近日,大数据应用与服务提供商“数说故事”发布了旗下一款面向数据分析师的在线商业智能产品:数说立方。该产品为数据分析师,特别是进行文本大数据挖掘的分析师,提供全新的优质BI体验。

当前,数据逐渐在企业端扮演着仪表盘、方向盘、发动机的三重角色。开放的互联网为企业进行市场、品牌研究,消费者洞察、营销传播研究提供了丰富的数据源,同时也给数据分析师们带来了难题。第一,数据量巨大,已经超过了单机Excel等工具的能力范围;第二,目前主流的BI产品主要支持对结构化数据的分析,互联网大数据基本上是非结构化的,文本的数据。数据分析需要多道工序环环相扣紧密配合,从数据采集、数据清洗、数据建模、量化分析、可视化等,是一个复杂且繁重的过程。在海量的数据基数下,处理的难度被指数级的放大。这对于分析师来说简直就是噩梦。
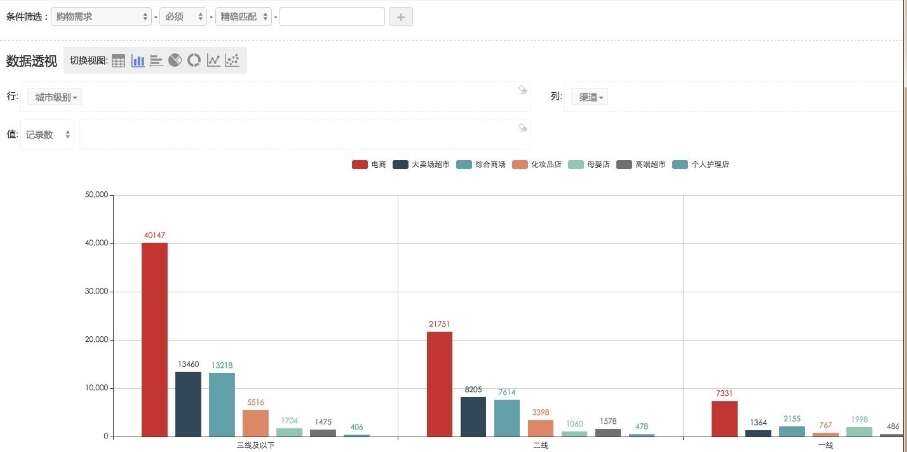
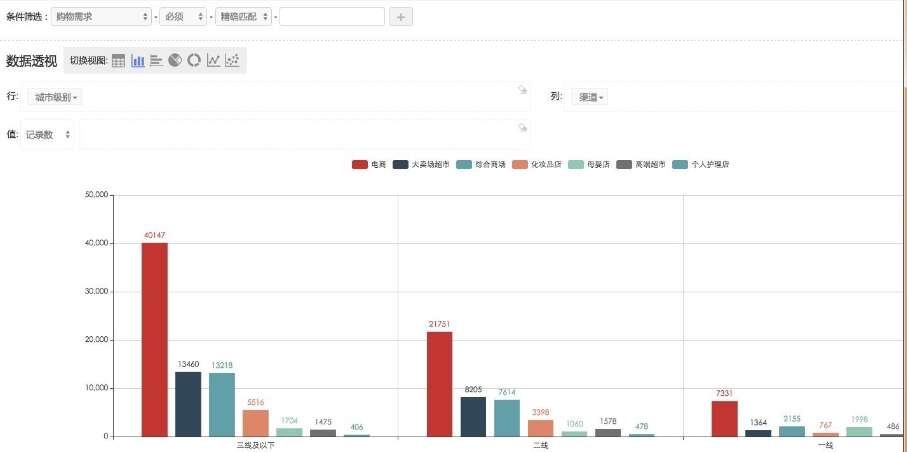
数说立方为文本大数据分析师量身定制,它的背后是一个海量计算平台,创造式地搭载了分布式搜索、语义分析、数据可视化三大引擎系统,解决海量文本数据挖掘的难题。
分布式搜索引擎使得数说立方可以像普通搜索引擎一样,通过各种关键词组合条件筛选,快速定位和过滤文本数据。
语义分析引擎标配了文本分析师必备的情感分析、实体识别、语言消歧、文本分类聚类等自然语言处理算法。
实时数据可视化引擎使得分析师可以第一时间获得数据的可视化反馈,快速动态调整定义、模型等前序参数。三者搭配,为分析师提供颠覆式的海量文本数据实时可视化处理平台。
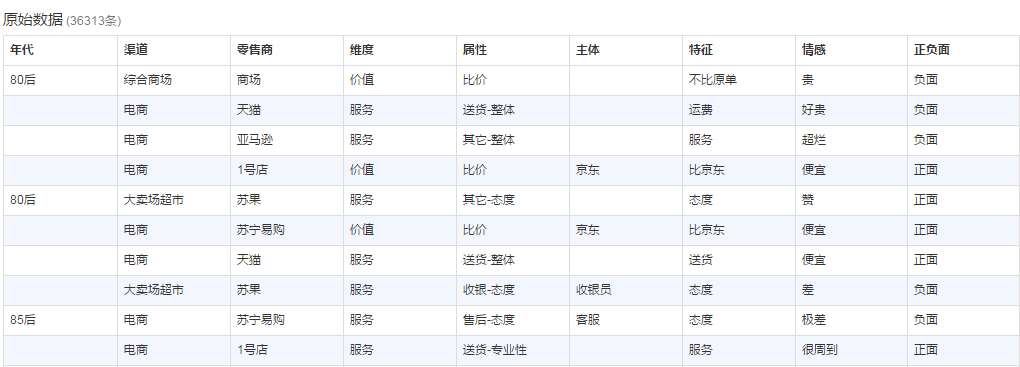
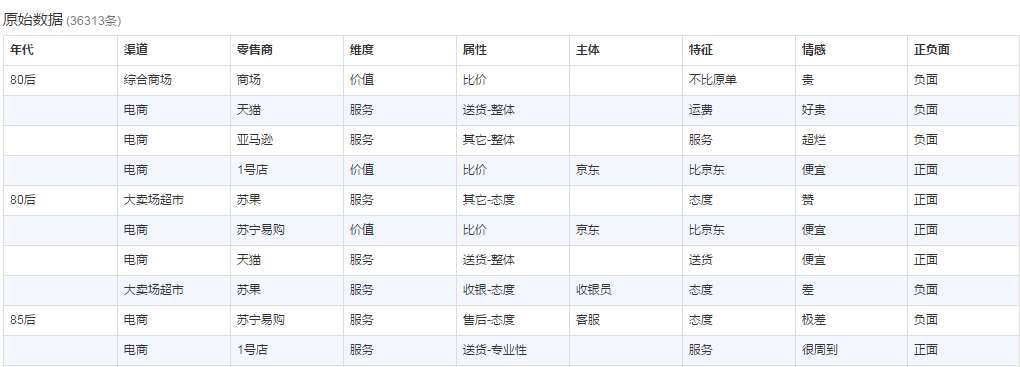
数说立方追求分析师的极致体验。它的本质是一个BI产品,它拥有基础的数据布尔查询、OLAP、可视化。面对海量非结构化数据,实现“秒级响应”和“简单操作”。量级上亿数据也要求秒级响应,轻点图表即可追溯到原始数据,文本挖掘算法成为标配。除此之外,数说立方还配备亿级Socia人群洞察数据库,支持全网实时数据源的无缝接入,是一个完整的互联网大数据洞察平台。

