协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。
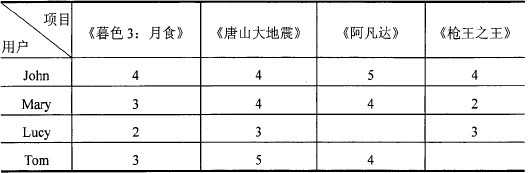
基于用户的(User based)协同过滤算法是根据邻居用户的偏好信息产生对目标用户的推荐。它基于这样一个假设:如果一些用户对某一类项目的打分比较接近,则他们对其它类项目的打分也比较接近。协同过滤推荐系统采用统计计算方式搜索目标用户的相似用户,并根据相似用户对项目的打分来预测目标用户对指定项目的评分,最后选择相似度较高的前若干个相似用户的评分作为推荐结果,并反馈给用户。这种算法不仅计算简单且精确度较高,被现有的协同过滤推荐系统广泛采用。User-based协同过滤推荐算法的核心就是通过相似性度量方法计算出最近邻居集合,并将最近邻的评分结果作为推荐预测结果返回给用户。例如,在下表所示的用户一项目评分矩阵中,行代表用户,列代表项目(电影),表中的数值代表用户对某个项目的评价值。现在需要预测用户Tom对电影《枪王之王》的评分(用户Lucy对电影《阿凡达》的评分是缺失的数据)。

由上表不难发现,Mary和Pete对电影的评分非常接近,Mary对《暮色3:月食》、《唐山大地震》、《阿凡达》的评分分别为3、4、4,Tom的评分分别为3、5、4,他们之间的相似度最高,因此Mary是Tom的最接近的邻居,Mary对《枪王之王》的评分结果对预测值的影响占据最大比例。相比之下,用户John和Lucy不是Tom的最近邻居,因为他们对电影的评分存在很大差距,所以JohLn和Lucy对《枪王之王》的评分对预测值的影响相对小一些。在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。由上面的例子不难知道,User一based协同过滤推荐算法的主要工作内容是用户相似性度量、最近邻居查询和预测评分。
目前主要有三种度量用户间相似性的方法,分别是:余弦相似性、相关相似性以及修正的余弦相似性。
①余弦相似性(Cosine):用户一项目评分矩阵可以看作是n维空间上的向量,对于没有评分的项目将评分值设为0,余弦相似性度量方法是通过计算向量间的余弦夹角来度量用户间相似性的。设向量i和j分别表示用户i和用户j在n维空间上的评分,则用基于协同过滤的电子商务个性化推荐算法研究户i和用户j之间的相似性为:
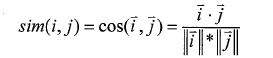
②修正的余弦相似性 (AdjustedCosine):余弦相似度未考虑到用户评分尺度问题,如在评分区间[1一5]的情况下,对用户甲来说评分3以上就是自己喜欢的,而对于用户乙,评分4以上才是自己喜欢的。通过减去用户对项的平均评分,修正的余弦相似性度量方法改善了以上问题。用几表示用户i和用户j共同评分过的项集合,Ii和寿分别表示用户i和用户j评分过的项集合,则用户i和用户j之间的相似性为:
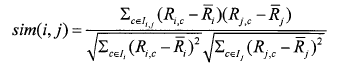
③相关相似性(Correlation)此方法是采用皮尔森(Pearson)相关系数来进行度量。设Iij表示用户i和用户j共同评分过的项目集合,则用户i和用户j之间相似性为:
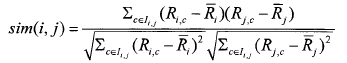
在得到目标用户的最近邻居以后,接着就要产生相应的推荐结果。设NNu为用户u的最近邻居集合,则用户u对项j的预测评分Puj计算公式如下:
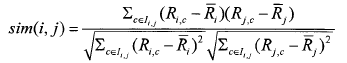
基于项目的(Item一based)协同过滤是根据用户对相似项目的评分数据预测目标项目的评分,它是建立在如下假设基础上的:如果大部分用户对某些项目的打分比较相近,则当前用户对这些项的打分也会比较接近。ltem一based协同过滤算法主要对目标用户所评价的一组项目进行研究,并计算这些项目与目标项目之间的相似性,然后从选择前K个最相似度最大的项目输出,这是区别于User-based协同过滤。仍拿上所示的用户一项目评分矩阵作为例子,还是预测用户Tom对电影《枪王之王》的评分(用户Lucy对电影《阿凡达》的评分是缺失的数据)。
通过数据分析发现,电影《暮色3:月食》的评分与《枪王之王》评分非常相似,前三个用户对《暮色3:月食》的评分分别为4、3、2,前三个用户对《枪王之王》的评分分别为4、3、3,他们二者相似度最高,因此电影《暮色3:月食》是电影《枪王之王》的最佳邻居,因此《暮色3:月食》对《枪王之王》的评分对预测值的影响占据最大比例。而《唐山大地震》和《阿凡达》不是《枪王之王》的好邻居,因为用户群体对它们的评分存在很大差距,所以电影《唐山大地震》和《阿凡达》对《枪王之王》的评分对预测值的影响相对小一些。在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。
由上面的例子不难知道,Item一based协同过滤推荐算法的主要工作内容是最近邻居查询和产生推荐。因此,Item一based协同过滤推荐算法可以分为最近邻查询和产生推荐两个阶段。最近邻查询阶段是要计算项目与项目之间的相似性,搜索目标项目的最近邻居;产生推荐阶段是根据用户对目标项目的最近邻居的评分信息预测目标项目的评分,最后产生前N个推荐信息。
ltem一based协同过滤算法的关键步骤仍然是计算项目之间的相似性并选出最相似的项目,这一点与user一based协同过滤类似。计算两个项目i和j之间相似性的基本思想是首先将对两个项目共同评分的用户提取出来,并将每个项目获得的评分看作是n维用户空间的向量,再通过相似性度量公式计算两者之间的相似性。
分离出相似的项目之后,下一步就要为目标项目预测评分,通过计算用户u对与项目i相似的项目集合的总评价分值来计算用户u对项目i的预期。这两个阶段的具体公式和操作步骤与基于用户的协同过滤推荐算法类似,所以在此不再赘述。
与基于内容的推荐算法相比,协同过滤有下列优点:能够过滤难以进行机器自动基于内容分析的信息。如艺术品、音乐;能够基于一些复杂的,难以表达的概念(信息质量、品位)进行过滤;推荐的新颖性。
然而,协同过滤也存在着以下的缺点:用户对商品的评价非常稀疏,这样基于用户的评价所得到的用户间的相似性可能不准确(即稀疏性问题);随着用户和商品的增多,系统的性能会越来越低(即可扩展性问题);如果从来没有用户对某一商品加以评价,则这个商品就不可能被推荐(即最初评价问题)。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;

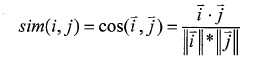
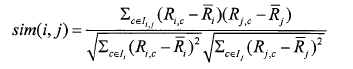
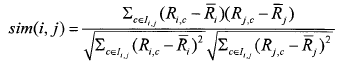
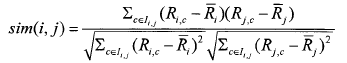










 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330