R语言实战:R语言介绍
我们分析数据的方式在近年来发生了令人瞩目的变化。随着个人电脑和互联网的出现,可获取的数据量有了非常可观的增长。
商业公司拥有TB级的客户交易数据,政府、学术团体以及私立研究机构同样拥有各类研究课题的大量档案和调查数据。从这些海量数据中收集信息(更不用说发现规律)已经成为了一项产业。同时,如何以容易让人理解和消化的方式呈现这些信息也日益富有挑战性。
数据分析科学(统计学、计量心理学、计量经济学、机器学习)的发展一直与数据的爆炸式增长保持同步。远在个人电脑和互联网发端之前,学术研究人员就已经开发出了很多新的统计方法,并将其研究成果以论文的形式发表在专业期刊上。这些方法可能需要很多年才能够被程序员改写并整合到广泛用于数据分析的统计软件中。而如今,新的方法层出不穷。统计研究者经常在人们常访问的网站上发表新方法和改进的方法,并附上相应的实现代码。
个人电脑的出现还对我们分析数据的方式产生了另外一种影响。当数据分析需要在大型机上完成的时候,机时非常宝贵难求。分析师们会小心地设定可能用到的所有参数和选项,再让计算机执行计算。程序运行完毕后,输出的结果可能长达几十甚至几百页。之后,分析师会仔细筛查整个输出,去芜存菁。许多受欢迎的统计软件正是在这个时期开发出来的。直到现在,统计软件依然在一定程度上沿袭了这种处理方式。
随着个人电脑将计算变得廉价且便捷,现代数据分析的方式发生了变化。与过去一次性设置好完整的数据分析过程不同,现在这个过程已经变得高度交互化,每一阶段的输出都可以充当下一阶段的输入。一个典型的数据分析过程的示例见图1-1。在任何时刻,这个循环都可能在进行着数据变换、缺失值插补、变量增加或删除,甚至重新执行整个过程。当分析师认为他已经深入地理解了数据,并且可以回答所有能够回答的相关问题时,这个过程即告结束。
个人电脑的出现(特别是高分辨率显示器的普及)同样对理解和呈现分析结果产生了重大影响。一图胜千言,绝对如此!人类非常擅长通过视觉获取有用信息。现代数据分析也日益依赖通过呈现图形来揭示含义和表达结果。

总而言之,今天的数据分析人士需要从广泛的数据源(数据库管理系统、文本文件、统计软件以及电子表格)获取数据、将数据片段融合到一起、对数据做清理和标注、用最新的方法进行分析、以有意义有吸引力的图形化方式展示结果,最后将结果整合成令人感兴趣的报告并向利益相关者和公众发布。通过下面的介绍你会看到, R正是一个适合完成以上目标的理想而又功能全面的软件。
1.1 为何要使用 R语言?
与起源于贝尔实验室的S语言类似, R语言也是一种为统计计算和绘图而生的语言和环境,它是一套开源的数据分析解决方案,由一个庞大且活跃的全球性研究型社区维护。但是,市面上也有许多其他流行的统计和制图软件,如Microsoft Excel、 SAS、 IBM SPSS、 Stata以及Minitab。为何偏偏要选择R?
R有着非常多值得推荐的特性。
多数商业统计软件价格不菲,投入成千上万美元都是可能的。而R是免费的!如果你是一位教师或一名学生,好处显而易见。
R语言是一个全面的统计研究平台,提供了各式各样的数据分析技术。几乎任何类型的数据分析工作皆可在R中完成。
R语言拥有顶尖水准的制图功能。如果希望复杂数据可视化,那么R拥有最全面且最强大的一系列可用功能。
R语言是一个可进行交互式数据分析和探索的强大平台。其核心设计理念就是支持图1-1中所概述的分析方法。举例来说,任意一个分析步骤的结果均可被轻松保存、操作,并作为进一步分析的输入。
从多个数据源获取并将数据转化为可用的形式,可能是一个富有挑战性的议题。 R可以轻松地从各种类型的数据源导入数据,包括文本文件、数据库管理系统、统计软件,乃至专门的数据仓库。它同样可以将数据输出并写入到这些系统中。
R是一个无与伦比的平台,在其上可使用一种简单而直接的方式编写新的统计方法。它易于扩展,并为快速编程实现新方法提供了一套十分自然的语言。
R囊括了在其他软件中尚不可用的、先进的统计计算例程。事实上,新方法的更新速度是以周来计算的。如果你是一位SAS用户,想象一下每隔几天就获得一个新SAS过程的情景。
如果你不想学习一门新的语言,有各式各样的GUI(Graphical User Interface,图形用户界面)工具通过菜单和对话框提供了与R语言同等的功能。
R可运行于多种平台之上,包括Windows、 UNIX和Mac OS X。这基本上意味着它可以运行于你所能拥有的任何计算机上。(本人曾在偶然间看到过在iPhone上安装R的教程,让人佩服,但这也许不是一个好主意。)
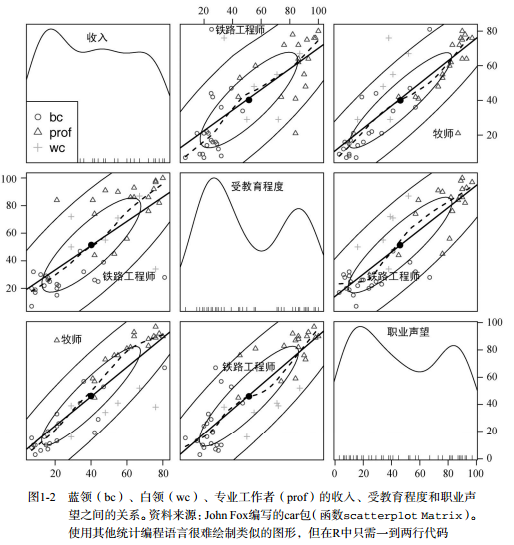
图1-2是展示R语言制图功能的一个示例。使用一行代码做出的这张图,说明了蓝领工作、白领工作和专业工作在收入、受教育程度以及职业声望方面的关系。从专业角度讲,这是一幅使用不同的颜色和符号表示不同分组的散点图矩阵,带有两类拟合曲线(线性回归和局部加权回归) 、置信椭圆以及两种对密度的展示(核密度估计和轴须图)。另外,在每个散点图中都自动标出了值最大的离群点。如果这些术语对你来说很陌生也不必担心。我们将在后续各章中陆续谈及它们。这里请暂且相信我,它们真的非常酷。(搞统计的人读到这里时估计已经垂涎三尺了。)图1-2主要表明了以下几点。
受教育程度(education)、收入(income)、职业声望(prestige)呈线性相关。
就总体而言,蓝领工作者有着更低的受教育程度、收入和职业声望;反之,专业工作者有着更高的受教育程度、收入和职业声望。白领工作者介于两者之间。
有趣的例外是,铁路工程师(RR.engineer)的受教育程度较低,但收入较高,而牧师(minister)的职业声望高,收入却较低。
受教育程度和职业声望(较轻微地)呈现双峰分布,高值和低值数据多于中间的数据。
重要的是, R能够让你以一种简单而直接的方式创建优雅、信息丰富、高度定制化的图形。而使用其他统计语言创建类似的图形不仅费时费力,而且可能根本无法做到。
可惜的是, R语言的学习曲线较为陡峭。因为它的功能非常丰富,所以文档和帮助文件也相当多。另外,由于许多功能都是由独立贡献者编写的可选模块提供的,这些文档可能比较零散而且很难找到。事实上,要掌握R的所有功能,可以说是一项挑战。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330