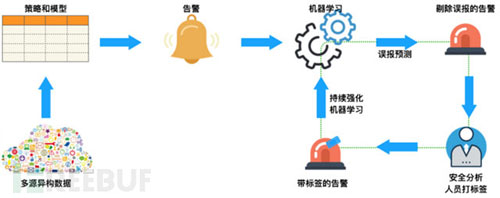
下面我们通过基于“频繁访问安全威胁告警”模拟的场景数据来介绍一下实现机制。
什么是频繁访问模型?逻辑比较简单:一段时间内(比如1分钟),一个攻击者对系统的访问次数显著高于普通访问者的次数。此告警规则可以用简单的基于阈值,或者是利用统计分布的离异概率。基于此,我们先模拟一些已经被安全分析人员打过标签的告警数据。根据实际应用经验,我们尽量模拟非常接近实际场景的数据。如下图:
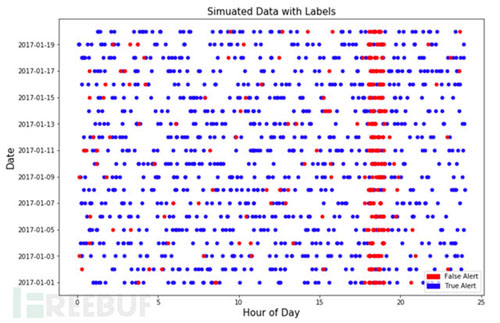
关于模拟数据的介绍:
总共模拟了20天的告警数据,从2017-01-01到2017-01-20。前10天的数据用来训练模型,后10天的数据用来衡量模型的表现;
每个告警带有是否误报的标签。红色代表误报,蓝色代表准确告警。
关于模拟数据的假设:
误报聚集在某个时间段,模拟数据假设的范围是18:00-19:00。在安全运维实践中,的确存在某个特定的时间段,由于业务逻辑或者系统原因导致误报增多的现象。所以上述假设是合理的,告警时间可以作为有效的特征值。但并不是所有的误报都聚集在这个时间段,同时并不是这个时间段的所有告警都是误报;
误报大多来自于一批不同的IP。所以访问来源IP也是有用的特征值;
任何数据都不是完美的,所以在模拟数据中加入了~9%的噪音。也就是说再完美的智能模型,误报率也不会低于9%。
这些假设在实际的应用场景中也是相对合理的。如果误报是完全随机产生的,那么再智能的模型也不能够捕捉到误报的提出信号。所以这些合理的假设帮助我们模拟真实的数据,并且验证我们的机器学习模型。
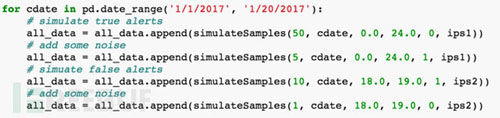
简要模拟数据的代码实现:
下图显示利用PCA降维分析的可视化结果,可以看到明显的分类情况:
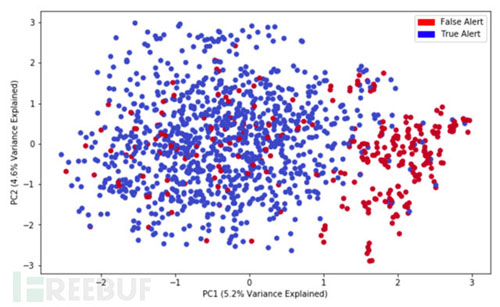
红色代表误报,蓝色代表正确告警。基于设定特征值的降维分析可以得到两个聚集,即误报和非误报有明显的区分的,也就是说误报的是有一定规律,不是完全随机的,因此是可以被机器学习捕捉到的。
简要代码实现:

基于模拟数据,我们想要达到的目的是通过持续的强化机器学习能够降低误报率。所以我们采取的策略是:
训练一天的数据2017-01-01,测试10天的数据2017-01-11到2017-01-20;
训练两天的数据2017-01-01到2017-01-02,测试10天的数据2017-01-11到2017-01-20;
以此类推,来看通过学习越来越多的数据,在测试数据中的误报率是否能够得到不断的改进。
简要代码如下:
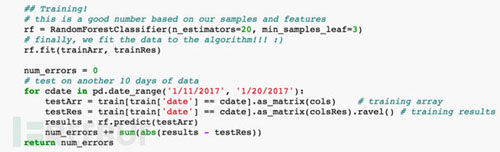
此安全威胁场景相对简单,我们不需要太多的特征值和海量的数据,所以机器学习模型选择了随机森林(RandomForest),我们也尝试了其他复杂模型,得出的效果区别不大。测试结果如下:
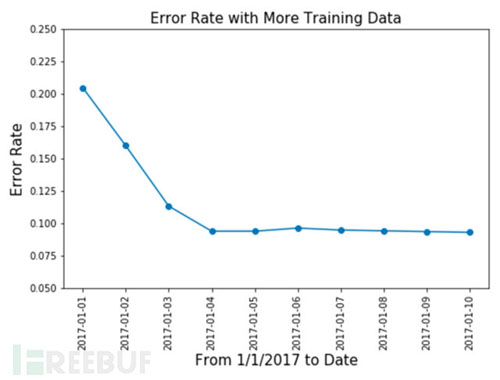
达到我们所预期的效果,当训练数据越来越多的时候,测试数据当中的误报率从20%多降低到了10%。通过对告警数据和标签的不断自学习,可以剔除很多告警误报。前面提到,数据当中引入了9%的噪音,所以误报率不会再持续的降低。
在我们的机器学习模型当中,我们利用了4个主要的特征值:
srcIP,访问源IP
timeofday,告警产生的时间
visits,访问次数
destIP,被访问IP
下图显示了特征值在模型中的重要性:

和我们的预期也是一致的,访问源IP(srcIP)和告警发生的时间(timeofday)是区分出误报告警效果最好的特征值。
另外,由于随机森林模型以及大部分机器学习模型都不支持分类变量(categoricalvariable)的学习,所以我们把srcIP和destIP这两个特征值做了二值化处理。简要代码如下:

总结
本文通过一组模拟实验数据和随机森林算法,从理论上验证了“标签传递经验方法”的有效性。即通过安全分析专家对告警日志进行有效或误报的标记,把专家的知识技能转化成机器学习模型的分析能力。和其他方法相比,此方法在完成自动化学习之后就不再需要人工干预,而且会随着数据的积累对误报的剔除会更加精确。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330