持证人简介
郭畅,CDA数据分析师二级持证人,安徽大学毕业,目前就职于徽商银行总行大数据部,两年工作经验,主要参与两项跨部门项目建设,项目中主要负责模型开发,数据分析,模型运营优化等工作。
01 银行大数据部工作重点
风控是互联网信贷的工作重心,机器学习算法在做逾期客户以及防作弊和反诈预测上会使用到,然而在“算法”、“模型”之前还有最重要的,也是我们在工作中最费时的数据预处理及特征筛选的部分。
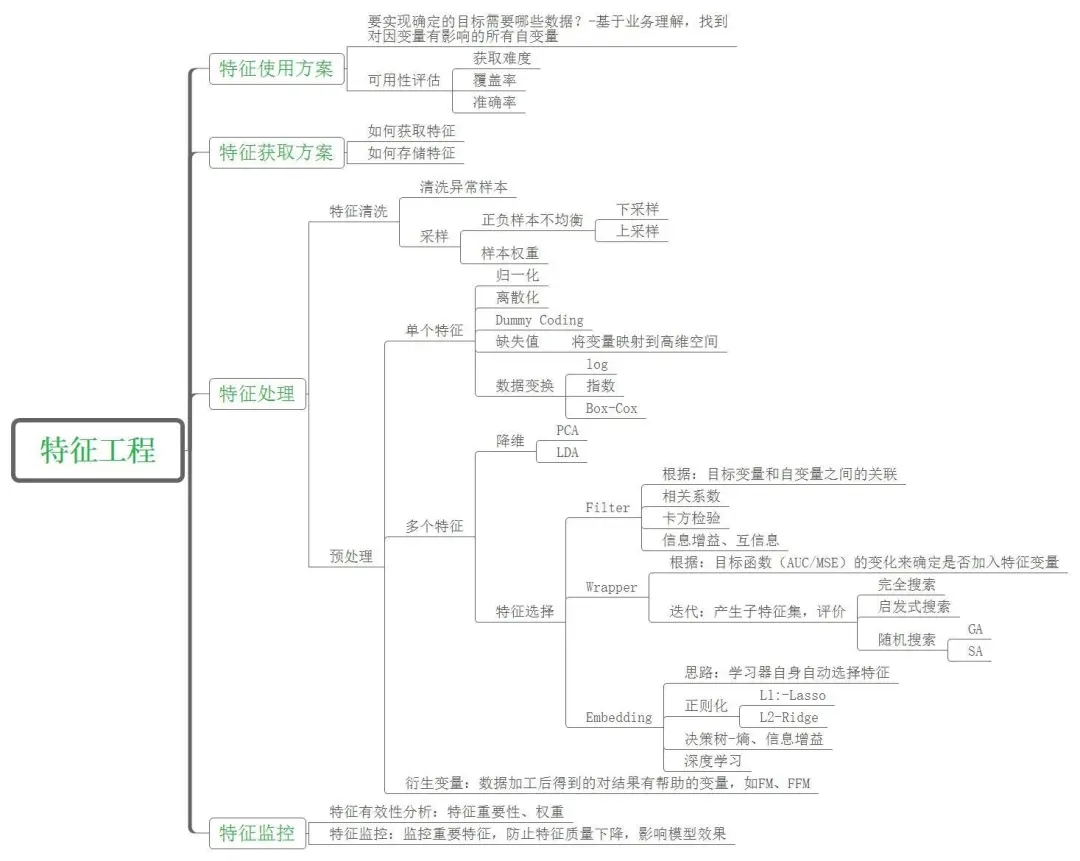
在工作的这两年中,我开始认识到业务的重要性,毕竟模型是为业务赋能,会应用到具体的业务场景,所做的模型都需要结合不同的业务场景设计不同的指标,设计的指标也会根据业务场景、应用做筛选,具体问题具体分析。但是业务分析、数据获取、数据预处理、建模、模型评估以及应用等流程重合度还是比较高的。
02 银行模型开发工作流程
在数据提取方面用的最多的还是 SQL 语言,因为银行数据大部分都在数据仓库里;建模、模型运营分析方面一般用 Python。
我们进行模型开发时都是根据业务部门需求进行,所以需要先确定业务需求,明确了业务需求后,需要分析数据可用性、特征构建、建模、评估等等。在实际工作中,我目前遇到的模型分为规则模型、机器学习模型以及两种相结合的模型。
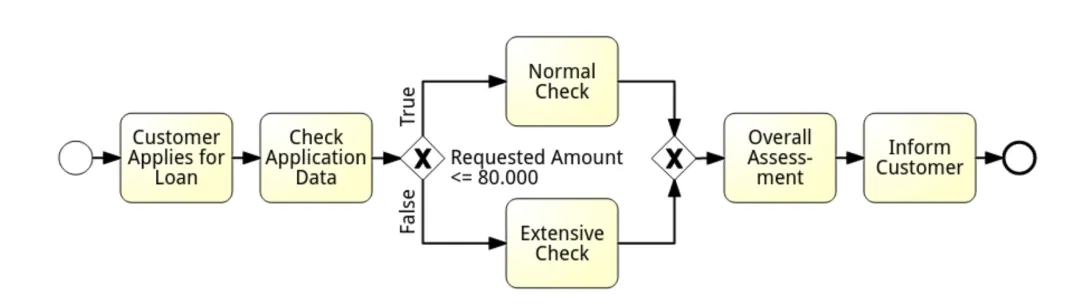
