面向高维度的机器学习的计算框架-Angel
为支持超大维度机器学习模型运算,腾讯数据平台部与香港科技大学合作开发了面向机器学习的分布式计算框架——Angel 1.0。
Angel是使用Java语言开发的专有机器学习计算系统,用户可以像用Spark, MapReduce一样,用它来完成机器学习的模型训练。Angel已经支持了SGD、ADMM优化算法,同时我们也提供了一些常用的机器学习模型;但是如果用户有自定义需求,也可以在我们提供的最优化算法上层比较容易地封装模型。
Angel应用香港科技大学的Chukonu 作为网络解决方案, 在高维度机器学习的参数更新过程中,有针对性地给滞后的计算任务的参数传递提速,整体上缩短机器学习算法的运算时间。这一创新采用了香港科技大学陈凯教授及其研究小组开发的可感知上层应用(Application-aware)的网络优化方案,以及杨强教授领导的的大规模机器学习研究方案。
另外,北京大学崔斌教授及其学生也共同参与了Angel项目的研发。
在实际的生产任务中,Angel在千万级到亿级的特征纬度条件下运行SGD,性能是成熟的开源系统Spark的数倍到数十倍不等。Angel已经在腾讯视频推荐、广点通等精准推荐业务上实际应用,目前我们正在扩大在腾讯内部的应用范围,目标是支持腾讯等企业级大规模机器学习任务。
整体架构
Angel在整体架构上参考了谷歌的DistBelief。DistBeilef最初是为深度学习而设计,它使用了参数服务器,以解决巨大模型在训练时的更新问题。参数服务器同样可用于机器学习中非深度学习的模型,如SGD、ADMM、LBFGS的优化算法在面临在每轮迭代上亿个参数更新的场景中,需要参数分布式缓存来拓展性能。Angel在运算中支持BSP、SSP、ASP三种计算模型,其中SSP是由卡耐基梅隆大学EricXing在Petuum项目中验证的计算模型,能在机器学习的这种特定运算场景下提升缩短收敛时间。系统有五个角色:
Master:负责资源申请和分配,以及任务的管理。
Task:负责任务的执行,以线程的形式存在。
Worker:独立进程运行于Yarn的Container中,是Task的执行容器。
ParameterServer:随着一个任务的启动而生成,任务结束而销毁,负责在该任务训练过程中的参数的更新和存储。
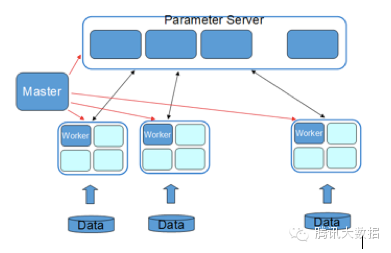
WorkerGroup为一个虚拟概念,由若干个Worker组成,元数据由Master维护。为模型并行拓展而考虑,在一个WorkerGroup内所有Worker运行的训练数据都是一样的。虽然我们提供了一些通用模型,但并不保证都满足需求,而用户自定义的模型实现可以实现我们的通用接口,形式上等同于MapReduce或Spark。
1)用户友好
1. 自动化数据切分: Angel系统为用户提供了自动切分训练数据的功能,方便用户进行数据并行运算:系统默认兼容了Hadoop FS接口,原始训练样本存储在支持Hadoop FS接口的分布式文件系统如HDFS、Tachyon。
2. 丰富的数据管理:样本数据存储在分布式文件系统中,系统在计算前从文件系统读取到计算进程,放在缓存在内存中以加速迭代运算;如果内存中缓存不下的数据则暂存到本地磁盘,不需要向分布式文件系统再次发起通讯请求。
3. 丰富的线性代数及优化算法库: Angel更提供了高效的向量及矩阵运算库(稀疏/稠密),方便了用户自由选择数据、参数的表达形式。在优化算法方面,Angel已实现了SGD、ADMM;模型方面,支持了Latent DirichletAllocation (LDA)、MatrixFactorization (MF)、LogisticRegression (LR) 、Support Vector Machine(SVM) 等。
4. 可选择的计算模型:综述中我们提到了,Angel的参数服务器可以支持BSP,SSP,ASP计算模型。
5. 更细粒度的容错:在系统中容错主要分为Master的容错,参数服务器的容灾,Worker进程内的参数快照的缓存,RPC调用的容错。
6. 友好的任务运行及监控: Angel也具有友好的任务运行方式,支持基于Yarn的任务运行模式。同时,Angel的Web App页面也方便了用户查看集群进度。
2)参数服务器
在实际的生产环境中,可以直观的感受到Spark的Driver单点更新参数和广播的瓶颈,虽然可以通过线性拓展来减少计算时的耗时,但是带来了收敛性下降的问题,同时更严重的是在数据并行的运算过程中,由于每个Executor都保持一个完整的参数快照,线性拓展带来了N x 参数快照的流量,而这个流量集中到了Driver一个节点上!

