简单易学的机器学习算法—非线性支持向量机
一、回顾
介绍了支持向量机的基本概念,线性可分支持向量机的原理以及线性支持向量机的原理,线性可分支持向量机是线性支持向量机的基础。对于线性支持向量机,选择一个合适的惩罚参数,并构造凸二次规划问题:

求得原始问题的对偶问题的最优解,由此可求出原始问题的最优解:

其中 中满足的分量。这样便可以求得分离超平面
中满足的分量。这样便可以求得分离超平面
以及分类决策函数:
线性可分支持向量机算法是线性支持向量机算法的特殊情况。
二、非线性问题的处理方法
在处理非线性问题时,可以通过将分线性问题转化成线性问题,并通过已经构建的线性支持向量机来处理。如下图所示:

(非线性转成线性问题)
通过一种映射可以将输入空间转换到对应的特征空间,体现在特征空间中的是对应的线性问题。核技巧就可以完成这样的映射工作。
1、核函数的定义(摘自《统计机器学习》)
设是输入空间(欧式空间的子集或离散集合),又设为特征空间(希尔伯特空间),如果存在一个从到的映射
使得对所有 ,函数
,函数 满足条件
满足条件
则称 为核函数,为映射函数。
为核函数,为映射函数。
在实际的问题中,通常使用已有的核函数。
2、常用核函数
多项式核函数(Polynomial Kernel Function)
高斯核函数(Gaussian Kernel Function)

三、非线性支持向量机
1、选取适当的核函数和适当的参数,构造原始问题的对偶问题:

求得对应的最优解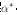 。
。
2、选择 的一个满足的分量,求:
的一个满足的分量,求:
3、构造决策函数
四、实验仿真
对于非线性可分问题,其图像为:

(原始空间中的图像)
MATLAB代码
主程序
[plain] view plain copy 在CODE上查看代码片派生到我的代码片
%% 非线性支持向量机
% 清空内存
clear all;
clc;
% 导入测试数据
A = load('testSetRBF.txt');
%% 区分开训练数据与测试数据
m = size(A);%得到整个数据集的大小
trainA = A(11:m(1,1),:);
testA = A(1:10,:);
% 训练和测试数据集的大小
mTrain = size(trainA);
mTest = size(testA);
% 区分开特征与标签
Xtrain = trainA(:,1:2);
Ytrain = trainA(:,mTrain(1,2))';
Xtest = testA(:,1:2);
Ytest = testA(:,mTest(1,2))';
%% 对偶问题,用二次规划来求解,以求得训练模型
sigma = 0.5;%高斯核中的参数
H = zeros(mTrain(1,1),mTrain(1,1));
for i = 1:mTrain(1,1)
for j = 1:mTrain(1,1)
H(i,j) = GaussianKernalFunction(Xtrain(i,:),Xtrain(j,:),sigma);
H(i,j) = H(i,j)*Ytrain(i)*Ytrain(j);
end
end
f = ones(mTrain(1,1),1)*(-1);
B = Ytrain;
b = 0;
lb = zeros(mTrain(1,1),1);
% 调用二次规划的函数
[x,fval,exitflag,output,lambda] = quadprog(H,f,[],[],B,b,lb);
% 定义C
C = max(x);
% 求解原问题
n = size(x);
k = 1;
for i = 1:n(1,1)
Kernel = zeros(n(1,1),1);
if x(i,1) > 0 && x(i,1)<C
for j = 1:n(1,1)
Kernel(j,:) = GaussianKernalFunction(Xtrain(j,:),Xtrain(i,:),sigma);
Kernel(j,:) = Kernel(j,:)*Ytrain(j);
end
b(k,1) = Ytrain(1,i)-x'*Kernel;
k = k +1;
end
end
b = mean(b);
%% 决策函数来验证训练准确性
trainOutput = zeros(mTrain(1,1),1);
for i = 1:mTrain(1,1)
Kernel_train = zeros(mTrain(1,1),1);
for j = 1:mTrain(1,1)
Kernel_train(j,:) = GaussianKernalFunction(Xtrain(j,:),Xtrain(i,:),sigma);
Kernel_train(j,:) = Kernel_train(j,:)*Ytrain(j);
end
trainOutput(i,1) = x'*Kernel_train+b;
end
for i = 1:mTrain(1,1)
if trainOutput(i,1)>0
trainOutput(i,1)=1;
elseif trainOutput(i,1)<0
trainOutput(i,1)=-1;
end
end
% 统计正确个数
countTrain = 0;
for i = 1:mTrain(1,1)
if trainOutput(i,1) == Ytrain(i)
countTrain = countTrain+1;
end
end
trainCorrect = countTrain./mTrain(1,1);
%% 决策函数来验证测试准确性
testOutput = zeros(mTest(1,1),1);
for i = 1:mTest(1,1)
Kernel_test = zeros(mTrain(1,1),1);
for j = 1:mTrain(1,1)
Kernel_test(j,:) = GaussianKernalFunction(Xtrain(j,:),Xtest(i,:),sigma);
Kernel_test(j,:) = Kernel_test(j,:)*Ytrain(j);
end
testOutput(i,1) = x'*Kernel_train+b;
end
for i = 1:mTest(1,1)
if testOutput(i,1)>0
testOutput(i,1)=1;
elseif testOutput(i,1)<0
testOutput(i,1)=-1;
end
end
% 统计正确个数
countTest = 0;
for i = 1:mTest(1,1)
if testOutput(i,1) == Ytest(i)
countTest = countTest+1;
end
end
testCorrect = countTest./mTest(1,1);
disp(['训练的准确性:',num2str(trainCorrect)]);
disp(['测试的准确性:',num2str(testCorrect)]);
核函数
[plain] view plain copy 在CODE上查看代码片派生到我的代码片
%% 高斯核函数,其中输入x和y都是行向量
function [ output ] = GaussianKernalFunction( x,y,sigma )
output = exp(-(x-y)*(x-y)'./(2*sigma^2));
end
最终的结果为:
注:在这个问题中,有两个参数需要调整,即核参数和惩罚参数,选取合适的参数对模型的训练起着很重要的作用。在程序中,我是指定的参数。这里的程序只是为帮助理解算法的过程。数据分析师培训
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330