聚类分析实战解析与总结
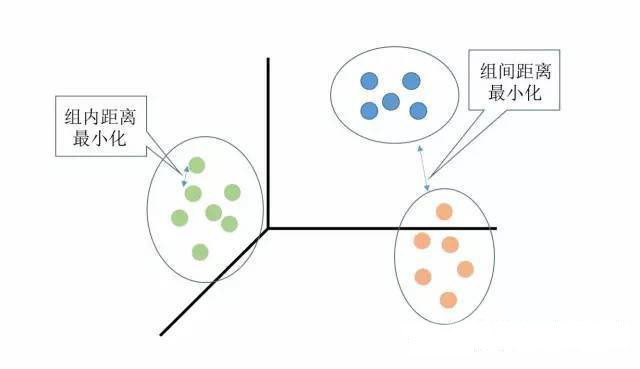
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化而组间距离最大化,如下图所示:
常见的聚类分析算法如下:
K-Means: K-均值聚类也称为快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量数据。
K-中心点:K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
系统聚类:也称为层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
下面我们详细介绍K-Means聚类算法。
K-Means聚类算法
K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
算法实现
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新算每个簇的质心
until 簇不发生变化或达到最大迭代次数
K如何确定
与层次聚类结合,经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果粗的数目,并找到一个初始聚类,然后用迭代重定位来改进该聚类。
初始质心的选取
常见的方法是随机的选取初始质心,但是这样簇的质量常常很差。
(1)多次运行,每次使用一组不同的随机初始质心,然后选取具有最小SSE(误差的平方和)的簇集。这种策略简单,但是效果可能不好,这取决于数据集和寻找的簇的个数。
(2)取一个样本,并使用层次聚类技术对它聚类。从层次聚类中提取K个簇,并用这些簇的质心作为初始质心。该方法通常很有效,但仅对下列情况有效:样本相对较小;K相对于样本大小较小。
(3)取所有点的质心作为第一个点。然后,对于每个后继初始质心,选择离已经选取过的初始质心最远的点。使用这种方法,确保了选择的初始质心不仅是随机的,而且是散开的。但是,这种方法可能选中离群点。
距离的度量
常用的距离度量方法包括:欧几里得距离和余弦相似度。欧几里得距离度量会受指标不同单位刻度的影响,所以一般需要先进行标准化,同时距离越大,个体间差异越大;空间向量余弦夹角的相似度度量不会受指标刻度的影响,余弦值落于区间[-1,1],值越大,差异越小。
质心的计算
对于距离度量不管是采用欧式距离还是采用余弦相似度,簇的质心都是其均值。
算法停止条件
一般是目标函数达到最优或者达到最大的迭代次数即可终止。对于不同的距离度量,目标函数往往不同。当采用欧式距离时,目标函数一般为最小化对象到其簇质心的距离的平方和;当采用余弦相似度时,目标函数一般为最大化对象到其簇质心的余弦相似度和。