在工作之前我也觉得规则模型比较简单,但是实际工作中就知道,针对特定场景、特定政策要求规则模型必不可少,针对规则模型,业务要求、监管及政策导向极其重要,如何量化指标、如何调优是及其重要的部分;而针对于机器学习模型,特征筛选、模型构建调优中,模型本身、算法却是重点之一。
这些工作对我来说,难度不是特别大,因为研究生期间研究方向是机器学习、数据挖掘方面的,读研期间考了CDA数据分析师二级,那段时间发现机器学习、特征工程这些与CDA二级考试内容比较相符,加上有实操考试,就想边学习边考CDA可能更系统一点,也能检测自己学习情况。而后来在找工作的途中也发现这方面知识还是比较热门的,特别是在银行数字化转型的背景下。
日常工作中,遇到的数据存在各种各样的问题,
这些在我备考CDA数据分析师期间都认真学过,并且和实际工作也都有所重合。
入职银行两年多,由于所在的岗位比较对口,之前学习的内容还是比较有用的,比如说评分卡模型、逻辑回归、随机森林、GBDT、XGBOOST算法等等在当前的互联网信贷上都常会用到。
模型优化其实应该是贯穿整个模型生命周期必不可少的环节,应该说是一个长期工作,但不能说是一定周期就一定要进行模型优化。
在我当前的工作中,模型优化有两个原因:
对于前者,是指针对不同的业务场景和产品需要,结合业务或者产品的变动需要进行的模型优化。

对于后者是指在模型运营分析的过程中发现的问题进行优化,举个例子,对于互联网信贷模型,准入端、模型端、授信端都有各自的模型或规则,如果某些规则、特征出现波动,针对波动出现的原因需要进行分析,如果确认是模型对当前的客群出现了偏差,则应该进行不同程度的调整。
所以,模型优化不是单独进行的,需要和业务需要以及日常模型监控相结合。
