数据挖掘系列BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了。神经网络有很多种:前向传输网络、反向传输网络、递归神经网络、卷积神经网络等。本文介绍基本的反向传输神经网络(Backpropagation 简称BP),主要讲述算法的基本流程和自己在训练BP神经网络的一些经验。
BP神经网络的结构
神经网络就是模拟人的大脑的神经单元的工作方式,但进行了很大的简化,神经网络由很多神经网络层构成,而每一层又由许多单元组成,第一层叫输入层,最后一层叫输出层,中间的各层叫隐藏层,在BP神经网络中,只有相邻的神经层的各个单元之间有联系,除了输出层外,每一层都有一个偏置结点:
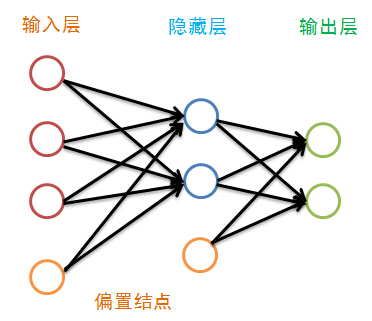
虽然图中隐藏层只画了一层,但其层数并没有限制,传统的神经网络学习经验认为一层就足够好,而最近的深度学习不这么认为。偏置结点是为了描述训练数据中没有的特征,偏置结点对于下一层的每一个结点的权重的不同而生产不同的偏置,于是可以认为偏置是每一个结点(除输入层外)的属性。我们偏置结点在图中省略掉:
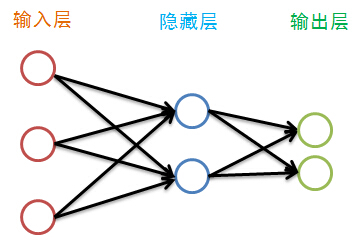
在描述BP神经网络的训练之前,我们先来看看神经网络各层都有哪些属性:
-
每一个神经单元都有一定量的能量,我们定义其能量值为该结点j的输出值Oj;
-
相邻层之间结点的连接有一个权重Wij,其值在[-1,1]之间;
-
除输入层外,每一层的各个结点都有一个输入值,其值为上一层所有结点按权重传递过来的能量之和加上偏置;
-
除输入层外,每一层都有一个偏置值,其值在[0,1]之间;
-
除输入层外,每个结点的输出值等该结点的输入值作非线性变换;
-
我们认为输入层没有输入值,其输出值即为训练数据的属性,比如一条记录X=<(1,2,3),类别1>,那么输入层的三个结点的输出值分别为1,2,3. 因此输入层的结点个数一般等于训练数据的属性个数。
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
-
前向传输,逐层波浪式的传递输出值;
-
逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[-1,1]的一个随机实数,每一个偏置取[0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
首先设置输入层的输出值,假设属性的个数为100,那我们就设置输入层的神经单元个数为100,输入层的结点Ni为记录第i维上的属性值xi。对输入层的操作就这么简单,之后的每层就要复杂一些了,除输入层外,其他各层的输入值是上一层输入值按权重累加的结果值加上偏置,每个结点的输出值等该结点的输入值作变换

前向传输的输出层的计算过程公式如下:
Ij=∑iWijOi+θj
Oj=11+e−Il
对隐藏层和输出层的每一个结点都按照如上图的方式计算输出值,就完成前向传播的过程,紧接着是进行逆向反馈。
逆向反馈(Backpropagation)
逆向反馈从最后一层即输出层开始,我们训练神经网络作分类的目的往往是希望最后一层的输出能够描述数据记录的类别,比如对于一个二分类的问题,我们常常用两个神经单元作为输出层,如果输出层的第一个神经单元的输出值比第二个神经单元大,我们认为这个数据记录属于第一类,否则属于第二类。
还记得我们第一次前向反馈时,整个网络的权重和偏置都是我们随机取,因此网络的输出肯定还不能描述记录的类别,因此需要调整网络的参数,即权重值和偏置值,而调整的依据就是网络的输出层的输出值与类别之间的差异,通过调整参数来缩小这个差异,这就是神经网络的优化目标。对于输出层:
Ej=Oj(1−Oj)(Tj−Oj)
其中Ej表示第j个结点的误差值,Oj表示第j个结点的输出值,Tj记录输出值,比如对于2分类问题,我们用01表示类标1,10表示类别2,如果一个记录属于类别1,那么其T1=0,T2=1。
中间的隐藏层并不直接与数据记录的类别打交道,而是通过下一层的所有结点误差按权重累加,计算公式如下:
Ej=Oj(1−Oj)∑kEkWjk
其中Wjk表示当前层的结点j到下一层的结点k的权重值,Ek下一层的结点k的误差率。
计算完误差率后,就可以利用误差率对权重和偏置进行更新,首先看权重的更新:
ΔWij=λEjOi
Wij=Wij+ΔWij
其中λ表示表示学习速率,取值为0到1,学习速率设置得大,训练收敛更快,但容易陷入局部最优解,学习速率设置得比较小的话,收敛速度较慢,但能一步步逼近全局最优解。
更新完权重后,还有最后一项参数需要更新,即偏置:
Δθj=λEj
θj=θj+Δθj
至此,我们完成了一次神经网络的训练过程,通过不断的使用所有数据记录进行训练,从而得到一个分类模型。不断地迭代,不可能无休止的下去,总归有个终止条件
训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
-
设置最大迭代次数,比如使用数据集迭代100次后停止训练
-
计算训练集在网络上的预测准确率,达到一定门限值后停止训练
使用BP神经网络分类
我自己写了一个BP神经网络,在数字手写体识别数据集MINIST上测试了一下,MINIST数据集中训练图片有12000个,测试图片20000个,每张图片是28*28的灰度图像,我对图像进行了二值化处理,神经网络的参数设置如下:
-
输入层设置28*28=784个输入单元;
-
输出层设置10个,对应10个数字的类别;
-
学习速率设置为0.05;
训练经过约50次左右迭代,在训练集上已经能达到99%的正确率,在测试集上的正确率为90.03%,单纯的BP神经网络能够提升的空间不大了,但kaggle上已经有人有卷积神经网络在测试集达到了99.3%的准确率。代码是去年用C++写的,浓浓的JAVA的味道,代码价值不大,但注释比较详细,可以查看这里,最近写了一个Java多线程的BP神经网络,但现在还不方便拿出来,如果项目黄了,再放上来吧。
训练BP神经网络的一些经验
讲一下自己训练神经网络的一点经验:
-
学习速率不宜设置过大,一般小于0.1,开始我设置了0.85,准确率一直提不上去,很明显是陷入了局部最优解;
-
输入数据应该归一化,开始使用0-255的灰度值测试,效果不好,转成01二值后,效果提升显著;
-
尽量是数据记录随机分布,不要将数据集按记录排序,假设数据集有10个类别,我们把数据集按类别排序,一条一条记录地训练神经网络,训练到后面,模型将只记得最近训练的类别而忘记了之前训练的类别;
-
对于多分类问题,比如汉字识别问题,常用汉字就有7000多个,也就是说有7000个类别,如果我们将输出层设置为7000个结点,那计算量将非常大,并且参数过多而不容易收敛,这时候我们应该对类别进行编码,7000个汉字只需要13个二进制位即可表示,因此我们的输出成只需要设置13个结点即可。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330