01专家简介
徐杨老师,CDA数据科学研究院教研副总监,主要负责CDA认证项目以及机器学习/人工智能类课程的研发与授课,负责过中国人民银行结算中心数据分析内训、华夏银行数据分析内训、苏州银行总行数据挖掘内训项目,英国影子银行风险监管分析,纽约市场对香港市场高频交易分析项目。
在大厂的技术面试中,有两个地方是非常有难度的。很多小伙伴都折在的这两个地方。

1、算法的笔试题
我们知道大部分人在写算法的时候,通常都是把函数的前几个字母打出来,或者变量名的前几个字母打出来。按一下Tab或者按一下快捷键,就可以带出整个的函数名,然后自己就可以继续往后去写了。

比如说,之前就有一位小伙伴在笔试的时候拿到了一个手写算法的题。
那么分类算法比较好的有什么?有XGBoost,对吧?于是,小伙伴大笔一挥写下了import XGBoost。
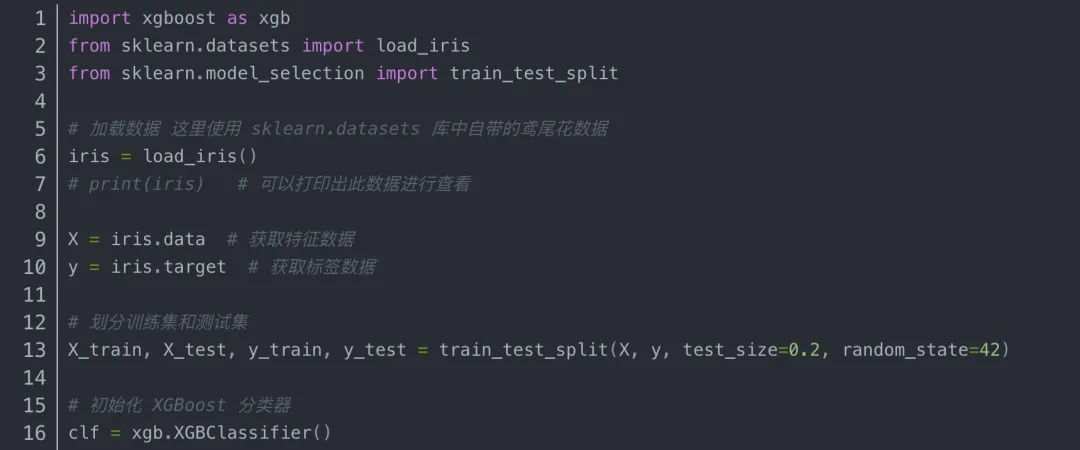
扣分的原因是什么?
sklearn里那个包的名字叫什么?叫XGBoost吗?不是,那个包的名字叫XGBClassifier。

这是一个很让人痛苦的事情,算法你会,但是你写不出来。
那就要求大家在日常的学习与工作中,一定要把常用的算法语句用的滚瓜烂熟,才可以让我们在这样的问题上有比较好的回答成果。
CDA数据分析师的能力测试大家可以抽空做做,提高一下自己对模型、函数的敏感度。

2、技术问题深挖掘
第二个在大厂面试中的难点是,把一个技术问题往下深挖好几次。
比如说最简单的一个算法回归分析。有可能在面试的时候面试官问你:
—— 同学,线性回归会吗?
—— 线性回归不能有共线性,你知道吗?
Ok,开始提问。
你解释了一下。我相信大部分小伙伴都可以解释的很清楚。
下面再往下挖一层:怎么检测共线性?
有的小伙伴可能直接就说,共线性嘛,系相关系数就可以啊。
结果被扣分了。为什么?

我们现在要检测的是线性回归里的相关性,那是要考虑偏相关问题的。只用相关技术矩阵可以吗?不够用的,应该用一些更加深入的指标,比如说VIF值等等去检测。
比如说这个问题你正确的回答了出来,检测变量之间的相关性,可以使用VIF值。

那就再往下挖,为什么要检测变量之间的相关性呢?
如果我不考虑这个问题会有怎样的结果出现,那么你不能只回答,如果不考虑共线性问题的话,我这个模型预测效果不好。
显然面试官想要的不是这么直接的回答,他想问你的是这个问题的技术细节。

所以你在这个地方应该回答出的是:
如果我们不处理共线性的问题,就会导致最后最小二乘法所需要的逆矩阵在被计算的时候,这个矩阵的行列式的值就会非常小。于是导致我们求出来的逆矩阵就会非常的大。这是一个非常不好的结果。你求出的矩阵,用这个矩阵算出来的所有参数的取值全都趋近于正无穷,你觉得这个效果能好吗?显然有问题。

如果到这儿你仍然可以准确的回答出来,这已经被挖了三次了,但是你要知道这个问题还可以继续往后挖。
我们再往后挖就是,如果普遍检测出了一共10个变量,这10个变量普遍VIF值都比较高,我们有什么好的方法来处理?
有同学可能马上就会说,正则化方法嘛。

正则化方法又可以问问题了。
正则化方法有偏还是无偏?用完了以后效果怎么样?哪个包可以实现?
我们发现这种技术问题,面试官可以就一个点给你一直往下深挖好几层。
我看过一个调查,同一个问题,当一般往下深挖到第5层的时候,大部分人就已经回答不出来了。

所以这就要求大家平时在学习与工作中,要把每一个技术细节都掌握好,要把技术细节之间的联系找到。因为往下深挖,其实挖的就是这些技术点之间的联系,这是第二个在大场面之中非常容易折的一个点。
CDA数据分析师认证考试的一级和二级都注重对基础概念和知识的挖掘,这些考点都是结合给大厂、银行、金融机构内训总结出来的工作中最实用的技能和知识点。
抓住机遇,狠狠提升自己
随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论、商业模型、SQL,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。

CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330