从图中看到,在机器学习任务中,Spark即使有更多的机器资源也无法利用,机器只在特定较少的规模下才能发挥最佳性能,但是这个最佳性能其实也并不理想。
采用参数服务器方案,我们与Spark做了如下比较:在有5000万条训练样本的数据集上,采用SGD解的逻辑回归模型,使用10个工作节点(Worker),针对不同维度的特征逐一进行了每轮迭代时间和整体收敛时间的比较(这里Angel使用的是BSP模式)。

通过数据可见,模型越大Angel对比Spark的优势就越明显。
3)内存优化
在运算过程中为减少内存消耗和提升单进程内运算收敛性使用了异步无锁的Hogwild! 模式。同一个运算进程中的N个Task如果在运算中都各自保持一个独立的参数快照,对参数的内存开销就N倍,模型维度越大时消耗越明显!SGD的优化算法中,实际场景中,训练数据绝大多数情况下是稀疏的,因此参数更新冲突的概率就大大降低了,即便冲突了梯度也不完全是往差的方向发展,毕竟都是朝着梯度下降的方向更新的。我们使用了Hogwild!模式之后,让多个Task在一个进程内共享同一个参数快照,减少内存消耗并提升了收敛速度。
4)网络优化
我们有两个主要优化点:
1)进程内的Task运算之后的参数更新合并之后平滑的推送到参数服务器更新,这减少了Task所在机器的上行消耗,也减少了参数服务器的下行消耗,同时减少在推送更新的过程中的峰值瓶颈次数;
2)针对SSP进行更深一步的网络优化:由于SSP是一种半同步的运算协调机制,在有限的窗口运行训练,快的节点达到窗口边缘时,任务就必须停下来等待最慢的节点更新最新的参数。针对这一问题,我们通过网络流量的再分配来加速较慢的工作节点。我们给较慢的节点以更高的带宽;相应的,快的工作节点就分得更少的带宽。这样一来,快的节点和慢的节点的迭代次数的差距就得以控制,减少了窗口被突破(发生等待)的概率,也就是减少了工作节点由于SSP窗口而空闲等待时间。
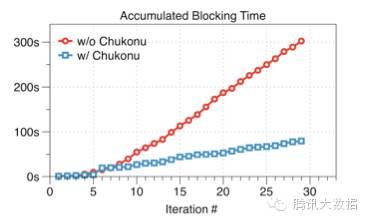
如下图所示,在1亿维度、迭代30轮的效果评测中,可以看到Chukonu使得累积的空闲等待时间大幅度减少,达3.79倍。
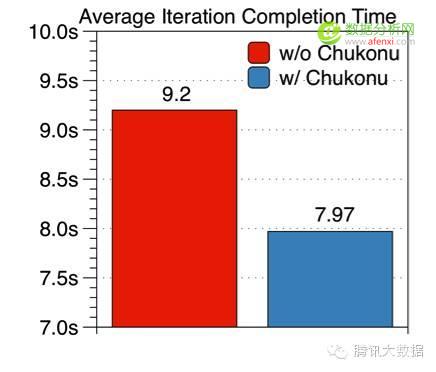
下图展示的是优化前后的执行时间,以5000万维度的模型为例,20个工作节点和10个参数服务器,Staleness=5,执行30轮迭代。可以看出,开启Chukonu后平均每轮的完成时间只需7.97秒,相比于比原始的任务平均每轮9.2秒有了15%的提升。
另外,针对性加速慢的节点可以使慢的节点更大可能的获得最新的参数,因此对比原始的SSP计算模型,算法收敛性得到了提升。下图所示,同样是针对五千万维度的模型在SSP下的效果评测,原生的Angel任务在30轮迭代后(276秒)loss达到了0.0697,而开启了Chukonu后,在第19轮迭代(145秒)就已达到更低的loss。从这种特定场景来看有一个接近90%的收敛速度提升。

后续计划
未来,项目组将扩大应用的规模,同时,项目组已经在继续研发Angel的下一版本,下一个版本会在模型并行方面做一些深入的优化。另外,项目组正在计划把Angel进行开源,我们会在后续合适的时机进行公开。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330