从客户满意度出发建立呼叫中心质检评分标准
背景:提升客户满意度是呼叫中心永恒的话题之一,从大的方面来看,主要是通过优化系统、完善流程、提升座席的服务质量三方面入手。本文主要介绍的,是基于统计学理论建立一套与客户满意度相关的质检评分标准。
首先的一个问题是,贵公司的质检成绩同客户满意度相关吗(前提是在所有QC打分标准都一致的情况下)?如果贵公司的客户满意度同质检成绩相关,那么恭喜你,此篇文章可以跳过了~
如果不相关,那原因是什么呢?
需要先解决一个问题,我们用什么来衡量相关性?
业内的常规做法应该是使用质检成绩同客户满意度来做相关性检验,检验使用的是皮尔森相关系数(即Excel里面常用的CORREL函数),这样的检验方法真的正确吗?
我们先从统计学的角度来看这个问题:
皮尔森相关系数是对于符合正态分布的连续型变量进行的检验,即需要对于N名员工的质检成绩与N名员工的满意度结果数据进行操作,其中满意度的数据获取非常容易,且符合样本量的需求,但是N名员工的质检成绩是否能够反应真实水平呢?
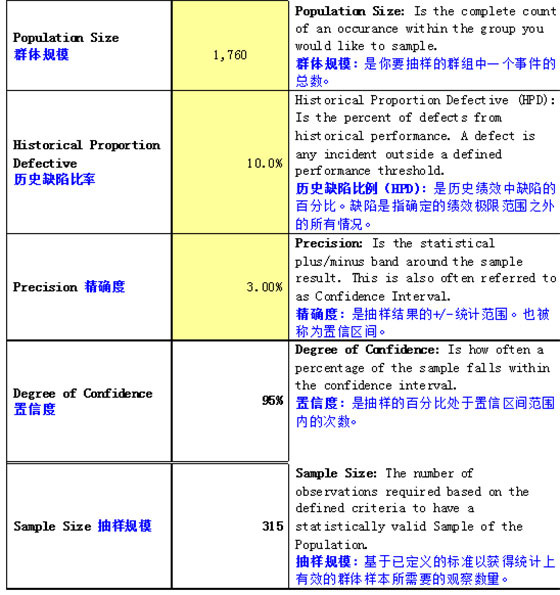
毕竟抽查的样本数量有限,我们来看下《抽样计算器》的计算结果:
假设呼叫中心的客户满意度为90%,那么历史缺陷比为10%;22个工作日,每日接线80通,一个月的样本量为:22×80=1760,计算得到需要抽查的样本量为315通(具体数据见附一)。
会有呼叫中心每个月对于座席的录音抽取超过315通吗?
根据业内水平,一个座席一个月能被抽到20通录音已经非常高了!
统计学结论:通过抽查计算的质检分数并不能代表员工的实际质检成绩,那怎么能让你的质检成绩和员工满意度相关呢?
问题随之而来,究竟如何判定质检成绩和客户满意度的相关性?我们的质检标准究竟是不是和客户的实际需求相关?
其实操作很简单:我们引入单通录音评分和单通录音客户满意度的相关性,即使用Logistic回归分析方式对于N列离散数据计算其相关性。
单通录音打分表事例如下:

那我们的这个打分表和客户评价的满意度的相关性是多少呢?
