如何用SPSS绘制质量控制图?
控制图(Control Chart)又称管理图,它是用来区分是由异常原因引起的波动,还是由过程固有的原因引起的正常波动的一种有效的工具。控制图通过科学的区分正常波动和异常波动,对工序过程的质量波动性进行控制,并通过及时调整消除异常波动,使过程处于受控状态。不仅如此,通过比较工序改进以后的控制图,还可以确认此过程的质量改进效果。因此,控制图在质量管理中有着广泛的应用。
控制图由样本均值服从于正态分布演变而来。正态分布可用两个参数即均值μ和标准差σ来决定。正态分布有一个结论对质量管理很有用,即无论均值μ和标准差σ取何值,产品质量特性值落在μ±3σ之间的概率为99.73%,落在μ±3σ之外的概率为100%-99.73%= 0.27%,而超过一侧,即大于μ+3σ或小于μ-3σ的概率为0.27%/2=0.135%≈1‰,,休哈特就根据这一事实提出了控制图。图上有中心线(CL)、上控制限(UCL)和下控制限(LCL),并有按时间顺序抽取的样本统计量数值的描点序列。
多数情况下是通过人工来绘制控制图,首先通过计算器计算各种指标,然后再一步步地绘制控制图。在这个过程中,往往会出现计算错误或者误差过大等原因,使得最后的控制图达不到预期的效果,更为严重的是能使质量管理者产生错误的判断,做出错误的决策,从而产生较大的损失。也有的企业利用excel绘制控制图,从而提高其精确度,减少误差。然而,用excel绘制控制图的步骤比较繁杂,不容易掌握,容易在绘制过程中产生操作性失误,造成数据集的失真。
SPSS的图形工具非常强大,具有很强的统计分析功能。在质量数据管理中,经常要用到一些图形方法和工具,例如帕雷托图、直方图、散点图、控制图、序列图等,SPSS均可以有效地应用这些图形方法和工具来处理质量数据信息,这些功能集中在Graph菜单中。
因此,此处我们采用SPSS来绘制控制图。
SPSS控制图的选择依据(X-R或X-S和X-MR)
根据主要测量值分组变量的具体情况,可选择X-R、X-S,即均值-极差和均值-标准差控制图;或者选择X-MR,个体-移动均值控制图。
1、分组变量中有大于10个组值,宜于计算标准差,故选择X-S控制图。
2、分组变量中有小于10个组值,选择计算极差,即X-R控制图。
3、分组变量中只有1个组值,则选择个体-极差控制图,即X-MR控制图。
案例:个体-移动极差控制图
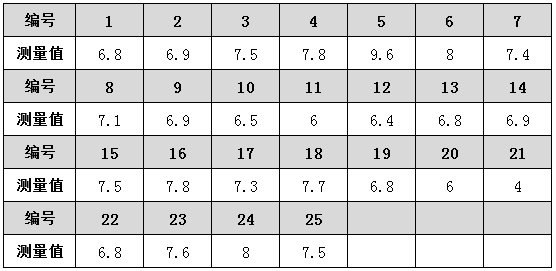
数据data17-18为某搅拌站实测混凝土坍落度数据,现在使用控制图看看工艺质量情况。
步骤:
分析—质量控制—控制图—个体/移动全距—个案为单元
过程度量:选择“测量值变量;标注子组:选择“编号”
自动生成以下两组控制图,可用于综合解读。
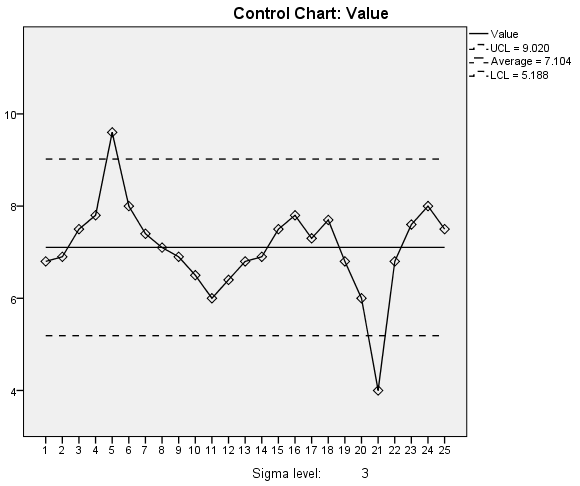
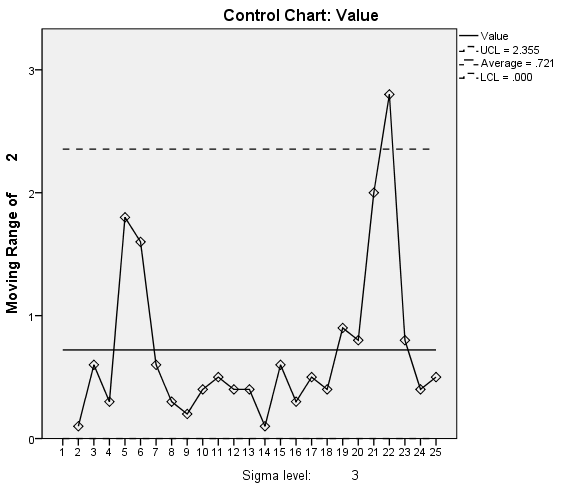
第一张是均值X的控制图,第二张是移动均值的控制图。上面我们已经完成了数字层面的分析,最关键的则是发现数据的异常和寻找异常发生的原因。由于本案例数据源来自书籍,并无具体案例数据的实际描述,因此不宜在此处做过多的解读。详细的规则解读可参考以下内容。
质量控制图的使用规则
既然质量控制图是为了帮助我们及时发现指标的不正常状态,那么当我们看到上面的图以后,需要观察和分析是不是存在异常的点或异常的变化趋势,如何定义这些异常,需要有一套控制规则:即样本点出界或者样本点排列异常:
点超出或落在ULC或LCL的界限;(异常)
近期的3个点中的2个点都高于+2σ或都低于-2σ,近期5个点中的4个点都高于+σ或都低于-σ;(有出现异常的趋势)
连续的8个点高于中心线或低于中心线;(有偏向性)
连续的6个点呈上升或者下降趋势;(有明显的偏向趋势)
连续的14个点在中心线上下呈交替状态。(周期性,不稳定)
查资料时发现不同的地方对控制规则有不同的定义,我这里参照的是SPSS里面的规则,具体应该可以根据实际的应用环境进行调整。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330