数说故事联合创始人郭怡适博士表示,数说立方从产品团队启动到发布1.0版本,仅用了一个多月的时间。这完全取决于数说故事在海量数据处理、文本数据挖掘和数据可视化的长期技术积累。“数说立方一开始是为了服务我们内部的数据分析师。面对海量文本数据,分析师们捉襟见肘,由于缺乏适合的工具,很多时候还需要寻求程序员的支撑,反复沟通带来了时间和精力的巨大损耗“。“以往想要对提及“圣诞节”,并且抱怨“没有礼物”的所有微博用户进行人群洞察,分析不同城市、不同年龄、不同性别的用户消费偏好,一个完整的流程一般需要一两天甚至一周的时间,而在数说立方上面,仅需要几个简单的Query即可完成“。“我们要解放数据分析师,让分析师将更多的智慧投入到数据的洞察中”。
目前数说立方1.0将采用邀请制的方式,向数据分析师开放免费试用,用户可联系客服获取试用权限。
除了数说立方之外,数说故事在春节前还将陆续推出另外两款重量级数据产品——“数说聚合”和“数说雷达”。前者解决企业获取数据的问题,提供统一的互联网数据API;后者网罗互联网上关于一个企业、品牌的所有可见数据,帮助企业快速搭建外部大数据平台。这三款产品,从数据源、数据分析、到数据展示形成完整的闭环将为企业提供一站式的互联网数据快速解决方案。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;













 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330