在过往的工作中,我参与的两次模型优化,模型优化不是独立出来的过程,也是需要从好坏客户定义、样本提取、查看分布、优化调整、评估优化结果等方面进行的。
在实际的工作中,经常存在模型刚上线一段时间,坏样本不充足的情况,此时做模型优化,需要把精力放在如何获取坏客户上,我们常遇到的解决办法是找类似的场景去扩充坏样本,对于上线时间较长的其他场景的逾期客户在进行迁移率分析、进行客户分布重合度的验证后是否可以进行坏样本扩充。
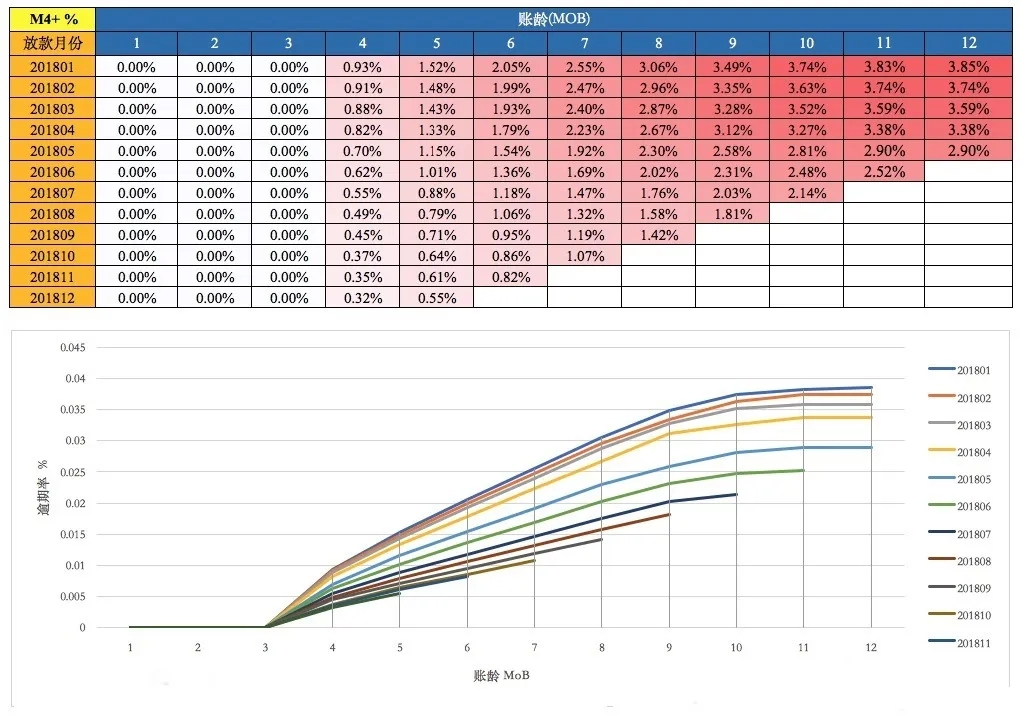
在好坏样本定义和样本提取之后,需要查看我们样本在当前模型的表现,也就是在样本上通过变量取值回测模型规则、评分以及额度策略等等,针对好坏样本表现分布,结合前期调整要求,比如变量阈值、额度参数等等这种简单层面的,最后将调整后的结果和之前进行对比、评估,在评估阶段主要是从模型优化前后效果比对和风险分析方面。
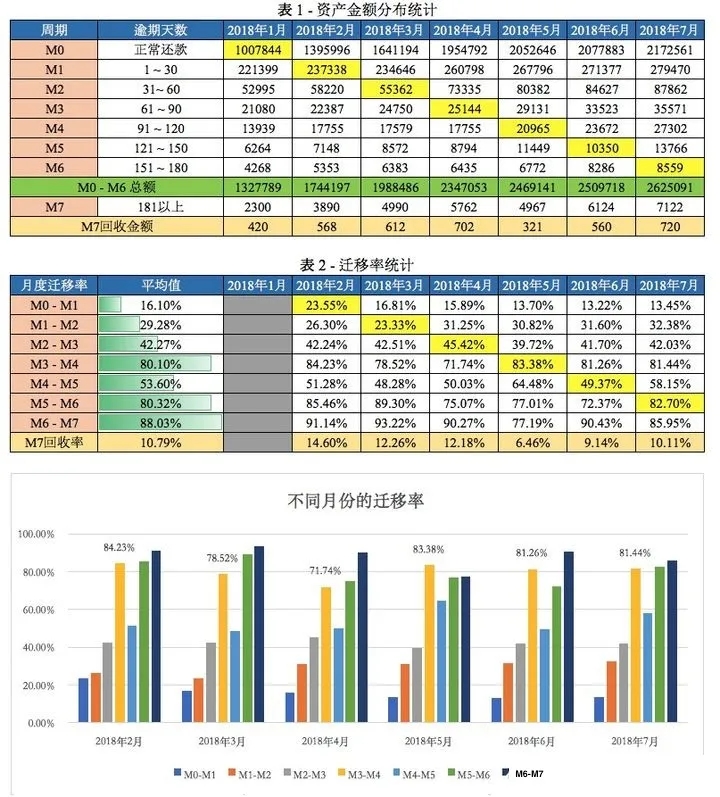
风险方面比如采用紧的变量调整方法,也就是控制坏客户的进入,可能造成的客户申请通过率低贷款放不出去,可能是业务无法接受的,如若采用松的变量调整方法,放进了大量客户而导致坏客户的进入以至于逾期率、不良率上升的风险,在实际的调整过程中需要和业务端共同协调来定,完成所有流程后撰写优化报告以及测试报告就算完成了一次简单的模型优化。
05 机器学习在智能风控上的应用
其实,机器学习算法在银行的应用越来越广,分类、聚类、关联等都可能用到,也会用到神经网络、深度学习、图算法等。
