单样本t检验的spss实现

直接来看一个例子:
常规种植条件下某玉米品的平均穗重为 300g 。现在采用根外施肥(即将肥料制成液体养分,喷洒到玉米的叶面)后,调查了 20 个玉米棒 ,其穗重如表 1所示。问:改用叶面施肥后,穗重是 否显著增加了 ?(置信度为 95% 或者显著水平 α=0.05)

表1 20个玉米穗的重量(单位:g)
这是一个单尾测验,原假设和备择假设是:

原假设(无效假设):叶面施肥没有增产效果。
备择假设 :叶面施肥有增产效果
在SPSS中不能直接进行单尾测验,但是SPSS却可以输出t统计量的双侧检验相伴概率sig,将得到的相伴概率除以2,即得到单尾测验的相伴概率。将这个相伴概率与0.05进行比较,小于0.05则拒绝原假设。
单样本t检验的SPSS操作
首先将数据导入或者录入到spss中,然后依次 选择分析 <均值比较 <单样本t检验. 出现如下图所示的窗口。

将要检验的变量“穗重”选入到“检验变量”窗口,同时输入给定的用于对比的那个值,此处为常规种植条件下的穗重均值300.设置完毕后,点击确定。输出结果中的描述性统计这里就不讨论了,直接看t检验的结果。

你可以找一本统计学教材,对着t分布表,查看一下自由度为19,显著水平为0.05时,的双侧检验的t临界值,将这里得到的t值与那个临界值进行比较,如果这里的t值大于那个临界值,则拒绝原假设,这和p值小于0.05是等价的。
如下图所示,这里得到的双侧t检验相伴概率为0.006,那么单侧相伴概率为0.003,无论是双侧检验还是单侧检验,都可以拒绝原假设,考虑到叶面施肥后的穗重均值为300+7=307,因此认为叶面施肥能够极显著地增加穗重。
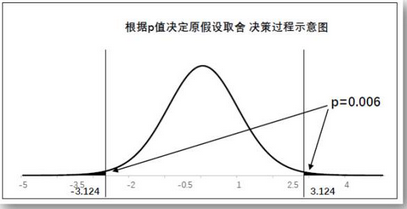
双侧检验与单侧检验
下面两张图片中,第一个图中黑色区域表示的是单侧检验的拒绝域。第二个图表示的双侧检验的拒绝域。同样是0.05的置信水平,双侧检验与单侧检验,临界值是不同的,因为黑色区域的位置不同,尽管它们的总面积是相等的。

进行大端单尾测验时,当计算得到的t统计量大于黑色区域与白色区域的临界位置对应的横轴值时,拒绝原假设。而这时,相伴概率也一定小于0.05,因此使用相伴概率和t临界值来决定原假设的取舍,原理本质上是一样的。只不过教材上进行案例讲解时,一般使用临界值,因为相伴概率计算困难。而统计软件一般直接给出相伴概率。(相伴概率即为p值或者spss输出的sig值。)

进行双侧检验时,计算得到的统计量落入两边任意一块黑色区域,就应该拒绝原假设。或者相伴概率小于0.05时,拒绝原假设。(黑色区域表示的是一个很小的概率,这样小的概率,通过一次试验一般是不会发生,如果发生,说明原假设有问题,说明真实的分布不是原假设成立时的这个分布,均值要改变才行,均值改变了才能符合被检验的数据,所以被检验的数据的均值与原来那个设定值是不同的。)
单侧检验的R语言实现
如果你一定要直接得出单侧检验的结果,那也不是没有办法,R语言可以直接得出单侧检验的结果。给出代码如下:
t_test01.1<-read.csv(file="D:/单样本t检验_玉米.csv",header=TRUE)
#载入数据
t.test(t_test01.1$穗重,
alternative =c("greater"),
mu =300, paired =FALSE,
conf.level =0.95
) #进行单样本t检验
输出结果如下
OneSample t-test
data: t_test01.1$穗重
t=3.1239, df=19, p-value =0.002794
alternative hypothesis: true mean is greater than 300
95 percent confidence interval:
303.1254 Inf
sample estimates:
mean of x
307
得到 p-value =0.002794<0.05,拒绝原假设,选择备择假设:alternative hypothesis: true mean is greater than 300。(实际均值大于300)
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330