将SPSS分析技术应用于大数据
了解 SPSS? 中处理大数据的新功能。现在可以对 SPSS
分析资产轻松地进行修改,以便连接到不同的大数据来源,它们还可以在不同的部署模式(批处理或实时模式)下运行。SPSS 平台的组件现在可与 IBM
Netezza、InfoSphere? BigInsights? 和 InfoSphere Streams
结合使用,以支持分析师对大数据使用强大的分析工具。
数十年来,IBM SPSS 为统计人员和数据科学家提供了强大的工具。多年来,SPSS
平台已发生了演变,支持数据挖掘流程的所有阶段,包括模型开发、模型部署和模型刷新。在过去两年,SPSS 中增加了处理大数据的新功能。本文将介绍
SPSS 如何与 IBM 大数据产品组合的 3 个组件相集成:Netezza、InfoSphere BigInsights 和
InfoSphere Streams。
SPSS 平台概述
与大数据集成的 SPSS 软件组件:
1.SPSS Modeler
2.SPSS Analytic Server
3.SPSS Collaboration and Deployment Services
4.SPSS Analytic Catalyst
SPSS Modeler 是一个数据挖掘工作台,用于分析数据和部署分析资产。通用术语分析资产
用于描述解决某个业务问题的一个操作集合。数据科学家在描述使用数据挖掘工具开发的资产时,通常会使用术语模型 或预测模型。除了模型之外,SPSS
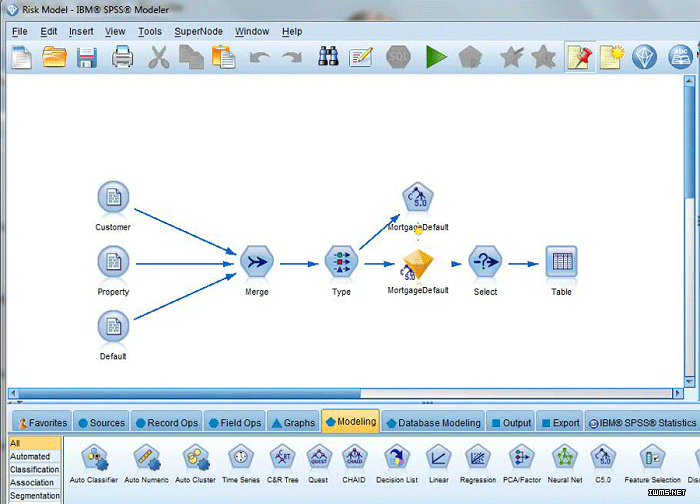
分析资产还可包含数据准备步骤和业务规则。图 1 显示了 SPSS Modeler
中开发的一个示例分析资产。在此示例中,我们使用一个决策树模型来执行贷款违约预测。分析资产执行以下操作:
1.合并来自 3 个历史数据源的数据
2.使用一个 Type 节点识别用于模型预测的目标变量 (MortgageDefault)
3.构建一个基于 C5.0 决策树算法的模型
4.选择具有积极的贷款违约预测的记录
5.将结果显示在一个表中
图 1. SPSS Modeler 中开发的分析资产
该图显示了决策树模型图
SPSS Modeler
是一个可视编程环境。分析资产可通过连接画布上的可视编程节点来创建;在运行时,节点按照连接箭头的方向执行。节点可按照相关功能进行组织:Sources、Record
Operations、Field Operations、Modeling 等。Modeling 选项卡显示用于生成模型的算法(参见图
2)。SPSS 发布了 27 个建模算法和整套的节点,对一个数据集运行多种算法并选择最佳的节点。除了所描述的可视节点之外,如果分析师希望扩展
SPSS Modeler 的基本功能,那么他们可以使用 SQL 函数、R 模型和自定义开发的节点。
图 2. 包含生成模型的算法的 Modeling 选项卡
Modeling 选项卡显示了每种算法的符号
分析师使用历史数据来构建模型。创建模型后,分析师会修改分析资产,以便对操作数据进行评分(参见图 3)。我们不再需要 Mortgage
Default 数据源,因为它包含历史数据。我们删除了 Type 和 Decision Tree 算法节点。C5
决策树算法节点用于构建模型。创建的模型用金块图标表示 (MortgageDefault)。分析师将 Table 节点替换为一个 Export
节点,这会将数据写入一个数据库表中。现在可以将这个分析资产用于对新贷款申请进行批量或实时评分。
图 3. 包含 Type、Decision Tree 并删除了 Mortgage Default 数据源的已修改模型
更新的图表仅显示剩下的算法
用于大数据的第二个 SPSS 组件是 SPSS Analytic Server。它管理对 Hadoop 数据源的访问,并设计一个
