隐树模型的学习
隐树模型的学习是一个对模型逐步优化的过程,优化的目标函数是一个称为贝叶斯信息准则(Bayes information criterion, 简称BIC) 的函数:
BIC(m|D) = max θ log P(D|m, θ) – d(m)logN/2
BIC准则要求模型与数据尽量紧密地拟合,但其复杂不能过高。所以式中第一项表示拟合程度,而第二项是对于模型复杂度的一个惩罚项。我们的优化过程是一个基于搜索的爬山算法(Hill-Climbing)。以只包含一个隐变量的简单的隐树模型作为搜索的起始模型,在搜索的过程中,逐步引入新的隐变量、增加隐变量的取值个数、或者调整变量之间的连接。这是一个逐步修改模型的过程,在这个过程中,模型与数据的拟合程度不断改进,从而BIC分逐步增加。当模型就变得太复杂时,BIC会不升反降,于是搜索过程停止。
隐树模型的学习是一个非常耗时的过程,主要原因在于对于BIC分数的计算。BIC函数的第一项叫做最大似然函数,在模型包含缺失值或者隐变量时,计算最大似然函数需要调用EM(Expectation-Maximization)算法。尽管我们已经对于限制了模型结构为简单的树状结构,但是在这样的模型上进行EM的计算依然是非常困难。围绕隐树模型的很多工作都是在研究如何对模型学习进行加速的,这儿就不赘述了。
基于隐树模型的多维聚类分析实例

我们以一个真实的数据分析实例来展现多维聚类分析。数据来自某地区的关于贪污的社会调查问卷。通过一些数据预处理,我们的数据(如图所示)包含了1200份的问卷,以及31个问题。比如说C_City表示被访问者对于该地区的贪污普遍性的看法,可以有4个选项,分别是非常普遍,普遍,不普遍,以及非常不普遍。C_Gov和C_Bus分别表示受访者对于该地区政府部门或商业部门的贪污普遍性的看法,同样也有四个选项。Tolerance_C_Gov和Tolerance_C_Bus则分别表示受访者对于该地区的政府部门以及商业部门的贪污的容忍程度,可以选择完全不能容忍,不能容忍,能容忍,完全能容忍。数据表里面的-1表示受访者对该问题的回答缺失。
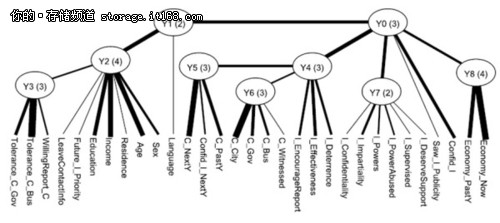
利用隐树的学习算法,我们从这个数据得到了一个如图所示的模型。叶节点对应问卷问题,即显变量。中间结点,Y0-Y8是从数据中发现的隐变量,括号里面的数字表示这个变量所取的状态个数。我们发现这些隐变量都有一定的意义,比如,Y2和问卷中的Sex,Age,Income,Education这些问题紧密连接,说明Y2应该是表示受访人的人口统计信息。Y3和问卷中的Tolerance_C_Gov和Tolerance_C_Bus紧密联系,说明Y3是反映受访者总体对于贪污的看法。
模型中的每个隐变量表示数据聚类的一种方式。比如,变量Y2有4个值,说明Y2提示数据可以分成四个类。这种聚类主要基于Sex,Age,Income,Education这些人口统计信息相关变量的,所以可以说当我们关注人群的人口统计信息这个侧面时,我们可以根据Y2把人群分成四类。具体地研究这四类的类条件概率(Class-Conditional ProbabilityDistribution)特性,我们进一步发现它们分别代表:低收入的年轻人群,低收入的女性人群,受过高等教育的高收入人群,以及只接受初等教育的一般收入人群。同时,我们看到Y3有3个取值,这说明从人群对于贪污总体看法这个侧面出发,可以把人群分成三类,分别是对于贪污完全不能容忍的人群,对于贪污比较不能容忍的人群,对于贪污可以容忍的人群。同样地,我们的聚类也可以基于其他隐变量所代表的侧面。这样从模型中我们得到了9种聚类的方法,达到了多维同时聚类的效果。











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330