利用Python和OpenCV库将URL转换为OpenCV格式的方法
过去几个月,有些PyImageSearch读者电邮问我:“如何获取URL指向的图片并将其转换成OpenCV格式(不用将其写入磁盘再读回)”。这篇文章我将展示一下怎么实现这个功能。
额外的,我们也会看到如何利用scikit-image从URL下载一幅图像。当然前行之路也会有一个常见的错误,它可能让你跌个跟头。
继续往下阅读,学习如何利用利用Python和OpenCV将URL转换为图像
方法1:OpenCV、NumPy、urllib
第一个方法:我们使用OpenCV、NumPy、urllib库从URL获取图像,并将其转换为图像。打开并新建一个文件,取名url_to_image.py,我们开始吧:
# import the necessary packages
import numpy as np
import urllib
import cv2
# METHOD #1: OpenCV, NumPy, and urllib
def url_to_image(url):
# download the image, convert it to a NumPy array, and then read
# it into OpenCV format
resp = urllib.urlopen(url)
image = np.asarray(bytearray(resp.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
# return the image
return image
首先要做的就是导入我们必需的包。我们将使用NumPy转换下载的字节序为NumPy数组,使用urllib来执行实际的网络请求,使用cv2来绑定OpenCV接口。
在第7行,我们定义了我们的url_to_image函数。这个函数带一个url参数,也就是我们想要下载的图像地址。
接下来,在第10行,我们使用urllib库来打开这个图像链接。11行则将这个下载下来的字节序转换为NumPy数组。
至此,NumPy数组还是一个1维数组(也就是一个长长的像素链表)。为了将其转换为2维格式,假设每个像素3个通道(意即分别为红,绿,蓝通道),在12行我们使用cv.imdecode函数。最后,在15行我们返回解码出来的图像给调用函数。
一切就绪,该到让它工作的时候了:
# initialize the list of image URLs to download
urls = [
"http://www.pyimagesearch.com/wp-content/uploads/2015/01/opencv_logo.png",
"http://www.pyimagesearch.com/wp-content/uploads/2015/01/google_logo.png",
"http://www.pyimagesearch.com/wp-content/uploads/2014/12/adrian_face_detection_sidebar.png",
]
# loop over the image URLs
for url in urls:
# download the image URL and display it
print "downloading %s" % (url)
image = url_to_image(url)
cv2.imshow("Image", image)
cv2.waitKey(0)
3-5行定义了我们将要下载和转换为OpenCV格式的图像地址列表。
第9行我们遍历这个列表,13行则调用url_to_image函数,然后在14行和15行将获取的图像显示到屏幕上。到此呢,我们就可以像正常情况下一样,使用OpenCV来操作和处理这些图像了。
眼见为实,打开终端,执行如下指令:
代码如下:
$ python url_to_image.py
如果一切顺利的话,你会看到OpenCV的logo:

图1:从URL下载OpenCV logo并转换为OpenCV格式
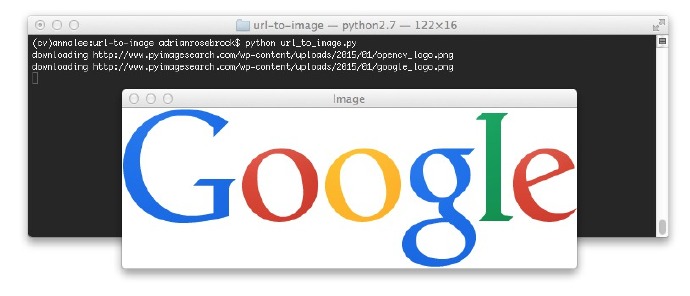
接下来是Google的logo:
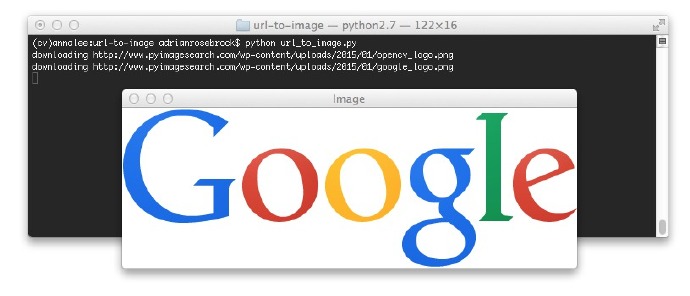
图2:从URL下载Gooogle并转换为OpenCV格式
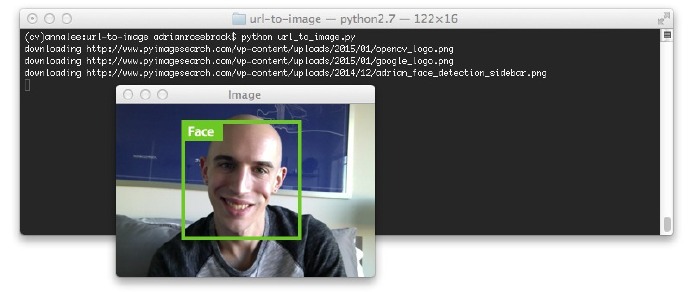
这里也有在我书中验证人脸检测的例子,《Practical Python and OpenCV》:
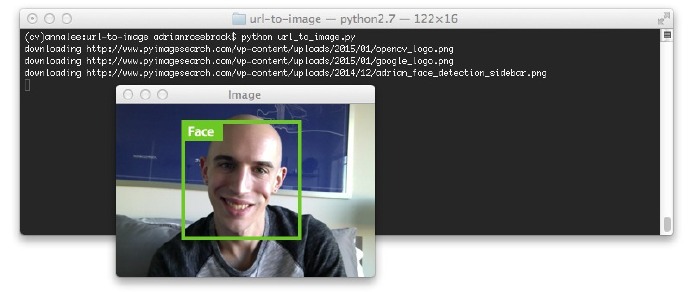
图3:转换一个URL图像为OpenCV格式
现在,我们来看另一种获取图像并转换为OpenCV格式的方法。
方法2:使用scikit-image
第二种方法假定你已经在你计算机上安装好了scikit-image库。让我们看看怎样采用scikit-image从URL获取图像并将其转换为OpenCV格式:
# METHOD #2: scikit-image
from skimage import io
# loop over the image URLs
for url in urls:
# download the image using scikit-image
print "downloading %s" % (url)
image = io.imread(url)
cv2.imshow("Incorrect", image)
cv2.imshow("Correct", cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
cv2.waitKey(0)
scikit-image库中做得很漂亮的一点是:io子库中的imread函数能够区分图像路径到底在磁盘上还是一个URL(第9行)。
尽管这样,这里有一个很严重的错误可能让你跌一个跟头!
OpenCV以BGR顺序表达一幅图像,然而scikit-image则是RGB顺序。如果你使用scikit-iamge的imread函数,而且还想在下载完成后使用OpenCV的函数,那么你要小心了。如41行所述,你需要将图像从RBG转换为BGR。
如果你没有这一步,那么你可能得到错误的结果:

图4:在用scikit-image时,需要特别注意将RGB转换为BGR。左边的图像就是不正确的RGB顺序,右边的则是将RGB转换为BGR,所以能正常显示。
看看Google的logo就更明显了

图5:顺序很重要。确保将RGB转换为BGR,否则就留下了一个很难发现的bug。
到此为止,你明白了吧!这两种方法分别使用Python、OpenCV、urllib,和scikit-image来将URL指向的图片转换为图像。
总结
本文中,我们学会了如何从URL获取图像,且使用Python和OpenCV将其转换为OpenCV格式。
第一种方法使用urllib包获取图像,使用Numpy转换为数组,最后使用OpenCV重新构建数组产生我们的图像。
第二种方式使用scikit-image中的io.imread函数。
所以,哪种更好呢?
这完全取决于你的安装。
如果你已经安装scikit-image,那么我可能就用io.imread(只是不要忘记如果要用OpenCV函数的话,要将RGB转换为BGR)。
如果你没有安装scikit-image,那么url_to_image就是手边现成的工具。具体细节参考本文开始处。
我很快会在Github上将这个函数添加到imutils库中。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;














 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330