Modeler 流在 Hadoop 中的运行。Modeler 操作以 MapReduce 作业的形式在 Hadoop
中运行,得到一个提供了高性能和高可伸缩性的解决方案。
用于大数据的下一个 SPSS 组件是 SPSS Collaboration and Deployment Services (C&DS)。C&DS 执行两种主要功能:
用作分析资产的存储库。在将某项资产存储在存储库中后,就可以使用它来设计批处理作业。该存储库还提供了与 InfoSphere Streams 的连接,以便实时更新 SPSS 模型。
提供一个接口来计划批处理作业,建模使用数据库和 Hadoop 数据源的刷新作业。
SPSS Analytic Catalyst 通过一种易于使用的 Web
接口来执行统计分析。它是为可能没有深入理解数据挖掘的业务用户设计的。SPSS Analytic Catalyst
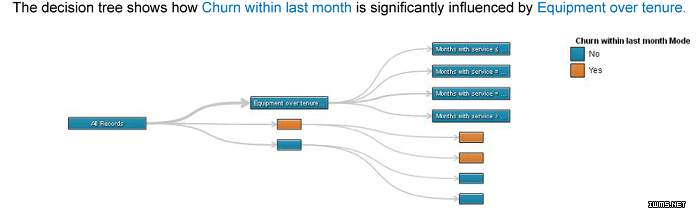
向选定的数据源应用多种算法和统计分析技术。结果可以通过可视元素和纯语言解释来呈现。图 4 显示了一个 SPSS Analytic
Catalyst 项目的示例输出。
图 4. SPSS Analytic Catalyst 返回对某个数据源的分析的结果
决策树显示了一个基于设备年龄的结构
SPSS Analytic Catalyst 分析在 Hadoop 中运行。与 Hadoop 中现有数据的数据源连接由 SPSS
Analytic Server 提供。SPSS 与 InfoSphere BigInsights 的集成 一节中描述的所有数据源都可以用在
SPSS Analytic Catalyst 中。较小的数据集可通过 Web 界面加载到 SPSS Analytic Catalyst 中。一个
Hadoop 发行版是安装 SPSS Analytic Catalyst 的一个必要软件。安装之后,无需额外的集成即可对大数据执行分析。
接下来,让我们深入讲讲 SPSS 与 Netezza、InfoSphere BigInsights 和 InfoSphere Streams 的集成。
SPSS 与 Netezza 的集成
Netezza 是一个高性能数据仓库。SPSS 和 Netezza 的集成是 SPSS 的一种典型的大数据集成场景。存储在 Netezza 中的数据可用于模型构建、评分和模型刷新。
SPSS Modeler 通过 Netezza 所提供的一个开放数据库连接 (ODBC) 驱动程序连接到 Netezza。Netezza
中存储的数据可用作一个 SPSS Modeler 流的输入或输出数据源。SPSS Modeler 支持对 Netezza 执行 SQL
推回:在运行时,Modeler 流被转换为 SQL 并在 Netezza 中执行。SQL 推回操作不需要手动将 SPSS 代码导入
Netezza 中。导入由 SPSS 平台自动处理。
除了 SQL 推回操作之外,SPSS 为 Netezza 提供了一个评分适配器,它允许使用无法转换为 SQL 的 SPSS 节点作为 Netezza 中的用户定义的函数 (UDF)。
SPSS Modeler 还支持在 Netezza 数据库中进行挖掘。对于 SQL 推回操作和评分适配器,SPSS Modeler
将会生成代码并在 Netezza 中运行它。数据库中挖掘节点由 Netezza 提供并由 SPSS
调用。所有描述的实现的最终结果都是让性能得到了提升,因为数据无需在 Netezza 和 SPSS 服务器之间移动。
用于 Netezza 数据库中挖掘的建模节点如图 5 中所示。一些模型可同时用于 SPSS 和 Netezza 中,而其他模型是
Netezza 所独有的。Netezza 中的数据库中挖掘节点通过安装 INZA 包来启用,该包包含在 Netezza 中。默认情况下,在