从应用方向上看,主要分为四类,分别是客户管理、精准营销、智能风控和运营管理。在四类应用方向中,客户管理是基础,通过机器学习可以实现精细化客户管理,在此基础之上,可以对精准营销、智能风控等进行赋能。
我主要说一下智能风控方面的应用,一般银行对智能风控的应用体现在互联网信贷上,如何识别、预测“坏客户”是重中之重。一般分为三大关卡:准入端、模型端、授信端,针对不同关卡设置不同的规则、模型、策略。
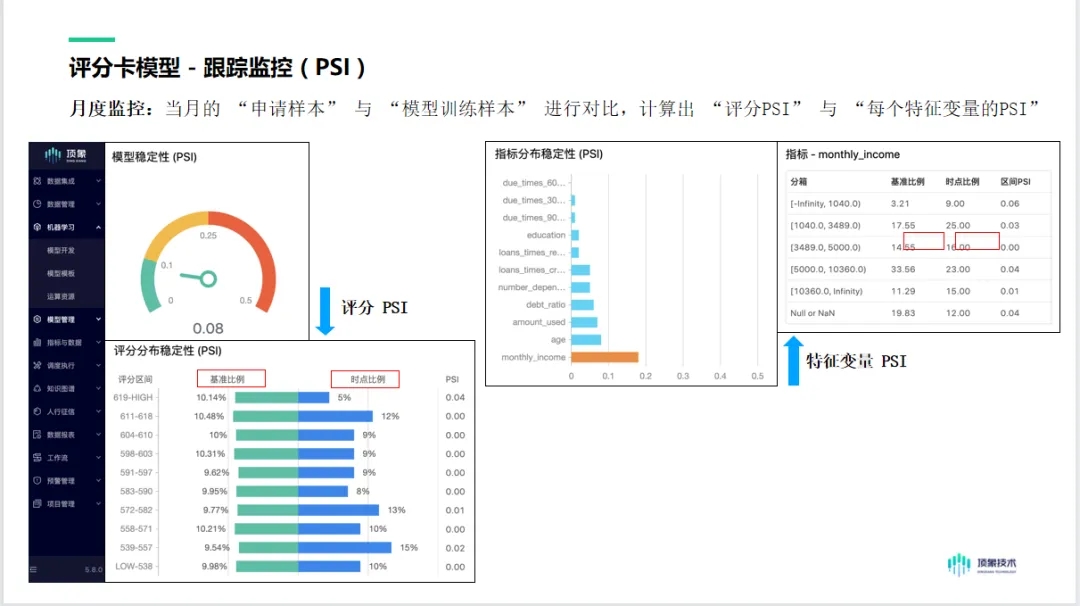
其中用到的机器学习模型主要体现在评分卡模型以及各种分类预测算法,传统的评分卡模型为了追求解释性主要采用逻辑回归,也就是一种复杂特征工程与一种简单模型结合的方法,然而现在为了增加预测精度更多结合一些先进算法来挖掘更多潜在风险,近几年,对团伙以及关联关系的挖掘也层出不穷,图算法也是比较热门的算法之一,我们项目中也在用,在与传统的算法比较中也有比较突出的效果。
机器学习算法在银行数字化转型的背景下越来越普遍的应用在各个业务场景中,神经网络、深度学习的算法也不断的被引用。
抓住机遇,狠狠提升自己
随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论、商业模型、SQL,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。

CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330