空聚类的处理
如果所有的点在指派步骤都未分配到某个簇,就会得到空簇。如果这种情况发生,则需要某种策略来选择一个替补质心,否则的话,平方误差将会偏大。
(1)选择一个距离当前任何质心最远的点。这将消除当前对总平方误差影响最大的点。
(2)从具有最大SSE的簇中选择一个替补的质心,这将分裂簇并降低聚类的总SSE。如果有多个空簇,则该过程重复多次。
适用范围及缺陷
K-Menas算法试图找到使平方误差准则函数最小的簇。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。对于处理大数据集合,该算法非常高效,且伸缩性较好。
但该算法除了要事先确定簇数K和对初始聚类中心敏感外,经常以局部最优结束,同时对“噪声”和孤立点敏感,并且该方法不适于发现非凸面形状的簇或大小差别很大的簇。
克服缺点的方法:使用尽量多的数据;使用中位数代替均值来克服outlier的问题。
实例解析
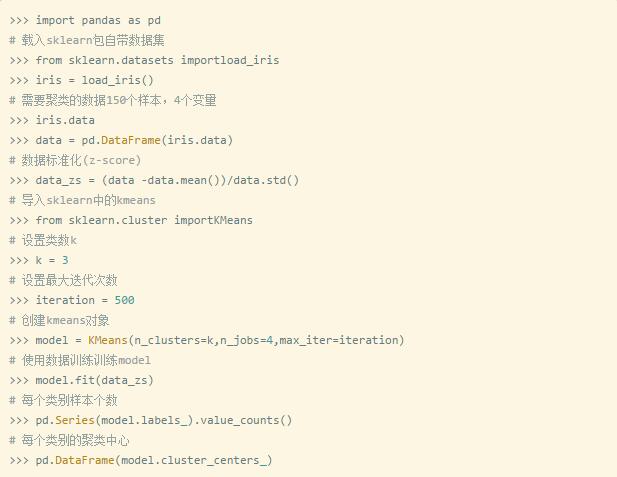
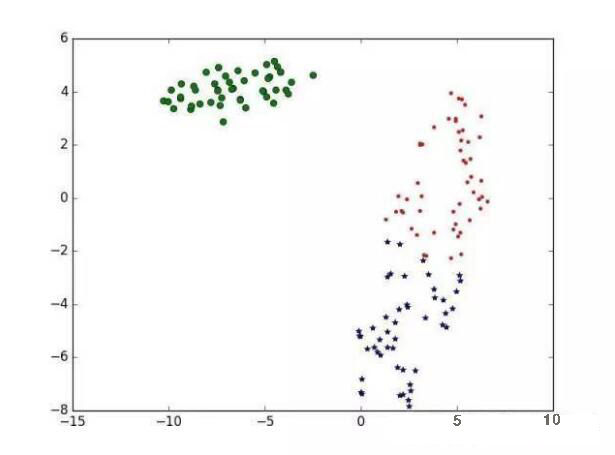
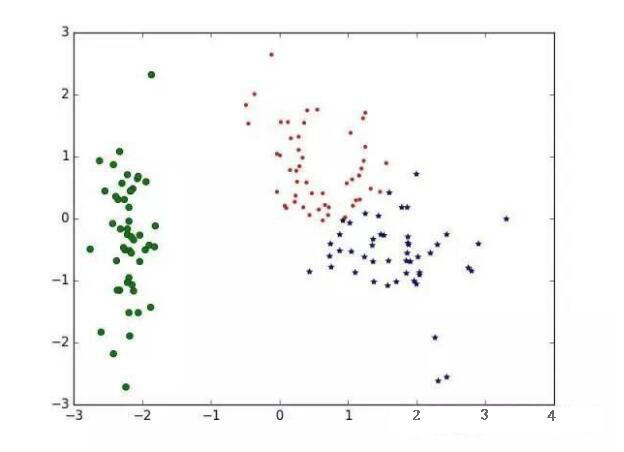
下面我们用TSNE(高维数据可视化工具)对聚类结果进行可视化

聚类效果图如下:
下面我们用PCA降维后,对聚类结果进行可视化
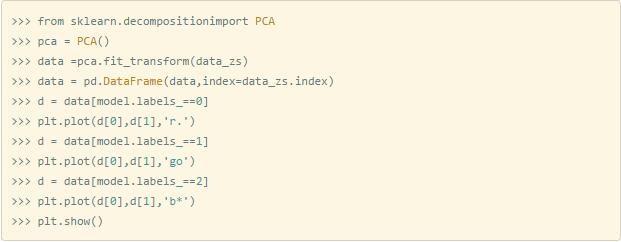
聚类效果图如下:
Python主要的聚类分析算法总结
在scikit-learn中实现的聚类算法主要包括K-Means、层次聚类、FCM、神经网络聚类,其主要相关函数如下:
KMeans: K均值聚类;
AffinityPropagation: 吸引力传播聚类,2007年提出,几乎优于所有其他方法,不需要指定聚类数K,但运行效率较低;
MeanShift:均值漂移聚类算法;
SpectralClustering:谱聚类,具有效果比KMeans好,速度比KMeans快等特点;
AgglomerativeClustering:层次聚类,给出一棵聚类层次树;
DBSCAN:具有噪音的基于密度的聚类方法;
BIRCH:综合的层次聚类算法,可以处理大规模数据的聚类。
这些方法的使用大同小异,基本都是先用对应的函数建立模型,然后用fit()方法来训练模型,训练好之后,就可以用labels_属性得到样本数据的标签,或者用predict()方法预测新样本的标签。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330