SPSS Modeler 中会提供 Netezza 数据库中数据挖掘的用户界面:这些节点可通过选择 Tools > Options
> Helper Applications 显示在模型面板中。
图 5. 用于 Netezza 数据库中数据挖掘的建模节点
该图显示了包含建模节点的图标的数据库建模选项卡
SPSS 与 InfoSphere BigInsights 的集成
InfoSphere BigInsights 是一个企业级的 Hadoop 发行版。类似于 Netezza,与 InfoSphere
BigInsights 的集成可用在数据挖掘流程的所有阶段。SPSS 与 InfoSphere BigInsights 的集成由 SPSS
Analytic Server 启用。SPSS Analytic Server 隐藏了访问 Hadoop 数据源的复杂性,支持分析师对
Hadoop 中存储的数据应用了 SPSS Modeler 中提供的所有数据挖掘操作。在 SPSS Analytic Server
中配置后,可通过 Modeler 中的一个来源节点对 Hadoop 数据源进行轻松的访问(参见 图 6)。SPSS Analytic
Server 支持 HDFS 和 HCatalog 数据源。HCatalog 被用作 NoSQL 数据源的一个网关,这些数据源包括
Hive、HBase、Accumulo、JSON 和 XML。
InfoSphere BigInsights Quick Start Edition
InfoSphere BigInsights Quick Start Edition 是 IBM 基于 Hadoop 的
InfoSphere BigInsights 产品的一个可下载的免费版本。使用 Quick Start Edition,您可尝试 IBM
构建的功能来提高开源 Hadoop 的价值,比如 Big SQL、文本分析和
BigSheets。引导式学习可让您的学习体验非常顺利,包括循序渐进、自订进度的教程和视频,可帮助您让 Hadoop
为您工作。没有时间和数据限制,您可以在自己的时间里试验大量数据。观看视频,学习教程 (PDF) 和 立即下载 BigInsights Quick
Start Edition。
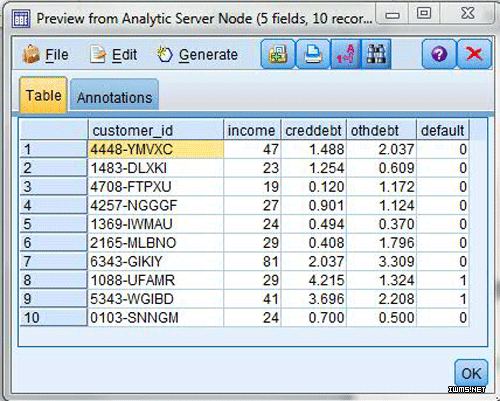
图 6. 在 SPSS Modeler 来源节点中访问 Hadoop 数据源
预览模式中的 Table 选项卡显示了客户 ID
SPSS 为多个 SPSS Modeler 节点提供了 Hadoop 中 执行功能,这些是支持以 MapReduce 作业形式在 Hadoop 内执行操作的节点。以下 SPSS Modeler 节点支持 Hadoop 内的执行操作:
1.大多数数据准备操作
2.模型评分:
C&RT、Quest、CHAID、Linear、Regression、Neural
Net、C5.0、Logistic、Genlin、GLMM、Cox、SVM、Bayes Net、TwoStep、KNN、Decision
List、Discriminant、Self Learning、Anomaly
Detection、Apriori、Carma、K-Means、Kohonen 和 Text Mining
3.模型构建:Linear、Neural Net、C&RT、Chaid 和 Quest
SPSS Analytic Server 支持在 Hadoop 中运行 R 模型。一个流可同时包含 SPSS 和 R 模型。
SPSS Analytic Server 还提供了与数据库数据源的连接。此特性支持您将数据库和 Hadoop 数据合并到单个 SPSS