我们来使用JMP软件中的Logistic分析操作,得出W检验数据如下:
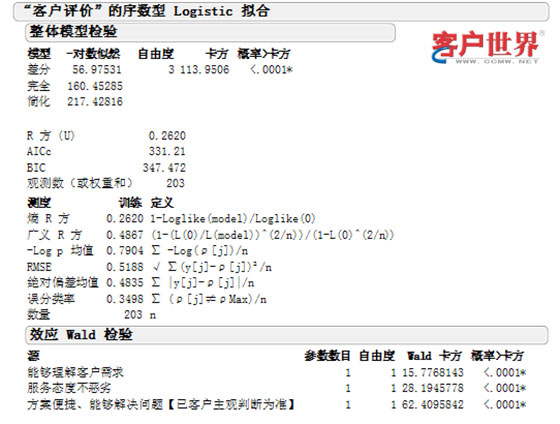
可以看出这三个评分标准与客户满意度的卡方值非常高,且P值低于0.005,表明此标准与客户满意度相关。
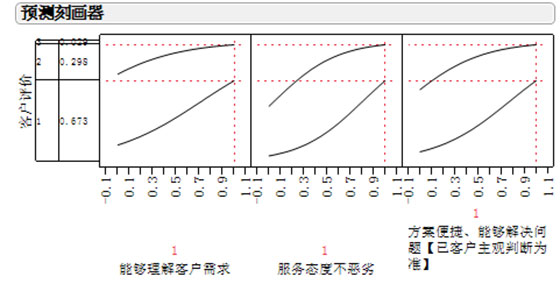
同时我们也可以使用JMP中特有的“刻画器”工具来进行预估,即我们能够清楚的知道这三项的质检成绩对于满意度的影响情况。
如果这三项都得1分的情况下,客户的不满意度为3%
如果这三项都得0.7分的情况下,客户的不满意度为32%
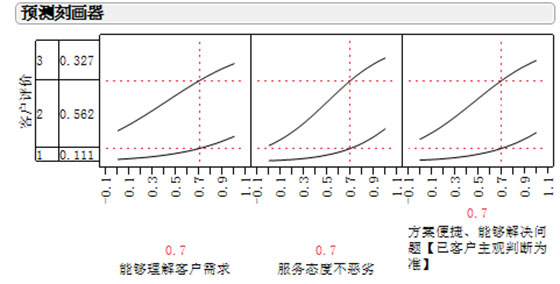
备注:此数据结论是基于200通录音打分后的结果
我们已经找到评估质检标准同客户满意度相关性的计算模型了,那么相信你现在一定迫不及待要看看自己公司的打分表是否和客户满意度相关,很遗憾地告诉你,不出意外的话,你们的质检标准会和客户满意度相关性很差的,为什么?
我们从业务的角度来看这个问题:
质检评分标准很多东西都是公司要求的,例如称呼客户姓氏、要确认客户问题、语速适中语调上扬等等,更不用说后台的CRM录入、流程的执行(客户是不会关心公司的流程的)、工单派发准确率等等了,但是也别灰心,通过这个方式,如果能够找到2~3个打分标准有较高的相关性就已经非常好了!
举例:
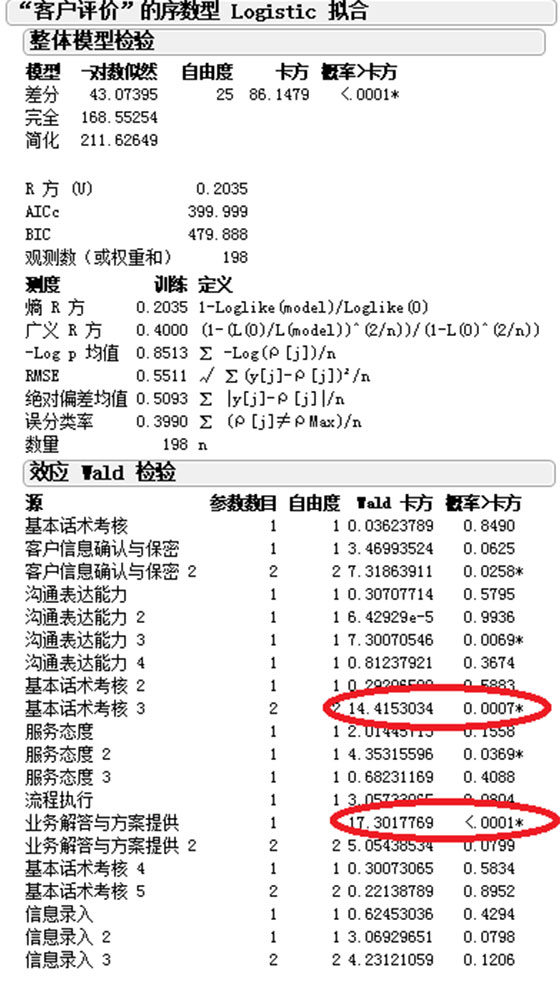
以上内容希望对于大家制定服务中心质检评分标准时有所帮助,谢谢!
附一:
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330