Modeler 流中。在运行时,SPSS Analytic Server 与 SPSS Modeler 服务器联合,确定 SPSS
Modeler 流的最佳运行环境(SQL 推回操作或 Hadoop 内的执行操作)。
SPSS Analytic Server 支持 InfoSphere BigInsights 2.0 和 2.1、IBM
PureData? for Hadoop 设备、InfoSphere BigInsights with Platform
Symphony,以及其他多个 Hadoop 发行版。
SPSS 与 InfoSphere Streams 的集成
InfoSphere Streams 是一个处理流数据的 IBM 平台。在实时处理需要高级分析时会使用 SPSS 集成。实时应用预测分析的用例的示例包括网络安全、银行和信用卡欺诈检测、预测性维护,以及实时营销产品。
InfoSphere Streams Quick Start Edition
InfoSphere Streams Quick Start Edition 是 InfoSphere Streams
的一个免费、可下载的非生产版本,后者是 IBM
的高性能计算平台,用户开发的应用程序在接收来自数千个实时来源的信息时可以快速地执行获取、分析和关联。没有数据或时间限制,InfoSphere
Streams Quick Start Edition
支持您在自己的独特环境中试验流计算。构建一个强大的分析平台,它能够处理难以置信的高数据吞吐量,高达每秒数百万个事件或消息。立即下载
InfoSphere Streams Quick Start Edition。
InfoSphere Streams 和 SPSS 集成在数据挖掘生命周期的部署阶段中。模型使用存储在数据库或 Hadoop
中的历史数据来开发,部署在 InfoSphere Streams 中以进行实时评分。InfoSphere Streams 和 SPSS 的集成由
SPSS Scoring Toolkit 启用,安装在 InfoSphere Streams 中。Scoring Toolkit 是 SPSS
Collaboration and Deployment Services (C&DS) 的一个组件。
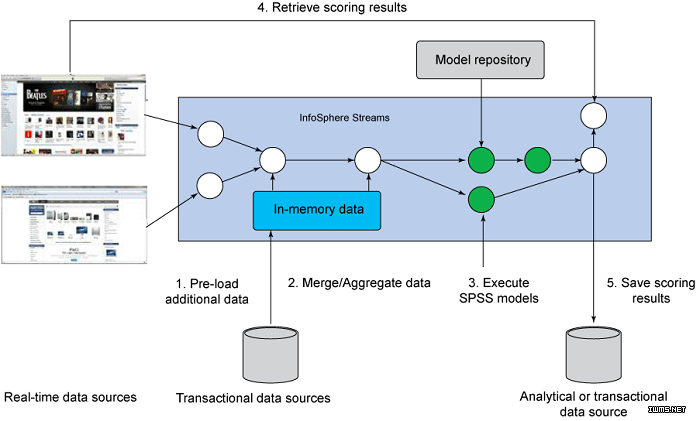
在安装该工具包后,InfoSphere Streams 开发人员可使用操作符 将 SPSS 分析资产与 InfoSphere
Streams 应用程序相集成。publish 操作符在应用程序开发阶段用来获取适合 InfoSphere Streams 部署的 SPSS
模型。scoring 操作符在运行时用于调用 SPSS 模型。repository 操作符可用于自动从 SPSS
模型存储库拉取模型的最新版本。图 7 显示了 SPSS 与 InfoSphere Streams 运行时的集成的图表。
图 7. SPSS 与 InfoSphere Streams 的运行时集成图
该图显示了数据源、存储库、SPSS 模型的工作流
结束语
SPSS 平台与 Netezza、InfoSphere BigInsights 和 InfoSphere Streams
的内置集成能够让分析师使用强大的分析工具处理大数据。SPSS
组件(提供了全面的分析功能)和大数据平台(支持可伸缩性和性能)的组合,为大数据开发人员提供了访问 SPSS 技术的能力。可以轻松地对 SPSS
分析资产进行修改,以便连接到不同的大数据来源,这些分析资产可以在不同的部署模式(批处理或实时模式)下运行。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;














 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330